We have a request to monitor a number of hosts that will reboot randomly during the day or at night and we should NOT alert on this.
What would be the best way to do this?
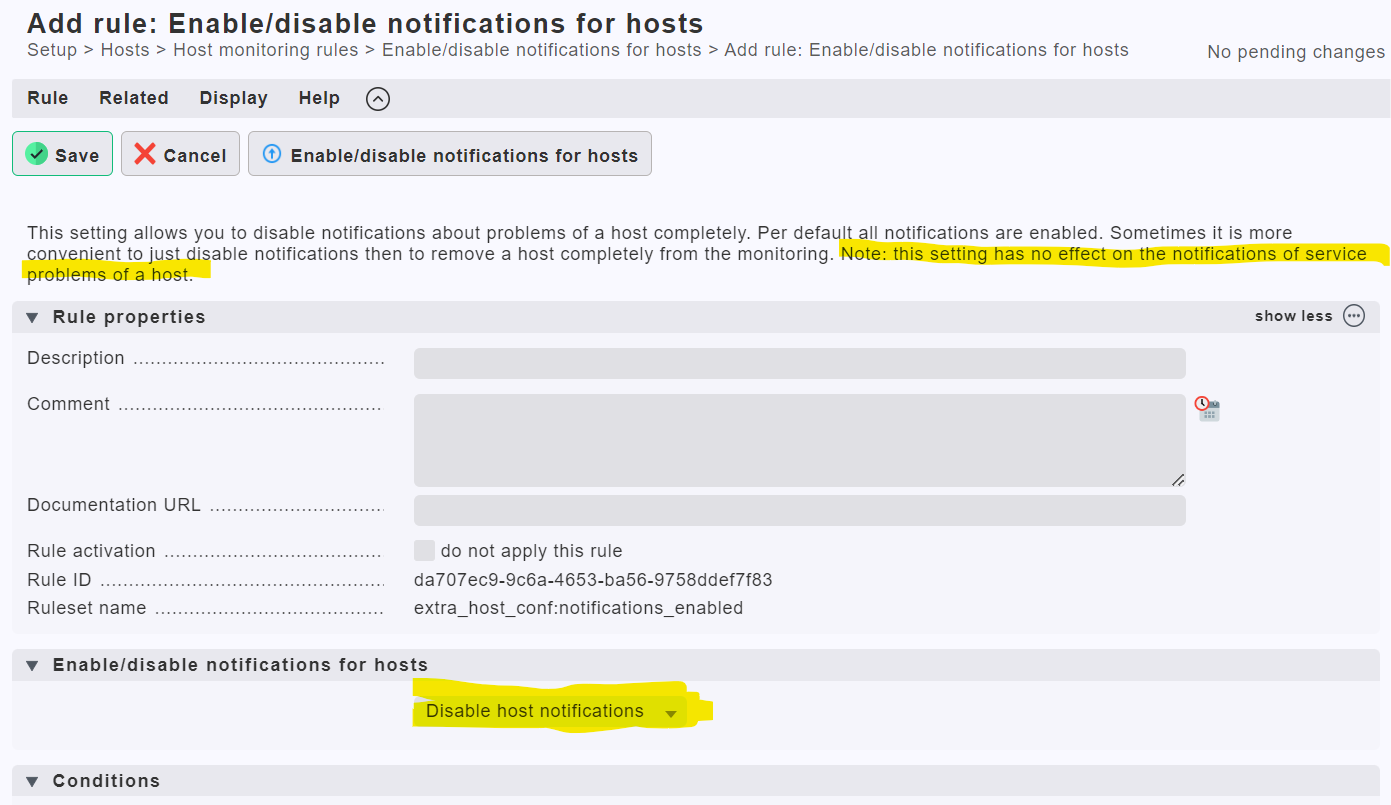
I know we could maybe negate notifications for these hosts but then that would stop all notifications.
We will want to alert on the other services.
you could write a powershell / bash script that is being triggered with the reboot from the underlying os that sets a downtime in checkmk through the REST API.
Or if the reboot is orchestrated by another tool, the tool could also set downtimes in checkmk via scripts or REST calls.
If that is to complex and there is no other indicator when the downtime is triggered, you could just raise the nr. of check attempts for the host checks.
We know of Checkmk users that schedule a 10 minute scheduled downtime from 7:00 to 20:00 to allow their admins to perform any short maintenence during work hours. You might extend this to a 10 minute scheduled dowtime from 0:00 to 23:59 and will only get notified if the downtime covers midnight.
Edit: This will only work out of the box for a single reboot per day.
I think there are a few options here, depending on the desired behaviour and the specifics of your situation.
The simplest solution is probably to disable the host-level notifications for these hosts, but that assumes that you do not want to alert on host availability at all. Note that host notifications and service notifications are different, so you should be able to disable host notifications while retaining alerts for all of the host’s services.
If the requirement is to ignore downtime only if it is temporary because of a(n) (un)planned reboot, I think Andre’s suggestion of increasing the number of check attempts before Checkmk flags these hosts as down is probably the way to go.
Alternately, if you can be sure that there is no more than 1 reboot per day for any 1 of these hosts, Mattias’ suggestion of recurring scheduled downtimes may work.
There may be better options, but, if nothing else, you should be able to create a rule set to “Cancel previous notifications” (rather than the default “Create notification with the following parameters”), then, under Conditions, select Match host event type and match all host event types. Set additional conditions, as appropriate, to ensure you still get host event notifications for systems that require them.
Besides what was mentioned already, some alerting tools (e.g. SIGNL4) offer delayed notifications. So, if there was a temporary issue, like a server reboot but the server is up again after a few minutes you will not receive the wake-up call. Also, filtering for certain alert types can be found here.