Hi @robin.gierse and thanks for the reply.
After some more tryings we solved our problem in pretty good way.
Solution in distributed monitoring is to create new virtual machine or different site with different livestatus port. The next step is to add a new client and a new distributed connection, leaving the existing one as it is. After successfully connecting the new site (B), we need to go to Setup → Host and change the folder properties with the configuration of the old site (A) and change “Monitored site” from A to B.
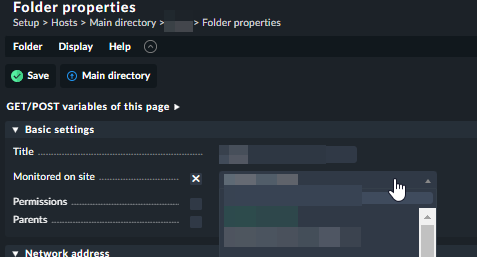
Next, we adopt all the changes in our distributed monitoring to be clear with everything. When we change the monitored folder on site, each host is moved from folder A to folder B and site, with only host status or PING being displayed, depending on the configuration. In this steps rules are not implemented.
And this is where things get tricky. All the hosts are missing services and rules, but they are here in our environment in Master configuration. For a test, we need to choose a host that we remember that he has some services added, then when we perform service discovery, after a few seconds in our eyes will be prompted list of services that are already monitored, disabled or new. The trick is to add, remove or disable one of the services to update the data and assign rules. Then we go to Accept changes and any rule that was applied in site A will be moved to site B for that host.
This was our test, if it works we can go to Setup → Host and do a bulk discovery of folder B. Our environment has 362 hosts with 6k services. The bulk finished after 7 hours. After some time we need to go to Setup → Background Jobs, find our discovery and check if the status is complete.

Then we have to repeat the tricky step because nothing will show up in our changes. So select a one host, do service discovery, add/remove/disable service, go to changes and activate. If there was a bulk run and it was finished, it was for all the hosts we have in the B folder and subfolder, even if the information is not displayed
Relax, if bulk discovery has completed, even with errors, this is information for us that CMK could not perform discovery because services are already being monitored and python script errors.
Then, as if with a magic wand, all hosts will have a service and rules properly moved from site A to site B. The only disadvantage is that we lose all historical monitoring data, but we do not have to configure everything from scratch or from the OS.
One last thing, in distributed monitoring, Site A and Site B need to have the Enable replication → Push configuration to this site option checked.
When we migrated, we didn’t make any changes to folders or rules, so everything was moved 1:1.

If anyone has any questions please feel free to ask, I hope everything I have described here will be helpful to someone and save many hours or days of repair time.
So far I have not deleted folder A, if I do I will update the thread on the forum if everything still works fine.
Sincerely,