Does anyone know if there is a technical bulletin or document that would go over any clean up steps or maintenance if there is any if you have a large CheckMK environment?
It is not so important if you have a large or small environment. What makes more problem and needs regular cleanup is the amount of new and removed hosts/services from your monitoring system.
But all the “problems” are only disk space problems in the end ![]()
2 Likes
Thanks Andreas, that is great news since I’m typically used to running maintenance scripts within SQL or the application environments that I usually support. I’m fairly new to CheckMK, but glad to hear theirs not much overhaul when it comes to keeping the interface running smooth.
Have a great day! ![]()
the pity is still, that there is no proper cleanup routine.
For example:
rrds - which create the majority of data
remove all Host- AND/OR Service-data, older then X and being able to configure this also by Hostname
Especially with all cloud data and services which are coming and going sometimes even 1000 Services per Host, per day
Of course you can write your scripts before you answer. ![]()
But I would consider it as basic housekeeping which is not moved to the cloud level yet.
Yes inside the CEE and heavy usage of the “cloud” features this is a real problem.
At the moment my solution is a two line bash script to cleanup the rrd files.
It is not guaranteed that this will work on all systems ![]()
find . -type f -mtime +90 -name "*.rrd" | sed "s/\.rrd//" | while read f; do rm "$f.info"; done
find . -type f -mtime +90 -name "*.rrd" | sed "s/\.rrd//" | while read f; do rm "$f.rrd"; done
And for someone with better bash knowledge this can be done with one line i think.
2 Likes
more or less the same we do - BUT…
It needs to work based on tags!
As there are up to X0000+ Services we have within 90 days on one Server. (Cloud of course)
And just creating a generic rule for all is not working. And changing it to 10 days wouldnt work as well,
as there are services temporary off on some hosts, which is absolutly fine, but need to keep the graph history of them till they come back
These are arguments that should be considered for a better solution.
What i have in mind in such a case is first a search for the hosts with your defined criteria and then a command line find for every found host.
That is something for @robin.gierse or @martin.hirschvogel to bring it to the team ![]()
We have already implemented a couple of things for Kubernetes, which is by default quite dynamic.
We have many more ideas. Let’s chat next week about your thoughts on that @foobar @andreas-doehler
Its not only about Kubernetes - again, please look at the big picture and not focus on one application
We already suggested and described the pain years ago
So lets do that and hopefully get you a better picture on why and how
Till next week then
Cheers
Hello everyone,
While I understand that this topic needs more discussion, I just wanted to remind about the built-in possibility to cleanup old files of abandoned hosts. This is set per default to thirty days as far as I can see (test instance is a 2.0.0p21cee). The setting is accessible via Global Settings → Site Management:
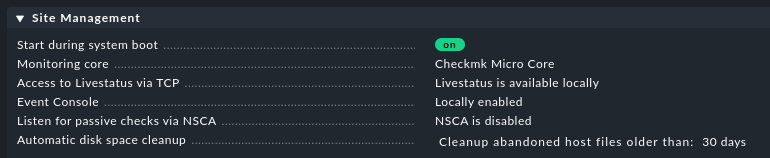
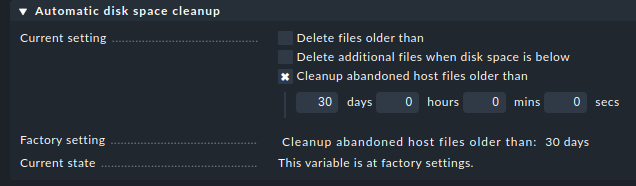
Perhaps it helps, for a start.
Regards,
Thomas
1 Like
This is not the problem.
The problem are services with performance data on existing hosts. I have database server with many many performance data producing checks and they change often. Now there is no builtin method to cleanup these old performance data. In some of my bigger systems the old performance data is nearly half the size of the complete site.
This is also a problem in big network environment where the names of the interfaces changed frequently.
2 Likes
Hi Andreas,
As I said: I understand that this topic needs more discussion. In expectation of a “better
solution”, one could at least try out those settings. When I look at the inline help for this particular setting, it says:
During monitoring there are several dedicated files created for each host. There are, for example, the discovered services, performance data and different temporary files created. During deletion of a host, these files are normally deleted. But there are cases, where the files are left on the disk until manual deletion, for example if you move a host from one site to another or deleting a host manually from the configuration. The performance data (RRDs) and HW/SW inventory archive are never deleted during host deletion. They are only deleted automatically when you enable this option and after the configured period.
So maybe it can help the initial requester, for a start.
Thomas
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.