Ich habe hier seit dem Update von p1 auf p2 Lastprobleme, die mich an ein ähnliches Problem erinnern dass es mal mit der 1.6 am Anfang gab.
Bei mir sind drei Sites betroffen. Dort habe ich ein Loadaverage um die 10 und “OMD perfomace” sagt die Site würde nicht laufen und “Site statistics” sagt “Item not found in monitoring data”.
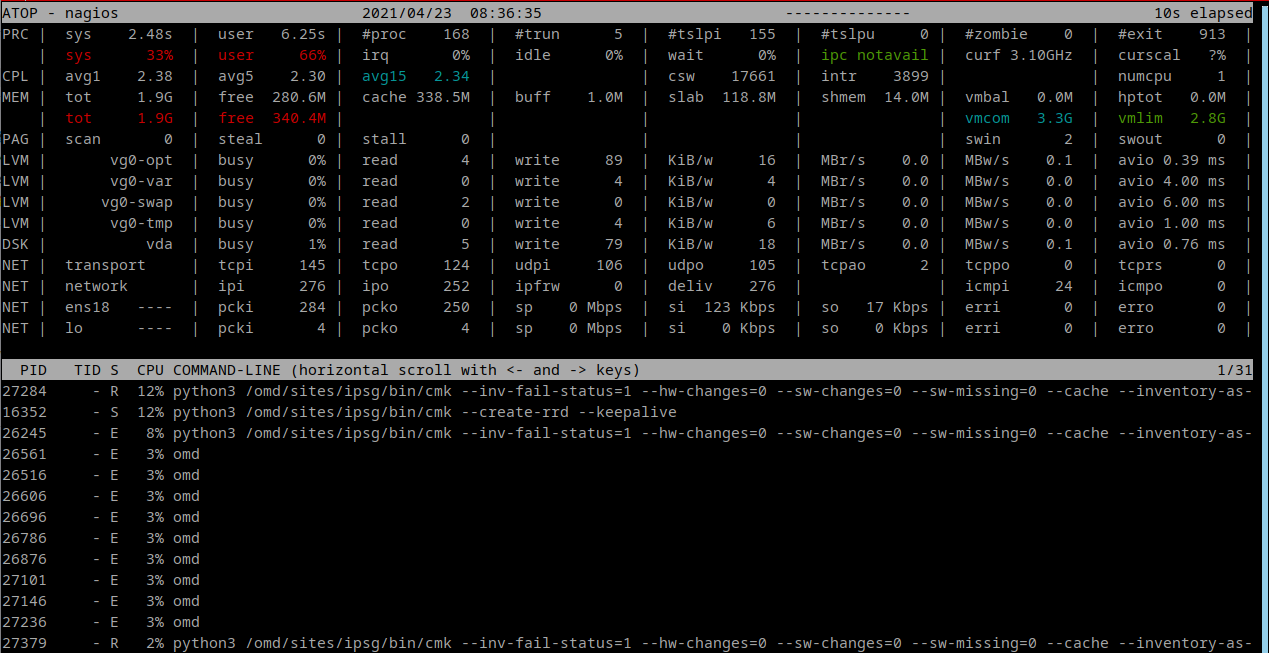
Meist ist aber ein Prozess dabei bei dem Atop in der Commandline nur “python” anzeigt und sonst nix weiter dahinter. Dem Swap nach zu urteilen könnte das auch ein Memoryleck sein.
