Hallo,
ich habe eine Appliance laufen die gerne mal abschmiert.
In meiner Master-Site sehe ich in den Logiles der Appliance diverse Memory-Probleme.
Eine der Sites überwacht unsere Docker/ Kubernetes Umgebung die ziemlich dynamisch ist und viele Änderungen verursacht.
Die Appliance läuft auf der Fimware 15, die Sites auf 2.0.7
Die VM hat 32 GB Ram und das Filesystem ist unverändert.
hat jemand Tips wo ich noch mal suchen sollte?
Gruß
Ralf
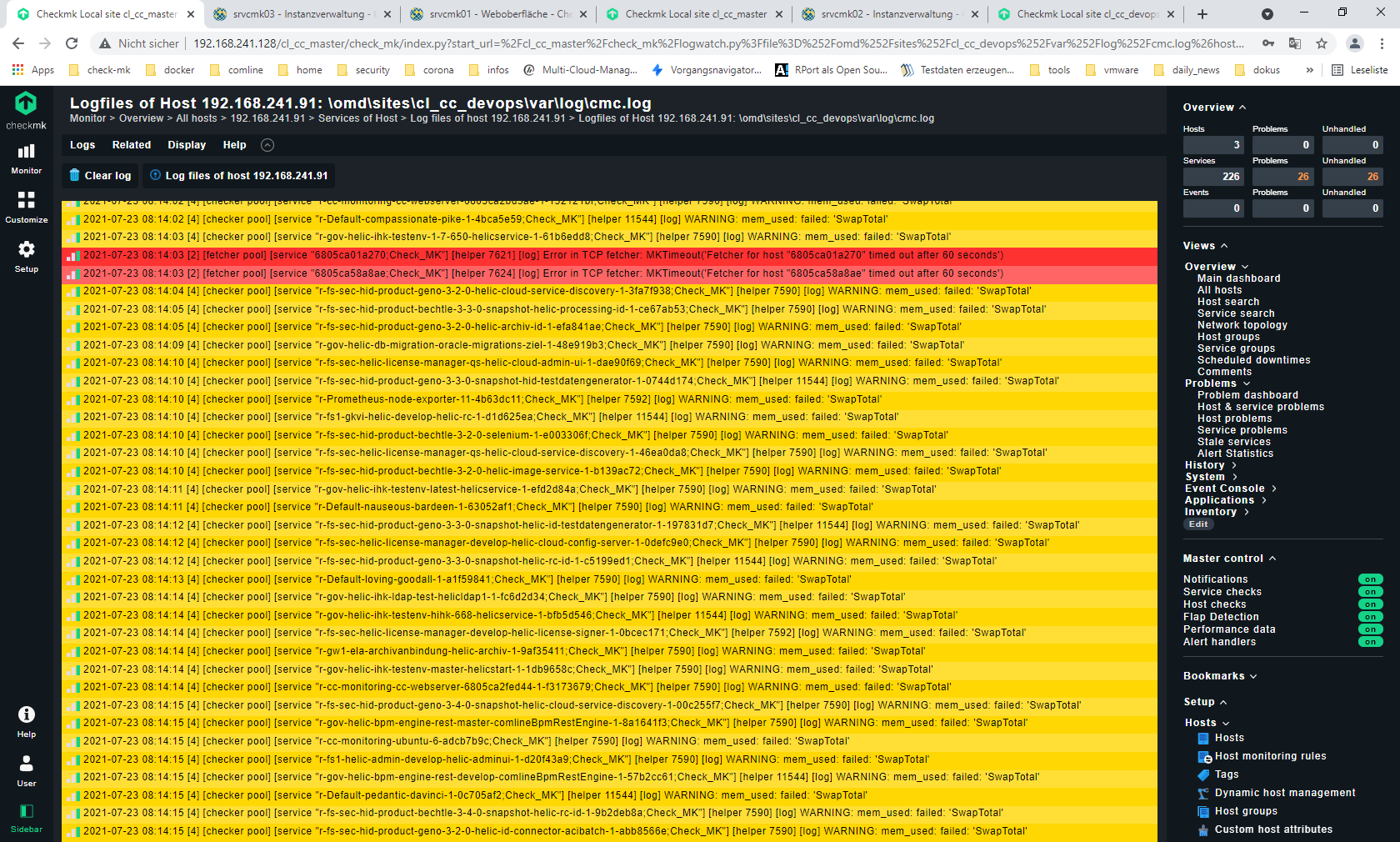
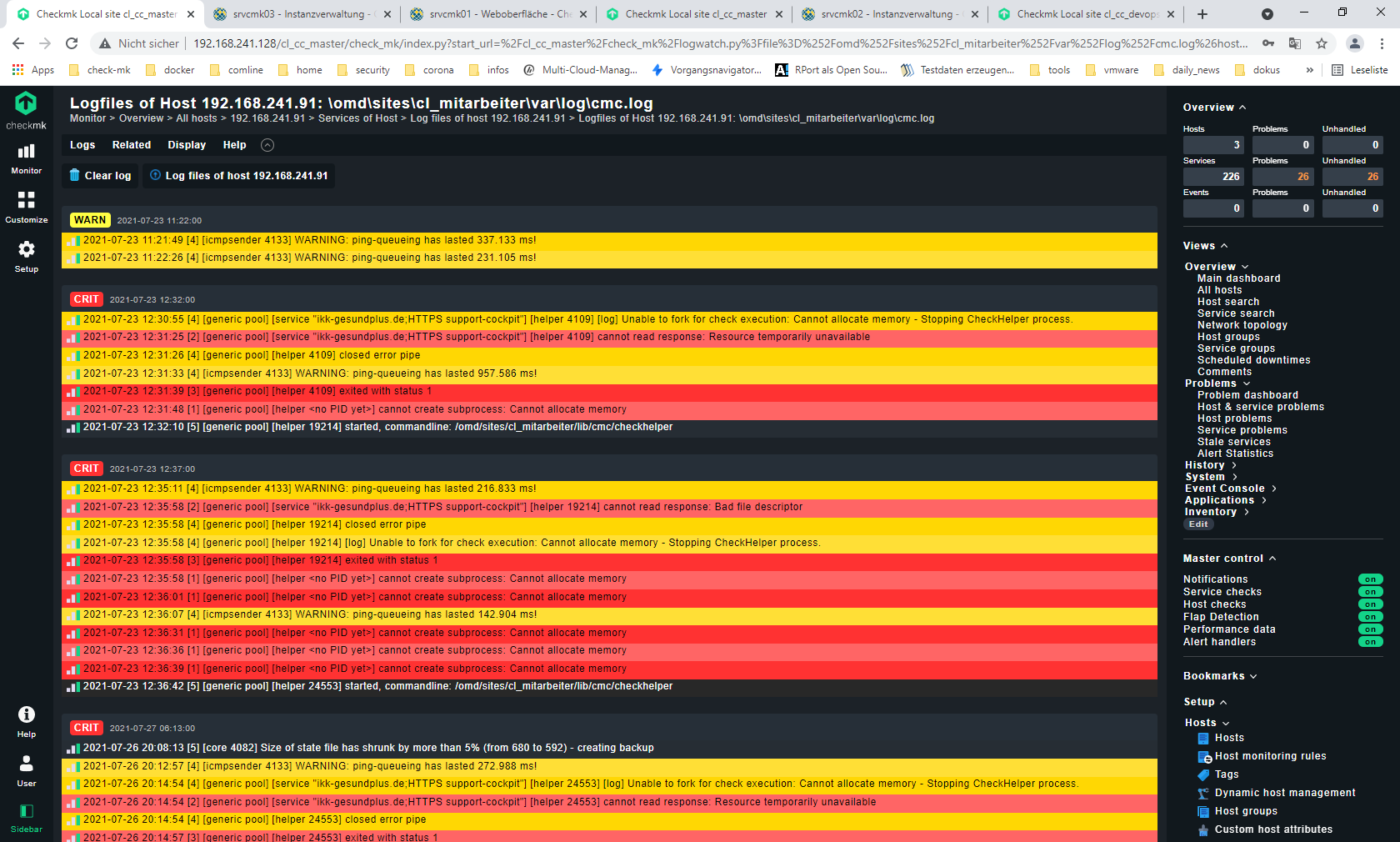
Hallo Ralf,
wie viele Host und Services hat denn diese Site? Hast du mal an den Parametern für Helper und Fetcher was verändert?
Viele Grüße,
Christian
Hallo,
die spezielle Site hat 598 Hosts mit aktuell 7943 Services.
2/3 der Hosts sind Container die automatisch verwaltet werden.
Ja, ich spiele mit den Werten weil mein Speed-O-Meter ständig rot ist.
Mit meinen aktuellen Werten komme ich auf grob 80% scheduled rate
Werte sind
maximum concurrent
aktive checks 10
fetchers 45
checkers 50
ich neige aber auch dazu das gante Container Monitoring in eine eigene Site auszulagern um zu klären ob die Probleme daher kommen.
Gruß
Hi Ralf,
für deine Umgebung kommen mir die Werte, die du gesetzt hast, extrem hoch vor. Der Standard sind 4 Checker und 13 Fetcher. Es sieht für mich so aus, dass durch die hohen Werte beim Checker dein Speicher aufgebraucht wird. Ich würde es mal mit 8/26 probieren um zu schauen ob es besser läuft.
