@Heavy & @andreas-doehler thanks for your replies.
Ok, I understand these k8s_resources checks are supposed for another use case which I not yet fully understand like autoscaling.
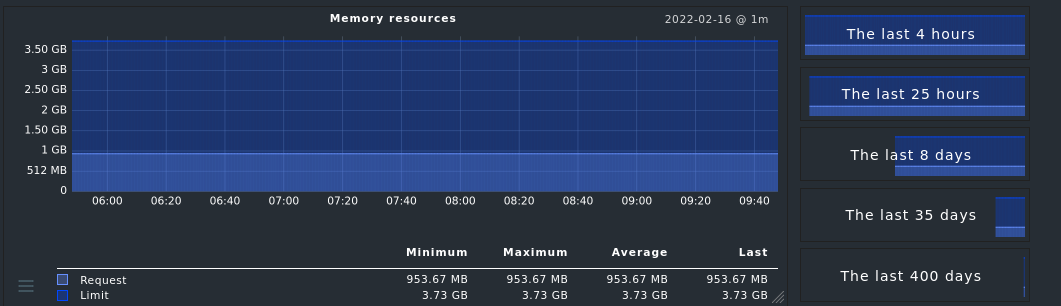
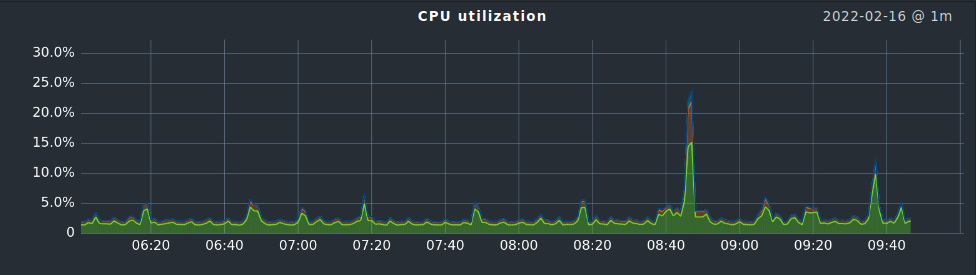
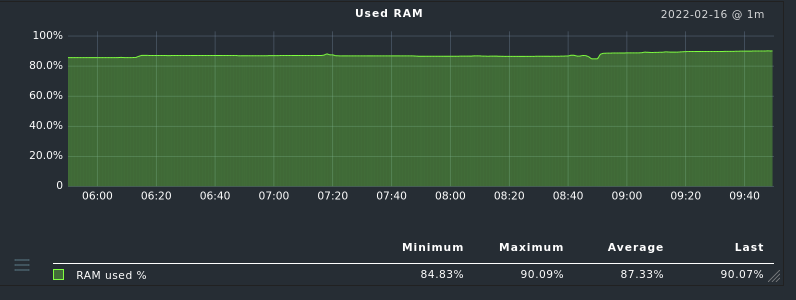
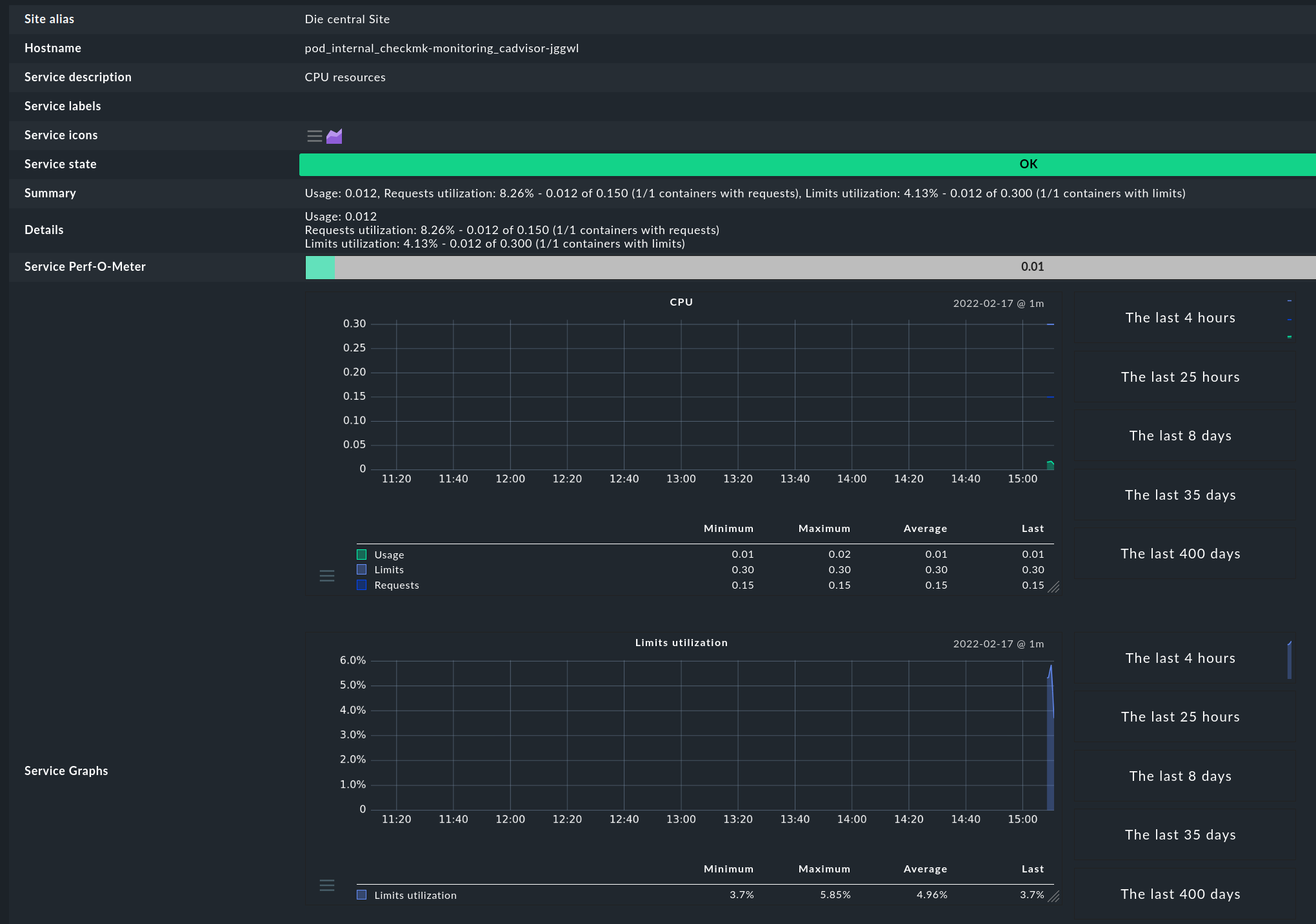
Our teams asks for pod CPU/RAM statistics and alerts.
So if I understand correctly, the k8s API has no information about CPU/RAM usage, right ?
Are there any other possibilities to get CPU/RAM usage over time as graphs per pod ?
I need CPU and RAM stats per pod.
Is Checkmk’s Prometheus integration supposed to fill the gap ?
We currently do not have Prometheus and not planning to introduce it
since we already have InfluxDB as timeseries-database.
Currently metrics from k8s are collected by a telegraf daemonset and written into InfluxDB.
I was told that the source of the metrics is the kubelet itself (this is the k8s software on each worker node).
This means to me that the k8s API perhaps does not know cpu/ram usage but the kubelet on each worker node does.
Having pod cpu/ram metrics is nice, but unfortunately
i need them in checkmk as well for alerting.
While digging through the Tribe29/checkmk git master branch, I saw a lot of changes related to kubernetes are comming with 2.1
- k8s_ prefixed checks are going to be deprecated in 2.2
- kube_ prefixed checks are going to be the next kubernetes checks in 2.1
I even fired up yesterdays master daily development build in a docker container (btw: thanks for that tribe29 team, that is so great that this is possible so easily!)
Looks like 2.1 will be able to monitoring pod restarts, we were waiting for that,
but looks like that [x] Services is now missing in 2.1 as possible “Collect information about …”
For us this a problem, we need the k8s services in monitoring to monitor
for port 443/80 and also doing HTTP health checks on the k8s services.
So 2.1 will not bring Solutions for us but another problem ;-(
Current 2.0.0p20.cee
Setup> Agents > VM, Cloud, Container > New rule: Kubernetes

In 2.1 this is much less:
2022.02.17.cee (daily development build)
Setup> Agents > VM, Cloud, Container > New rule: Kubernetes

@martin.hirschvogel , I believe that you have got a very good overview about k8s moitoring and futur plans, are there any documents, hints how I will be able to monitor k8s pod cpu/ram and k8s services (kind: Service) in 2.1 ?
I am getting afraid, that we can not do k8s service monitoring and pod cpu/ram monitoring with 2.1 checkmk, please prove me wrong.
Thanks a lot
Mimimi