Ich möchte gerne ICMP Pings auf jeden Host aktivieren um Schwellenwerte für die Paketlaufzeit und den Paketverlust festzulegen.
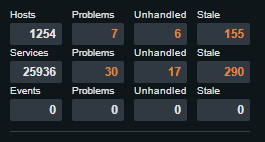
Doch allerdings habe ich schon ohne dies eingerichtet zu haben ca. 10% meiner Hosts im stale Zustand, wenn ich alle Hosts auf den Ping umgestellt habe sind es bis zu 50%.
Meine fetcher und helper sind dabei aber nichtmal ausgelastet.
Woran könnte das liegen, dass ich trotzdem Hosts im stale Zustand habe? Es sind größtenteils nur Hyper-V Server .
Oder gibt es auch noch eine Alternative die Schwellenwerte von Paketlaufzeit und Paketverlust wo anders anzugeben?
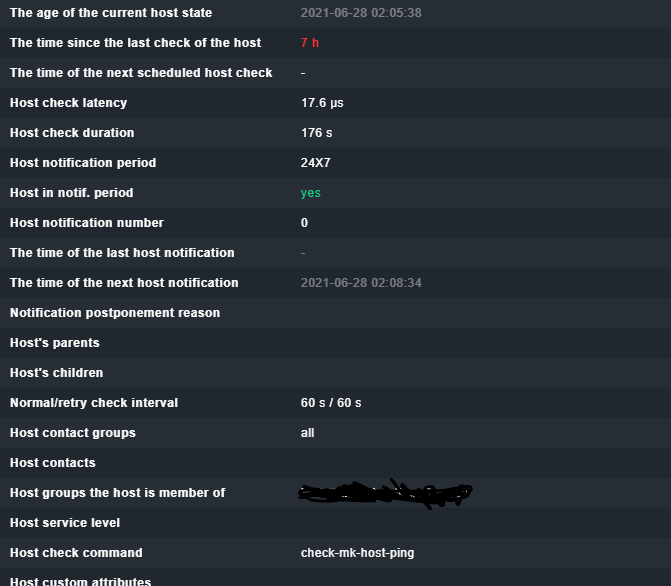
Für die Schwellwerte muss für jeden Host einmal pro Minute check_icmp gestartet werden.
Bei 1254 Hosts sind das 21 neue Prozesse pro Sekunde, die dann jeweils 5 Sekunden laufen. Das sind also in jeder Sekunde 100 laufende check_icmp-Prozesse. Da wird es wohl zu Verzögerungen kommen.
Der Hostcheck sollte weiter auf Smart-Ping bleiben und nur bei den Hosts, wo die Latenz und der Paketverlust wirklich interessant sind, kann check_icmp als aktiver Service-Check eingerichtet werden.
So ist es auch momentan eingerichtet.
Allerdings habe ich trotzdem so viele Hosts im stale modus und ich weiß nicht woran es liegt.
(es sind größtenteils Hyper-V Server)
Das ist wahrscheinlich interessant. Der Host check interval ist aber bei 60 Sekunden
Wie viele Cores hat den der Monitoring Server? Damit liese sich abschätzen ohne CPU Load oder ähnliches zu sehen ob das Problem daran liegt was @r.sander schon berechnet hat.
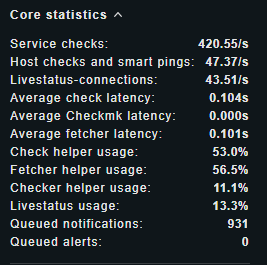
Auch würde ich erstmal dafür sorgen, dass die 931 Queued Notifications weg kommen die machen das ganze System extrem träge. Auch wenn dies eigentlich nicht den Core selbst beeinflussen darf.
6 Kerne bei 1250 Hosts is bisl wenig - da solltest so 12-24 Kerne haben vor allem wenn du aktive Pings noch machen willst. Viel hängt hier auch von der Art der überwachten Hosts ab → also SNMP vs. Agent
ca 50 Host checks & Smart Pings pro Sekunde - wenn alle deine Hosts per Smart Ping gecheckt werden sollte hier eine Zahl von ca 200-210 stehen.
Service Checks sieht noch ok aus. Kann aber auch runter gehen wenn du mehr normale Pings machst da dies dann alles aktive Checks sind.
Muss nur @r.sander kleines wenig widersprechen der check_icmp sollte keine 5 Sekunden dauern das macht nur der check_ping aber selbst wenn der im besten Fall halt nur 100ms dauert sind das 2 Cores welche nur Ping machen die ganze Zeit.
