Hi there, is that anyway to disable NTP warning alert in Checkmk2.0
Thank you
Are you talking about the service of a host? You can turn off notifications for that service (for example). I guess I’m saying that maybe we need more information (?)
Hi, I am talking about NTP alert like this:
host: SAM-APP-03 host_address: 182.20.150.3 info: Offset: 0.0786 ms, Stratum: 3, Time since last sync: 30 minutes 53 seconds (warn/crit at 30 minutes 0 seconds/1 hour 0 minutes)(!)
Yes, for this you can create a rule to disable the notifications (for example, just select the menu of the service (any of the NTP ones) and create a preference for the service rule to disable the notification, or however you want to handle this). Of course, you could also just fully disable the service altogether if you want.
1 Like
Thank you for your help. I will take a look that
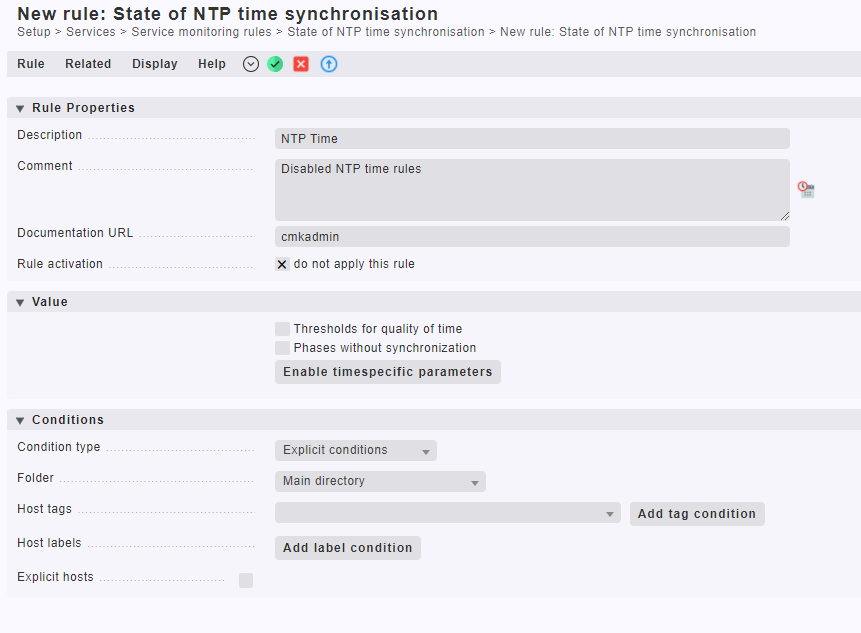
Two things:
- Do not just disable notifications without understanding them!
- You found the right rule to tweak the NTP checks. Look at the configuration and configure it to fit your needs. Keep in mind that proper time synchronization is essential and you should not just silence your monitoring but fix the underlying issue if there is one.
5 Likes
Just looking for a bit of background as I’ve only recently started getting these NTP alerts for “Time since last sync” and needed to make the same change as @rickyt
“Time since last sync” this a new check added in NTP agent on a recent Check_MK 2.0 p? or has my NTP client (chronyd) changed in some way?
Thanks
Andy
I am not certain when that distinct item was added to the NTP check, but NTP in general and the chrony daemon in particular haven been supported for quite some time now. Of course, you can tweak the settings, but if no synchronization is possible, that generally has a reason and should be investigated.
I’m also noticing a lot of NTP stale info since I migrated from 1.6 to 2.0. Not to hijack this thread, but I think there’s a bug somewhere in Checkmk (running 2.0.0p16 CRE here).
This is the output of the agent (ubuntu node):
<<chrony:cached(1638645148,30)>>
Reference ID : C200057B (194.0.5.123)
Stratum : 3
Ref time (UTC) : Sat Dec 04 19:01:45 2021
System time : 0.000026125 seconds slow of NTP time
Last offset : -0.000039710 seconds
RMS offset : 0.000092087 seconds
Frequency : 45.778 ppm slow
Residual freq : -0.002 ppm
Skew : 0.086 ppm
Root delay : 0.009361028 seconds
Root dispersion : 0.004549814 seconds
Update interval : 1042.8 seconds
Leap status : Normal
The local timestamp on the node is
$ date +%s
1638645242
I don’t see any output in chrony that shows the last synchronized time, but still somehow Checkmk is throwing the error/warning for example:
Offset: 0.0195 ms, Stratum: 3, Time since last sync: 1 hour 1 minute (warn/crit at 1 hour 0 minutes/2 hours 0 minutes)WARN.
Stale chrony services can occur due to custom check intervals for the Check_MK service. Make sure that it is 1 minute, and you should get rid of those stale services.
I think the Update interval in your output might be the reference for the last sync, but I did not verify that.