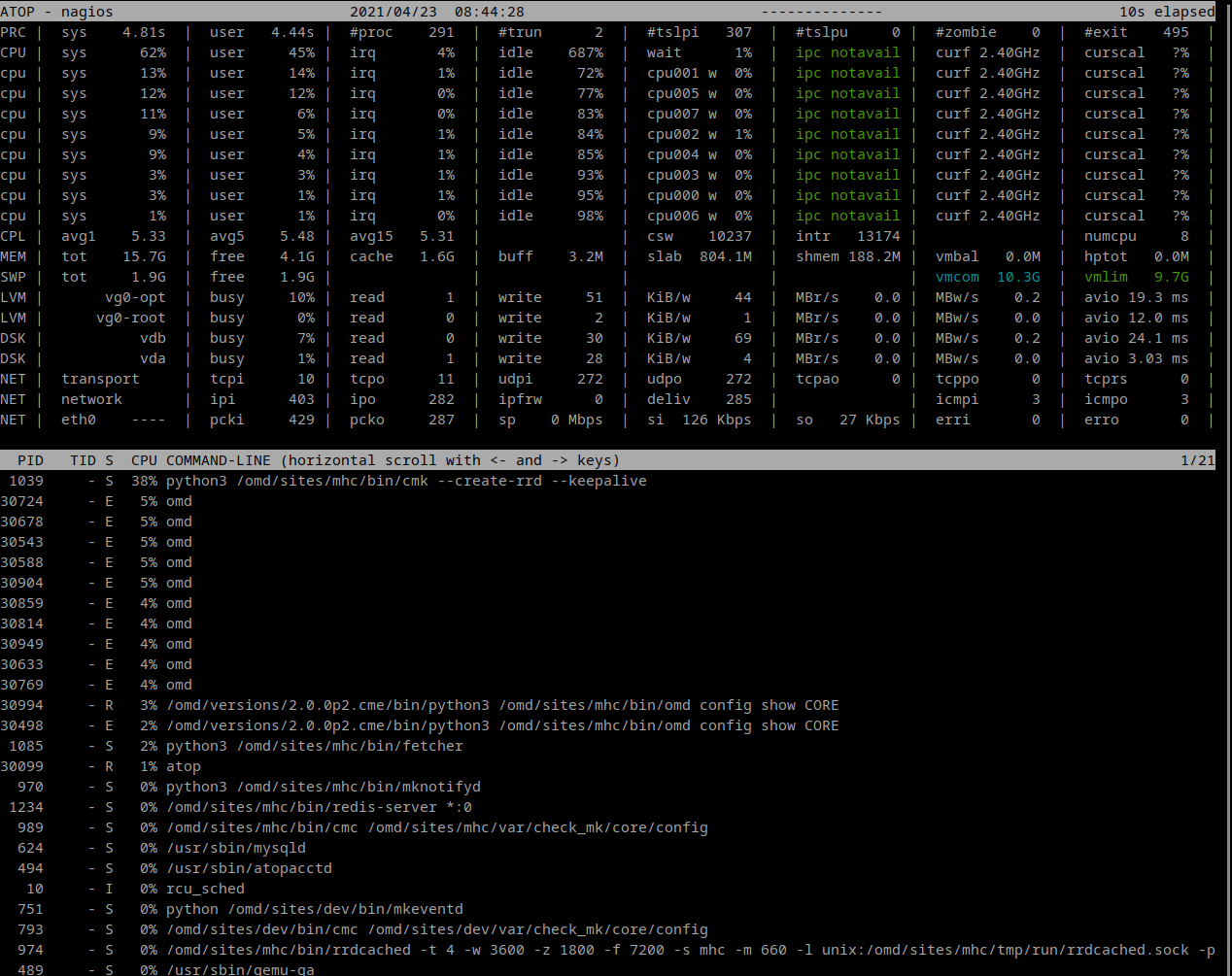
Hier noch ein zweites Beispiel. Das ist bei mir intern und ich hab der VM jetzt schon 8 Cores und 16 GB Ram gegeben …
Ich würde mir ja als erstes Gedanken machen was die komischen “omd” Prozesse da machen?
Die sind seltsam. Die gibts in meinen Systemen nicht.
Eine Single Core Maschine wie im Bild 1 ist immer schlecht da hier ein Problemprozess gleich alles lahm legen kann.
Ich würde hier mir mal das Core Log anschauen ob der ein Problem hat RRD Daten ordentlich zu schreiben oder irgendwas anderes da faul ist. War ja auch in deinem atop output ganz oben.
Aber dort sieht man nicht wie viel Zeit der Prozess schon vertan hat.
Es gibt endlos viele Einträge der Art für alle möglichen Devices und Services:
Error creating RRD for pnp_multiple;xxxx.xxx.xxx;Interface eth3;indisc;0: Tried to create /opt/omd/sites/mhc/var/pnp4nagios/perfdata/xxxx.xxx.xxx/Interface_eth3_indisc.rrd, but this RRD exists.
Es fehlen auch “jede Menge” Grafiken … dem habe ich aber erst mal keine Bedeutung beigemessen, weil ich das immer mal wieder habe/hatte.