Die Notifications sollten sich in “~/var/check_mk/notify” befinden wenn ich mich recht erinnere kann grad nicht nachschauen.
Okay vielen Dank, werde ich sofort anpassen.
Mein größtes Problem ist momentan leider dass ich keinen Host check auf den Hyper-V Servern am laufen habe.
Lege ich den Host neu an funktioniert alles wieder wie gewohnt. Nur bei den bereits vorhandenen Servern tritt das Problem auf. Allerdings möchte ich ungern alle 100 HVS neu anlegen.
Dann wird es noch mysteriöser. Host Check Command bei allen identisch also neue wie alte?
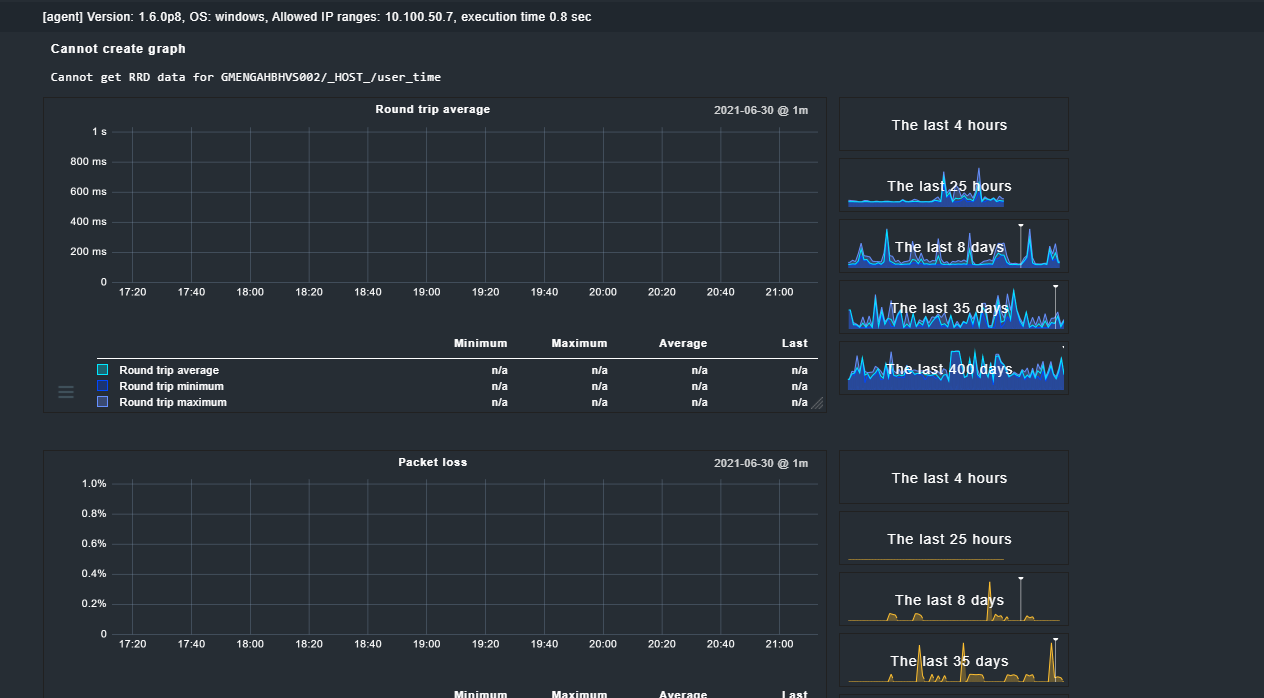
Bei dem Graph sehe ich gerade was das Problem ist. Hier wurde mal als Host Check Command der Check_MK Service benutzt oder probiert. Er versucht einen Graph für “_user_time” zu zeichnen das gibts nur im Check_MK Service. Ich würde sagen hier sind jetzt erstmal die Host Ping Graphen kaputt.
Zum testen
OMD stop
RRDCached bereinigen
von einem der betroffenen Hosts mal den HOST Graph löschen (is halt weg ) - info Datei + rrd Datei
OMD start
schauen ob bei diesem einen Host wieder ein Hostgraph gezeichnet wird
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.

 aber selbst wenn der im besten Fall halt nur 100ms dauert sind das 2 Cores welche nur Ping machen die ganze Zeit.
aber selbst wenn der im besten Fall halt nur 100ms dauert sind das 2 Cores welche nur Ping machen die ganze Zeit.