Thanks Robin
I followed your advised and it works. Much appreciate it
The “Update interval” comes directly from the output of “chronyc -n tracking” called by the agent and refers to the next sync, not the previous one. It is telling us explicitly that chrony is not going to update until that interval passes. I ran a script last night to print out the “Update interval” lines whenever they changed. Sure enough, one line said “Update interval : 2069.0 seconds” and then 30 minutes later (1800 seconds) got an alert, and 4-5 minutes after that (2069 - 1800 = 269 seconds) the alert cleared. (All other values collected were between 1020 and 1050 seconds.)
So really the check could alert you to the “problem” 30 minutes earlier if it was looking at the “Update interval” rather than the “Ref time”. All of this makes me wonder, is this in fact a chrony error or is it a misunderstanding of chrony’s standard operating procedure? To me that part of the check does not appear well thought out.
I’m sorry, I misread my own notes, the Update Interval is indeed showing the past value.
The default Chrony config for “maxpoll” is 10. But that 10 is really the exponent of 2, so the default maximum polling time is somewhere in the range of 2^10 or 1024 seconds, around 17 minutes. I haven’t figured out the “why” yet, but occasionally Chrony bumps up the maxpoll value by 1 making the new interval in the neighborhood of 2048 seconds, or a little over 34 minutes.
To quiet things down we can either increase the WARN alert time to 36 minutes, or change the Chrony “maxpoll” to 9, so when Chrony does that weird bump-up it will still be within the check_mk OK time period.
If someone is truly relying on super-precise system clocks all of these settings are way too big.
I’m going to change my maxpoll to 9 and see how my interval numbers change.
2 Likes
Thanks for the extensive information, @FrankJ!
I will pass this information on, to make sure we take another look at the plugin and decide what can be improved.
Hallo,
we ve similar problems with ntp.
In our case it seems that only centos7 are affected.
Ralf
Hey @FrankJ and everyone, I am also seeing the NTP last sync alerts across my RHEL8.5 deployment which is configured to use chronyd. I tried setting maxpoll to 9 (8.5mins) but was still seeing last sync values greater than 60mins. Did you figure out what was going on with chrony and it’s last sync value? Thanks!
any updates on this? we are also facing same issue centos7 chrony
I never managed to understand why chrony kept self-delaying. I dropped my maxpoll to 8 on my main box, and 7 on the rest, which all sync to my main server. Very few complaints since.
I tracked down the problem to the Linux Agent and the variable MK_RUN_ASYNC_PARTS set in the systemctl service file
# grep ASYNC /etc/systemd/system/check_mk@.service
Environment="MK_RUN_ASYNC_PARTS=false"
The behaviour is
-
chrony.cachefile is outdated long time ago. - opening a connection to port 6556 runs fine but it does not update the
chrony.cachefile. - Running manually the Linux Agent does update the
chrony.cachefile and therefore the alert is cleared.
I guess the following part of the run_cached function in the Linux Agent ends before reach the last lines because of the value of the MK_RUN_ASYNC_PARTS variable.
$MK_RUN_ASYNC_PARTS || return
# Cache file outdated and new job not yet running? Start it
if [ -z "$USE_CACHEFILE" ] && [ ! -e "$CACHEFILE.new" ]; then
# When the command fails, the output is throws away ignored
if [ $mrpe -eq 1 ]; then
echo "set -o noclobber ; exec > \"$CACHEFILE.new\" || exit 1 ; run_mrpe $NAME \"$CMDLINE\" && mv \"$CACHEFILE.new\" \"$CACHEFILE\" || rm -f \"$CACHEFILE\" \"$CACHEFILE.new\"" | nohup /bin/bash >/dev/null 2>&1 &
else
echo "set -o noclobber ; exec > \"$CACHEFILE.new\" || exit 1 ; $CMDLINE && mv \"$CACHEFILE.new\" \"$CACHEFILE\" || rm -f \"$CACHEFILE\" \"$CACHEFILE.new\"" | nohup /bin/bash >/dev/null 2>&1 &
fi
fi
Test:
# date
Mon Mar 27 15:00:32 CEST 2023
# ll /var/lib/check_mk_agent/cache/chrony.cache
-rw------- 1 root root 497 Mar 27 11:25 /var/lib/check_mk_agent/cache/chrony.cache
# export MK_RUN_ASYNC_PARTS=false
# check_mk_agent >/dev/null 2>&1
# ll /var/lib/check_mk_agent/cache/chrony.cache
-rw------- 1 root root 497 Mar 27 11:25 /var/lib/check_mk_agent/cache/chrony.cache
# unset MK_RUN_ASYNC_PARTS
# check_mk_agent >/dev/null 2>&1
# ll /var/lib/check_mk_agent/cache/chrony.cache
-rw------- 1 root root 497 Mar 27 15:02 /var/lib/check_mk_agent/cache/chrony.cache
Best regards
1 Like