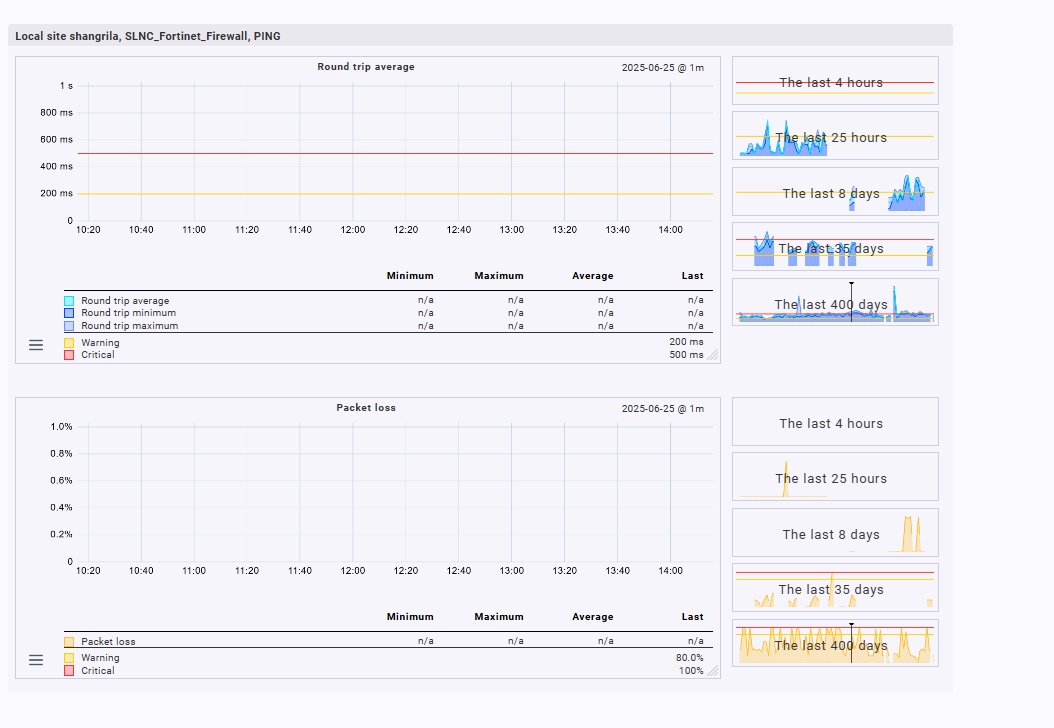
I am using checkmk version Enterprise edition 2.1.0 . Recently I notice that all the hosts (over 100 hosts) we monitor are in the “stale” state, showing the message “the service is in stale, no data has been received within the last 1.5 check periods”, is it normal or it’s a issue? And seems as a result that the Ping service graphs are not showing any volume for RTT and packet lost. Please help. Thanks
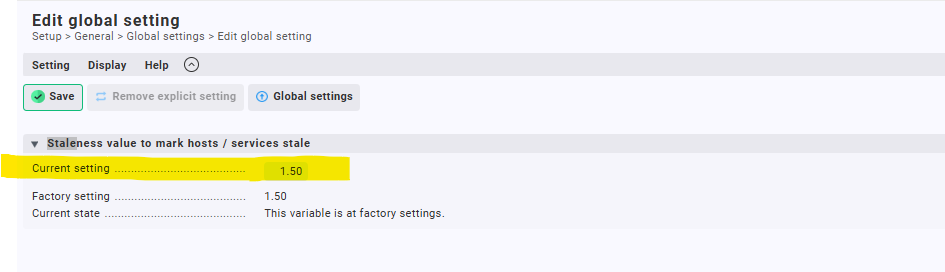
This factor multiplies with the checkinterval to determine the time before hosts/services become stale. If checkinterval for (specified) services is set to 60 seconds, a service is considered stale when there’s no up to date response in 90 seconds. For hosts check interval is default 6 seconds, so stale after 9 seconds.
It can be an issue.
You can check connectivity between Checkmk and hosts, time how long it takes agents / plugins to respond, and accordingly tweak the check interval and / or staleness value to give more time in your environment before it becomes stale.
Thanks. But what value should we change to? I mean if the checkmk system doesn’t have the machanism to turn off the "stale " state when the hosts/service come up again, No matter what value we set to, it would still stuck in the Stale state , right ?
