Hi
This situation is very strange.
I compared the definitions with a working one → found no difference
I did the following test:
- I remove the definition
- I defined the same host again (ted-g0007) with Ansible using RestAPI
- I defined the host a 2nd time again (ted-g0007_ans2) with Ansible using RestAPI. This now a brand new host which was never defined before.
- I defined the same host using WATO (ted-g0007_wato)
- i defined this host again by copying a working one (ted-g0007_copy)
All hosts showing it as down. Hmmm ???
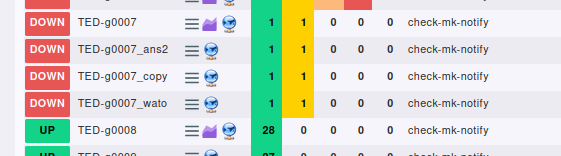
On the cmdline this host is responding:
OMD[inseo]:~$ cmk TED-g0007
[agent] Version: 1.5.0p7, OS: busybox, execution time 2.4 sec | execution_time=2.370 user_time=0.030 system_time=0.010 children_user_time=0.020 children_system_time=0.010 cmk_time_ds=2.290 cmk_time_agent=0.000
OMD[inseo]:~$ cmk -d TED-g0007
<<<check_mk>>>
Version: 1.5.0p7
AgentOS: busybox
Hostname: RAK7249
AgentDirectory: /etc/check_mk
DataDirectory: /var/lib/check_mk_agent
SpoolDirectory: /var/lib/check_mk_agent/spool
PluginsDirectory: /usr/lib/check_mk_agent/plugins
LocalDirectory: /usr/lib/check_mk_agent/local
<<<df>>>
rootfs 4672 444 4228 10% /
/dev/root 9984 9984 0 100% /rom
OMD[inseo]:~$ cmk --check-discovery TED-g0007
24 unmonitored services (cpu_threads:1, tcp_conn_stats:1, mounts:3, df:4, kernel_performance:1, mem_linux:1, local:2, uptime:1, cpu_loads:1, kernel_util:1, systemtime:1, lnx_if:7)(!), no vanished services found, no new host labels, rediscovery scheduled
unmonitored: cpu_threads: Number of threads
unmonitored: tcp_conn_stats: TCP Connections
unmonitored: mounts: Mount options of /rom
unmonitored: mounts: Mount options of /overlay
unmonitored: mounts: Mount options of /mnt/mmcblk0p1
unmonitored: df: Filesystem /tmp
unmonitored: df: Filesystem /overlay
OMD[inseo]:~$ cmk -D TED-g0007
TED-g0007
Addresses: TED-g0007.inseo.ddns
Tags: [Betriebssystem:other], [Kunde:cted], [SSH_Agent:yes], [Systemtyp:IoT], [Website_String_Check:Kontakt], [address_family:ip-v4-only], [agent:cmk-agent], [criticality:prod], [ip-v4:ip-v4], [networking:lan], [piggyback:auto-piggyback], [site:inseo], [snmp_ds:no-snmp], [tcp:tcp]
Labels: [cmk/os_family:busybox]
Host groups: check_mk
Contact groups: check-mk-notify
Agent mode: Normal Checkmk agent, or special agent if configured
Type of agent:
Program: ssh -i ~/.ssh/id_rsa -o StrictHostKeyChecking=no checkmk@TED-g0007.inseo.ddns
Process piggyback data from /omd/sites/inseo/tmp/check_mk/piggyback/TED-g0007
Services:
checktype item params description groups
--------- ---- ------ ----------- ------
I don’t see a reason why it is showing as down. If I go into WATO, the services can be discovered.
Next I ran cmk -I TED-g0007 some time later the services are shown in TED-g0007.
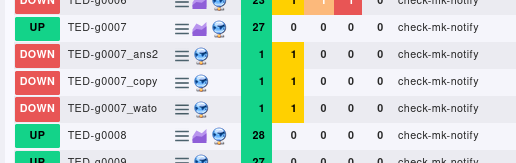
The 3 remaining nodes are still reported as down. Discovery recognizes there are unmonitored services but the never get monitored automatically.
I upgraded to 2.0.0p9 but same result.
Do you have some ideas why the are not monitored automatically?