Viele Grüße,
Christian
Hier noch der Link zur Berschreibung: Checkmk 2.0: Mehr Power unter der Haube – Verbesserungen am Checkmk-Core
Hallo,
mit den Werten fällt der Wert scheduled rate auf 50 bis 70%
Dann sollte auch dein Speicherverbrauch sinken, oder?
Ob du wirklich ein Problem mit den Services hast welche ausgeführt werden verrät dir am besten die Latency für die Checks.
Ok
wie habe ich die latency Werte zu interpretieren?
Im Handbuch finde ich unter latency nichts und gibt es Graphen dazu?
Gruß
Ralf
je kleiner desto besser, im Endeffekt sollten hier nur Millisekunden angezeigt werden.
Im aktuellen Design musst halt verschiedene Werte beachten.
Fetcher helper usage → wenn die voll wird mehr Fetcher notwendig
Checker helper usage → mehr Checkers notwendig wenn voll
Check helper usage → mehr aktive Checks gleichzeitig notwendig
Wenn die drei Werte alle ok sind aber deine Latency hoch so brauchst einfach mehr Cores. Da eigentlich genug Helper vorhanden sind es aber dein System nicht schafft alles abzuarbeiten.
Das muss nicht bedeuten, dass das System ausgelastet ist in der CPU sondern kann auch sein, dass Abfragen welche lange brauchen das System teilweise blockieren.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.