As soon as hosts/services respond within the computed time frame, determined by staleness value and check interval, it will lose the stale state.
But what values to set check intervals and/or staleness value to, is depending what is considered normal it should respond within your environment.
I’m monitoring mostly endpoints. When users overloading their desktop, agents take more time to complete, will not respond in time and will cause hosts / services become stale.
And I don’t mind this happening.
I can’t advice you what to set it to for servers and such.
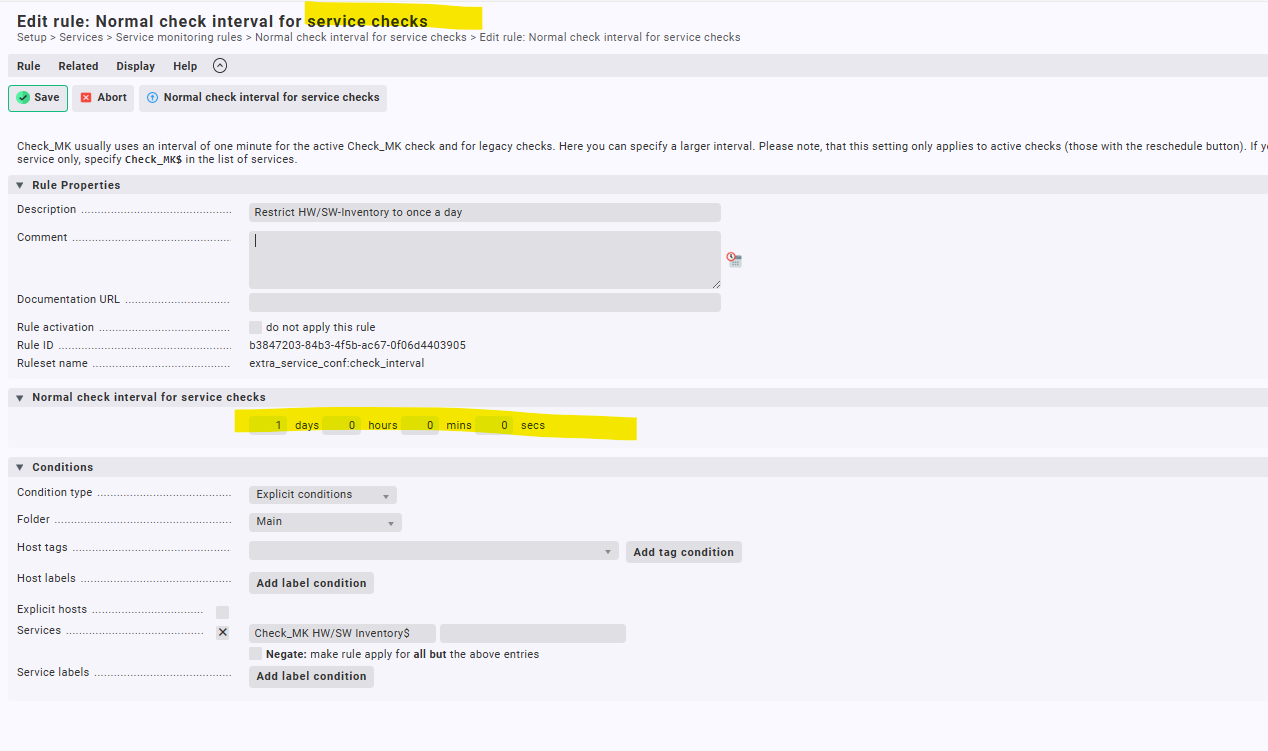
Regarding your rule for check interval of HW/SW inventory, it is a time consuming plugin which you don’t want to run too often. Once a day would probably be fine.
— So if most of services are in Stale state, what is the impact? will there be any issue or anything not function ? Will the email notification still work ? Thanks
Also, because most of our hosts’s services are in stale, and the hosts are switches and firewalls but not desktop, and the services are just normal Ping. how could that possible the most hosts are not responding to ping with the check interval, I don’t quite understand.
It used to no issue but all the sudden , this Stale thing came up.
I tried ping from the LInux CLI to the host is successful, so there is no network issue here.
The impact could be that you don’t meet SLAs, or hosts need better hardware/software.
I’m mostly monitoring to keep a general overview of our network. I’m the complete IT department in our company. I’m currently less worried about timings and such.
Maybe others can advice you better how to debug and set the right values for your environment.