Oh eine Enterprise Edition mit alten Graphen welche nicht nach CMC migriert wurden.
Update auf p3 könnte hier schon helfen - ansonsten erstmal alle Graphen nach CMC migrieren.
Werk 12298 2.0.0p3 2021-04-16 09:37:41 Bug fix Prominent change Compatible Livestatus Raw edition: Fix “No historic metrics recorded…”
Über längere Zeit sehe ich nur, dass es zwar besser ist aber noch lange nicht gut. Haupt Problem scheint die Platten IO des cmk Servers zu sein. Ausserdem sehe ich so etwas im log:
Error creating RRD for pnp_multiple;kopano.mhc.loc;Interface lo;inmcast;0: Tried to create /opt/omd/sites/XXX/var/pnp4nagios/perfdata/XXXX.XXXX.XXX/Interface_lo_inmcast.rrd, but this RRD exists.
[rrdcached at "/omd/sites/xxx/tmp/run/rrdcached.sock"] queue full, didn't push update
was hat den das “convert-rrds” ausgegeben? Vorher auch die RRD Regeln in der Konfiguration kontrolliert oder angepasst?
Hab das gerade heute bei einer Enterprise Site gemacht wo alle Graphen noch im PNP4Nagios Format vorlagen und ging. Das “–convert-rrds” kann man auch mehrmals machen müssen im ungünstigsten Fall.
Die Ausgabe war X Mal “Error” … Steht das irgend wo beschrieben? Was müssen denn für RRD-Regeln angepasst werden? Und vor allem: warum macht das das Update nicht?
Weil das Update nicht einfach diese Einstellungen ändern sollte. Da man hier zu viele Edge-cases hat welche das Update auch nicht von allein beheben kann.
Bei den Error Meldungen steht eigentlich immer dabei was kaputt ist und was zu machen ist.
Das Bild ist aber an sich uneinheitlich. Die, die hier als “Error” ausgeworfen werden sind sind Hosts für die des keine Services gibt, also nur ein Ping ausgeführt wird. Es zeigt sich, dass für alle Services Graphen da sind nur für Ping nicht. Nirgends. Starte ich das mit “-v” dann wird auch nur “Error:” ausgegeben. Weiterhin zeigt sich, dass das “convert” nicht nötig ist. Es gibt auf allen Sites für alle Services Graphen, allerdings NRIGENDS für Ping. Die fehlen alle.
Es gab übrigens gar keine RRD-Rule bei mir, die anzupassen gewesen wäre. Ich habe jetzt eine angelegt.
Das ist ja eigentlich egal in Version 2 benutzt man eh die Regelsuche am besten
Ping ist genau so ein Edge Case. Es ist hier relevant ob der Ping als Hostcheck interpretiert wird oder nicht.
Deshalb solche Commands immer mit “–debug -vv”, so wenig Fehlermeldung wie in deinem Fall also nur rote “ERROR” hab ich noch nie gesehen.
Heute grad wieder bei einem System gemacht und ging ohne Probleme.
Da ist das Problem. Die Regel hätte eigentlich schon im 1.6er System angelegt werden müssen.
Es ist ein Hostcheck. Zumindest habe ich eine Hostcheck-Rule dafür. Ich wüsste gar nicht dass das anders geht. Das betrifft halt alle ob SNMP, Agent oder “no agent / no SNMP”, also eben nur Ping.
Auch -vv bringt nur “ERROR:” bei denen die “no agent / no SNMP” haben. Die mit SNMP oder Agent liefern keinen Error aber eben auch keinen Ping-Graph.
Ganz einfach es kann halt Hostcheck sein oder ein normaler aktiver Check.
Oder es kann Hostcheck und aktiver Check sein auf dem gleichen Host.
Genau diese Hosts haben dann im dümmsten Fall einen Ping Check welcher als aktiver Check sichtbar ist sowie noch einen Host Check Ping falls nicht SmartPing benutzt wird.
Einfach mal schauen was für RRD Files den bei diesen Hosts vorhanden sind dann dürfte klar sein was hier eigentlich passiert.
Hier ein Beispiel
Host ohne Agent und ohne SNMP
Ping der einzige “echte” Service
 Mit der 1.6 lief das alles völlig problemlos.
Mit der 1.6 lief das alles völlig problemlos.