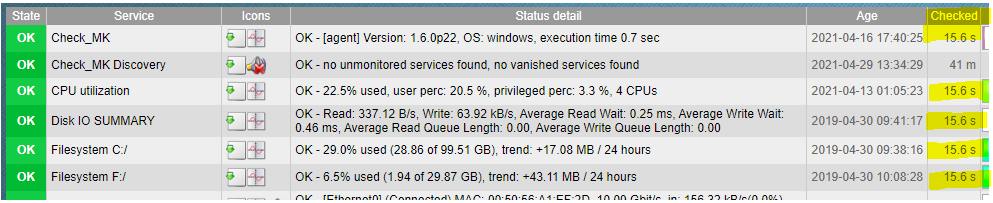
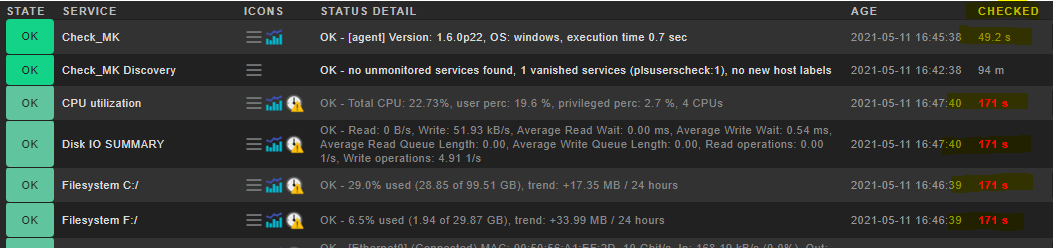
Hello - we have a CMC 1.6.0 server instance built from scratch monitoring around 6k services on 300 hosts. I noticed that around 150 to 250 services are consistently stale. When I drill into the hosts, I see a breakdown similar to this:
How do I go about troubleshooting this? If the remote agent is returning data in 2 seconds, why have the local passive checks not updated for 4 minutes? This doesn’t make any sense to me but perhaps I’m thinking about the flow wrongly. Some of these hosts do have a large number of services on them, but I see no cpu or load issues on the server which would indicate why the data is taking so long to process once its sent back to the server.
Any pointers on how to proceed would be appreciated.
There are two important numbers - the check interval of your Check_MK service (normally 1 minute) and the value for staleness in your global settings (default 1,5). A service is shown stale if no check results are arrive in the given interval. In your case the agent looks like working normal but you get no valid information for CPU utilization and Disk IO. That can have many different reasons. As booth values are fetched as performance counters i would say it is very likely that you have a problem on your Windows server with the performance counters. First step i would test is update the agent on this machine to 1.6.
Additionally, check the amount of check helper usage. If you resources on cmk server ale less, you will see this value over 90%. Normal is a value at 80%. This can be also be a cause of stale services.
If you have enough system resources, you can increase the settings in “Global settings”.
Cheers,
Christian
Thanks for both of your feedback, I’ll check these settings.
We have another server running 1.5 which is why I’ve been reluctant to migrate any actual agents to 1.6 (I’m migrating from the 1.5 server to the 1.6 server manually since the 1.5 instance is all old-style config files) but I may not have a choice since we’re going to stop using the 1.5 server at some point anyways. Oddly enough, the 1.5 server typically shows only 3 - 5 stale services.
Hello - thanks again, some follow up questions. I picked one host with stale services and upgraded the local agent to v1.6. What I noticed is that on our 1.5 server instance, the update times for all services are basically the same:
On the 1.5 server, everytime the Check_MK service “Checked” would update, everything underneath it would update at the same moment. Sometimes this happens on our 1.6 server, but more often than not I see this:
So the Check_MK service would update and everything else (every single other service, I just cropped the image) would lag behind it, sometimes by whole minutes.
I tried testing the local agent itself (check_mk_agent.exe test) and testing from the server (cmk -d ) but I don’t see anything that would indicate issues with the data returned - nothing truncated, no errors, etc.
From what I can see, both of our server instances have the same factory settings for staleness, check intervals, concurrent checks and helpers, etc. (oddly enough, on both servers, the helper usage is almost non-existent, basically 0.1%)
Apologies if I’m thinking about this wrong, but if the Check_MK service itself returns data, shouldn’t all of the services using that data update more or less immediately? Is there any additional debugging or logging you would recommend so I can figure out what might be throwing the 1.6 instance off?
Quick update - I’ve made some progress here. The issue doesn’t appear to be the above at all, but rather something with the custom python plugins that we’ve written. We have a bunch of these, and some are quite old and pre-date our upgrade to v1.5. I noticed that if I removed the local check from the Windows server (so that the server agent code is not called) the stale problems go away and the v1.6 server output looks like the v1.5 server output. Unfortunately at the moment, I don’t really know why and I don’t know why this doesn’t happen consistently with every single custom plugin across every machine. Everytime I try to troubleshoot (using cmk -nv for example) everything looks fine.
SO … one question. I guess need to update these to follow better coding guidelines and be cleaner overall. I noticed things changed significantly with v2.0 with regards to custom plugins (and the documentation is more complete) so I think it might make sense to move to 2.0 and only have to recode these once. Do you think that makes sense or are there some other steps I can take with things as they are now?
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.