NetApp monitoring with API runs into timeout problems. On the commandline the check always runs fine with “cmk -v hostname”, but it will usually take slightly longer than 60s.
So I added rules to increase the following settings:
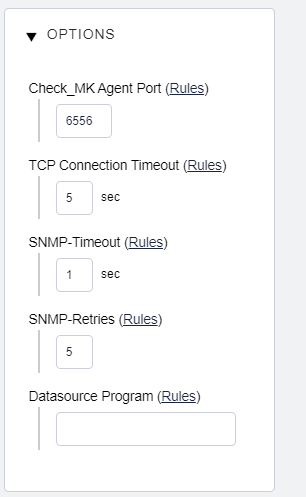
Parameters: Access to agents: Agent TCP connect timeout: 170 s
Service normal/retry check interval 180 s / 180 s
However, this still seems to run into a 60 s timeout most of the time, except for rare occasions when the filer happens to respond quicker than 60 s.
In the details page for the Check_MK service check, I can see the following information:
Service check duration 60 s
So despite 3 minutes agent timeout and check interval, some setting still seems to set a hard limit to 60 s.
What further parameters might I be missing? What could still restrict this check to a timeout limit of 60 s?
Can you try to look into the netapp special agent and see if there is a specific timeout in the script ?!
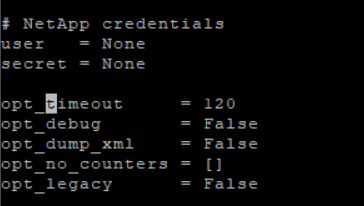
Indeed you can find a timeout=120 in the special agent
That’s a good point, but just like in your screenshot, the parameter is set to opt_timeout = 120 in my version of agent_netapp, too. And this agent is the same one that is called when the check is invoked from commandline with cmk -v filername, right? It works every time from the commandline, but the execution time in most cases is between 65 to 85 seconds.
So it works from the commandline and the hardcoded 120 second timeout in agent_netapp is no problem. But when scheduled by checkmk (raw, 1.6.0p6, nagios core), the check times out after 60 seconds and I couldn’t yet figure out where this 60 second limit comes from.
Any ideas why the scheduler/core/wato config might apply a 60 second timeout, which does not apply when running the check from commandline?
Oh indeed.
The timeout for tcp connections on the raw edition is fixed to 60sec.
To be honest I don’t know if you can hardcode this value to another since it will mess with the core.
On Enterprise besides changing the regular timeout you can configure a different timeout for tcp communication between the server and agent/datasource, I believe that your problem might be there.
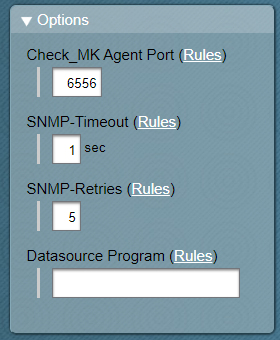
The parameter “TCP connection timout” is also available in 1.6.0p6 raw under “Access to agents” and I had already set that to 170 s for the storage systems.
But your notion that it might be related to the Nagios core in the raw edition pointed me in the right direction. It was a service check timeout parameter in the static part of the Nagios config, which is not generated dynamically by WATO.

{kind=link}