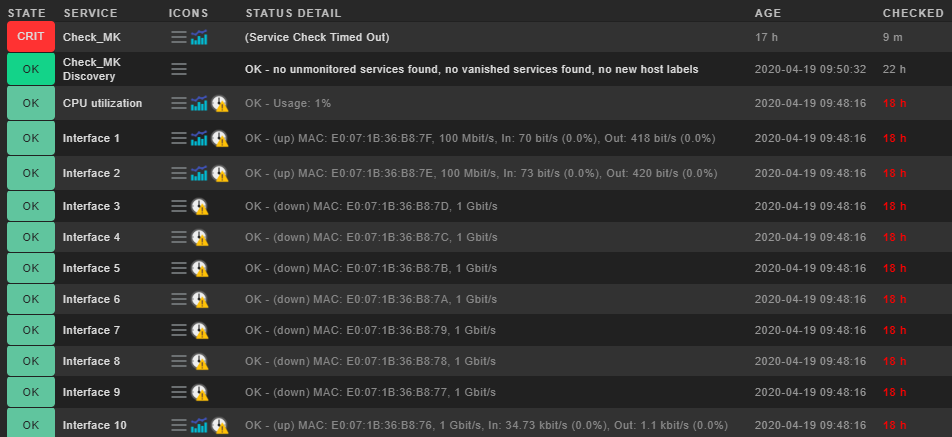
Hallo Andreas, diesen Output bekomme ich jetzt bei Ausführung der Kommandos auf dem zugehörigen Slave…
OMD[pekk]:~$ cmk --check-discovery xxx.20.52.xx
OK - no unmonitored services found, no vanished services found, no new host labels
OMD[pekk]:~$ cmk --debug vvl xxx.20.52.xx
OK - execution time 0.0 sec | execution_time=0.017 user_time=0.010 system_time=0.010 children_user_time=0.000 children_system_time=0.000 cmk_time_agent=0.001
OMD[pekk]:~$ cmk --debug vvn xxx.20.52.xx
OK - execution time 0.0 sec | execution_time=0.017 user_time=0.010 system_time=0.000 children_user_time=0.000 children_system_time=0.000 cmk_time_agent=0.001
OMD[pekk]:~$ cmk -D xxx.20.52.xx
xxx.20.52.xx
Addresses: xxx.20.52.xx
Tags: [address_family:ip-v4-only], [agent:no-agent], [criticality:prod], [if_by_alias_by_desc:if_alias], [ip-v4:ip-v4], [networking:lan], [piggyback:auto-piggyback], [site:pekk], [snmp:snmp], [snmp_ds:snmp-v1]
Labels: [system:switch]
Host groups: PKD-SWITCHES
Contact groups: all, check-mk-notify
Agent mode: No agent
Type of agent:
SNMP (Community: ‘public’, Bulk walk: no, Port: 161, Inline: no)
Process piggyback data from /omd/sites/pekk/tmp/check_mk/piggyback/172.20.52.11
Services:
checktype item params description groups
hp_procurve_cpu None (80.0, 90.0) CPU utilization
if 1 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 1
if 10 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 10
if 2 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 2
if 3 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 3
if 4 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 4
if 5 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 5
if 6 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 6
if 7 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 7
if 8 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 8
if 9 {‘state’: None, ‘errors’: (0.01, 0.1), ‘speed’: None, ‘unit’: ‘bit’} Interface 9
if DEFAULT_VLAN {‘state’: [u’1’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface DEFAULT_VLAN
if Switch loopback interface 4324 {‘state’: [u’1’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4324
if Switch loopback interface 4325 {‘state’: [u’2’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4325
if Switch loopback interface 4326 {‘state’: [u’2’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4326
if Switch loopback interface 4327 {‘state’: [u’2’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4327
if Switch loopback interface 4328 {‘state’: [u’2’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4328
if Switch loopback interface 4329 {‘state’: [u’2’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4329
if Switch loopback interface 4330 {‘state’: [u’2’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4330
if Switch loopback interface 4331 {‘state’: [u’2’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface Switch loopback interface 4331
if VLAN11 {‘state’: [u’1’], ‘errors’: (0.01, 0.1), ‘speed’: 0, ‘unit’: ‘bit’} Interface VLAN11
hp_procurve_mem {‘levels’: (‘perc_used’, (80.0, 90.0))} Memory
snmp_info None None SNMP Info
hp_procurve_sensors 1 None Sensor 1
hp_procurve_sensors 2 None Sensor 2
hp_webmgmt_status 1 None Status 1
snmp_uptime None {} Uptime