Hallo zusammen,
ich habe heute eine komplett neue Umgebung 1.6.0p10 aufgesetzt und wundere ich mich über Services die ständig stale gehen. z.B. “Check_MK Discovery”, “OMD prod_slave2 status” oder auch “Check_MK Agent”. Ich habe in einem anderen Thread gelesen, dass es bei der p10 diesbezüglich Probleme geben soll. Betrifft das jeden der die p10 nutzt, also kann ich sicher sein, dass es an diesem bekannten Problem liegt?
Gibt es bereits eine Lösung oder einen Workaround dafür?
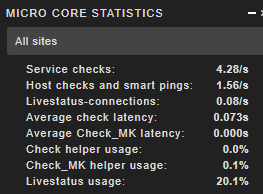
Die Statistiken sehen ja eigentlich gut aus:
Hi Tosch,
ist ja ein kompletter Neuaufbau… also zurückgehen geht nicht so einfach, muss dann erst mal eine p9 installieren. Aber da ich ein anderes Feature der p10 brauche… warte ich vielleicht erst mal ab.
Gibts da was offizielles von checmk zu?
Ich habe grade eine neue checkmk Umgebung initial aufgebaut, mit der p10.
D.h. ich müsste erst mal die p9 installieren, damit ich ein setversion machen kann.
Aktuell hab ich nur die p10 installiert:
root@xxx (cmk-prod) [/opt/cmk/bin]
# omd versions
1.6.0p10.cee (default)
Aber klar, das Installieren der p9 ist jetzt nicht so aufwändig. Ich schau mal was ich mache.
Danke
Hallo zusammen,
ich habe nochmal eine Frage zu stale Services. Nach einem Upgrade auf p11 sind die meisten Stale Services verschwunden. Was ich aber immer noch habe, sind sporadische stale services von der omd Selbstüberwachung. Ich habe distributed Monitoring im Einsatz, mit 4 Slaves und einem Master… und von den linux Agenten, die auf den 4 Slaves laufen, kommen sporadische stale Meldungen, die nach einer Minute direkt wieder verschwinden:
Hi @tosch,
danke, das hatte ich gesehen. Bei mir ist es nur gefühlt etwas anderes.
Bei mir gehen lediglich die OMD Status checks stale… und das auch immer nur alle paar Minuten für ein paar Sekunden.
Ich kann mir aber beim besten Willen nicht erklären, woran das liegen kann. In einer vergleichbaren Umgebung passiert das nicht…
Der Check Interval dieser Slaves ist hoffe ich 1 Minute oder?
Dies schaut sehr nach dem Fehler aus von hier Check chrony status stale
Checks welche selbst einen recht kurzen Cache Interval haben wie Chrony oder der OMD Site Status haben ein Problem wenn nur alle 5 Minuten abgefragt wird.
Da ist der Check dann scheinbar den System zu alt.
HI @andreas-doehler,
eigentlich ist alles default.
Der Check-Interval ist eine Minute und der staleness Wert in den Global Settings ist 1.5.
Ich habe auch eine andere p11 Umgebung, mit 2 Slaves, da habe ich das Problem nicht.
Ich finde auch keine Fehler in den Logs… und es ist immer nur der OMD Status Service. Ich hab jetzt nur noch einen reboot der Systeme als Idee… ansonsten bin ich ratlos. Wenn ich den staleness Wert auf 2.5 setze, wäre das Problem auch…sagen wir… umgangen
Aber gefallen tut mir das eigentlich nicht…ist ja nicht normal!
Zum Staleness Wert vertrete ich eh nach andere Meinung als die Default Values.
Mein Staleness auf den Systemen steht immer auf dem gleichen Wert wie mein “Maximum number of check attempts for service” da ich der Meinung bin (ist halt ne persönliche Erfahrung mit den vielen Systemen) wenn ein Service wirklich eine Notification erzeugt dann kann er auch als Stale im Dashboard erscheinen.
Fehlt da 1-2 mal ein Messwert dann ist das halt egal. Vor allem in richtig großen Systemen ist 1,5 als Staleness fast immer unbrauchbar da nach einem Core Neustart oder Cluster schwenk es immer 2-3 Minuten mindestens dauert bis sich alles wieder eingestellt hat.
Moin,
okay… dann wird mich das Thema eh nochmal einholen.
Wir migrieren grade 350 AIX und Anfang nächstes Jahr 4000 Linux-Systeme nach checkmk… insofern werde ich den Wert dann vermutlich eh noch nach oben schrauben.
Dann ignoriere ich das jetzt einfach erst mal
ich muss hier nochmal kurz einhaken - was setzt du dann genau als Wert. Ich habe z.B. max.
check attempts for service = 3. Wäre dann der Staleness Wert auch 3? Habe ich das richtig
verstanden?
Ja so mache ich das. Staleness steht mindestens auf dem Wert welcher als Default für die max check attempts steht.
Das hat wieder den Hintergrund. Für Auswertungen sind ja meist auch nur Hard States relevant. Genau so sehe ich das halt auch mit nem Stale der für mich nur relevant ist sobald er den “virtuellen” Hardstate erreicht wie bei einem Fehler.