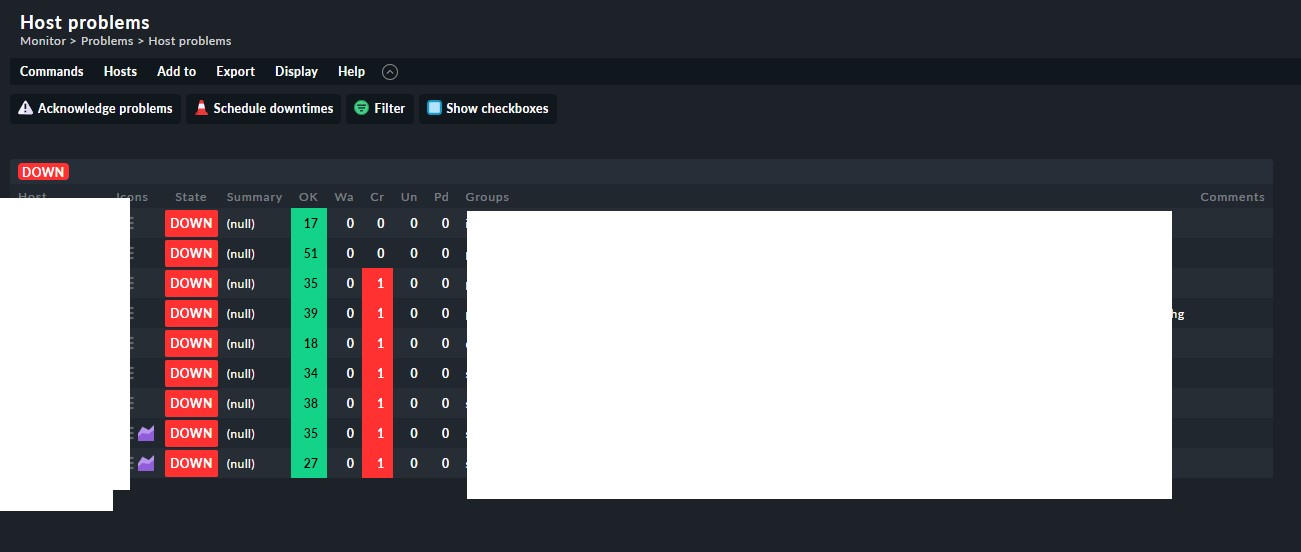
I’m a bit stuck here. Almost any time we activate changes in CMK Raw 2.0.0.p9 we get a number of hosts that will show as down with a “Null” summary. The number of hosts that will show this ranges from 1 - 100+
I’ve not found any performance or configuration issues on the monitoring sites/hosts.
We have 6 total sites with around 1400 total hosts.
The agents on all hosts have been updated to match the server version.
Any idea where I should start looking? I would appreciate any help.
There are some points you can check.
The problem hosts shown belong these to the same site every time or is it distributed over your complete infrastructure?
Next check - what is used as the host status? Is it a normal ping or do you use the status of the Check_MK service or something else?
As i see no metric icon be some of the hosts i think the host check command is the problem.
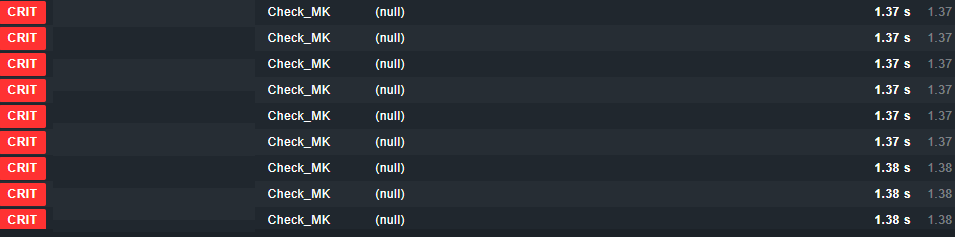
I would say there is no real best practice. The problem i saw at some 2.0 installations was that a Check_MK service goes critical with output “null” if it is checked directly at the activation time.
At the next check interval it is Ok again. If you use now the status of the Check_MK service as host status then also you host has the chance to be critical at activating changes. You can also say more hosts equal higher chance to have some critical hosts.
I only use service states as host states if i cannot ping the host.
Hi,
I have one main server and six other Check MK proxies for different regions.
I have just tested that the (null) issue is extended to the other monitoring proxies.
When I apply a change that affects devices monitored by other proxy nodes I’m also getting the null summary for devices from that remote proxy.
If apply changes affecting to my main server and devices from other proxies, I see this problem for devices from the main server and the affected proxies.
Although, I use ping to monitor the host status and I’m not getting new hosts down alerts, just the Check MK service summary (null) issue.
I use Check MK 2.0.0p9 CRE.
Regards.
Good morning, we migrated from 1.6.p19 to 2.0.0p4 and we also have this problem (the hosts are all ping)
Currently we are with a master and 4 slaves all in CRE version 2.0.0p8 and the problem continues, it is quite annoying
Hello, the problem is exactly the same as @AnthonyWingerter, when applying the changes from the MASTER the hosts (not all, it is random) of the SLAVE remain in null until it redoes the check. All hosts are pinging.
This has never happened in 1.6, it has been happening since we migrated the infrastructure to 2.0, it is not serious, since it does not launch notifications, when giving the next check ok, but it is quite annoying.
Hi, I’ve the same problem with 2.0.0p9 (never happened with deploy @ 1.6 version). The unique difference is that it’s not an “host down” alarm but a “service critical alarm”.
I made many tests looking at htop output and I can confirm that null otuputs come when activation overlaps with host and service check.
In our enviroment also “periodic/bulk service discovery” trigger theese errors.
Note that, at the beginnig, we had only one site for (500 host/ 6000 services) and we decided to split to a multisite environment because of the “null issue” but in this deploy it was triggered by “periodic service discovery”, not by changes activation.
now, in the multisite distribuited deploy (4 site with 8/8/8/16 core) the issue is triggered mainly by changes activation, rather than by “periodic service discovery”
We are still facing the issue in 2.0.0p9 CRE. I reported the issue, but never got any type of response. I’m hoping this is addressed in a newer release 2.0.0p15 has been released today. I’m hoping to upgrade soon to determine if this issue has been resolved.
I reported this issue as soon as first stable version of 2.0 was released. I never received any kind of answer to this report. In current check_mk RAW version (2.0.0p15) the issue still exists. It seems that check_mk guys are not interested to release stable free version which can be used to monitor infrastructure with more than 30-40 hosts. In other words, if you have to monitor infrastructure with more than 30-40 hosts (and you don’t want to use an alternative), you have two options:
it is still present in 2.0.0p18, that has also add big problem in distribuited enviroments (there is a problem in TLS enc between server that slow down GUI )

 !
!