I’ve tried just “Clustered services” first, which you already now what happens:
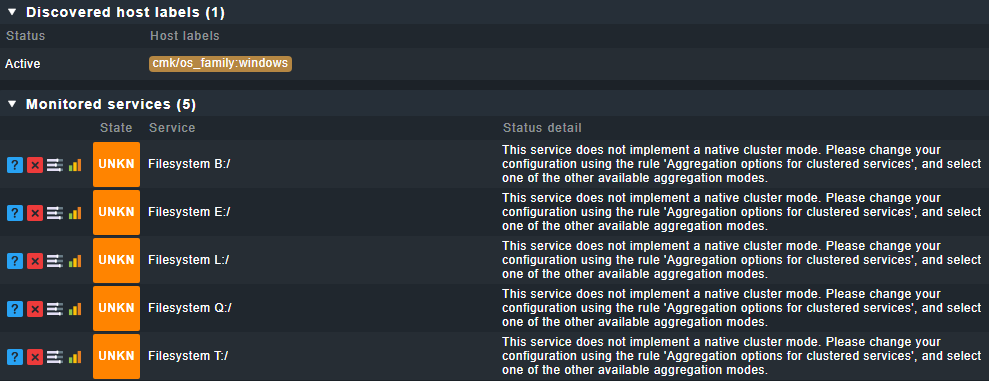
Filesystems appear perfectly, but with a “UNKNOWN” state, and that weird message about “native cluster is not supported for this kind of service, use aggregations”.
Well, i’ve tried aggregations, with Native, failover, best, worst.
All of them. No filesystem appears.
With 1.2.6, 1.4.0, it was so easy.
Guys, please, what are the exact steps to get it to work?
I can only shed background. For support, a community member would have to help.
But before 2.1, the behavior was in some cases not defined, leading to arbitrary results for clustered services. Therefore, now if a check does not have it natively implemented, you as a user need to make the conscious decision.
Make sure that the aggregation option rule applies to the services and hosts you want to cluster.
In the “Aggregation options for clustered services” rule, you can specify the aggregation mode for services without their own check-specific cluster function.
For FS, this would normally be “Worst Node wins”, since you want to be notified when an FS runs out of space.
Ok. I’ve done my testing.
What i’ve seen seems to be exactly what that capture from the presentation shows.
Failover. If i reboot the node with all the disks mounted, i get a WARNING, which is not pretty, until all is back online; then it shows all the disks on the other node. All OK.
Worst. Not pretty. Some disks turn to UNKNOWN until everything is back online.
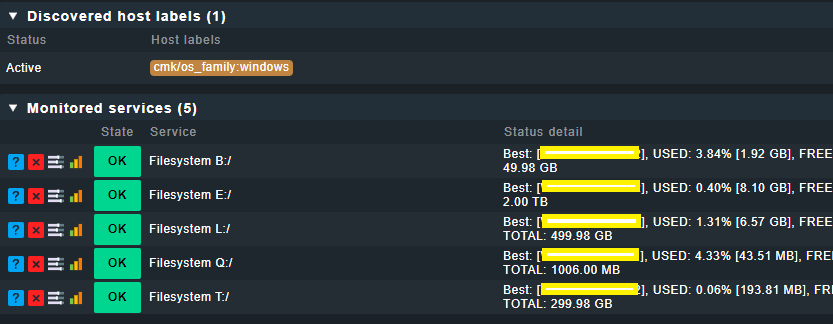
Best. This seems to be the best option. Always green. Never a warning or unknown.
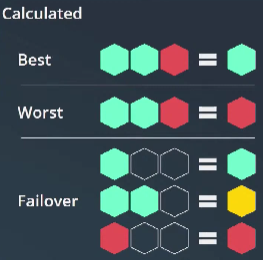
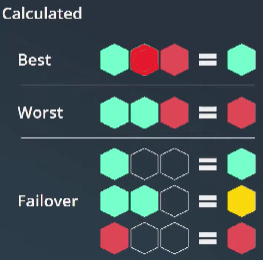
@gera83 you want to make sure, you understand what the modes actually do:
Failover expects one and only one node to provide data for a service.
Worst means, that as soon as one node experiences an issue, you will be notified.
Best means, as long as at least one node is fine, the clustered service is fine.
And the UNKN and WARN states you mention can be valid states. For Worst, the UNKN is correct, if the disks need to move to the other node. Because during that time, Checkmk receives no data. The same applies for Failover: If the disks are not online, or can be seen on both nodes, then you get a warning. This might actually not be what you are looking for, but it is certainly valid.
Just want to make sure you got the right solution.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.