Hallo zusammen,
meine CPU-Last vom CheckMK-Server ist sehr hoch. Daher meine Frage, ob das normal ist oder ob es Optimierungsmöglichkeiten gibt?
Server: HPE ProLiant DL380 Gen 9 (Virtualisiert mit VSphere 7.0.3)
CPU: Intel Xeon E5-2650 v3 @2.30 GHz
CPUs: 8, Cores pro Socket 2, Sockets 4
Auslastung: Durschschnittlich ca. 3,4 GHz
(Auf einem DL380 Gen 10 mit einer Gold 5218 @2.30 GHz CPU ist die Auslastung ähnlich hoch)
Anzahl der überwachten Hosts: 25 (Windows- und Linux VMs, Switche, Firewall) mit ca. 1200 Services.
Als Plugins habe ich standardmäßig System Updates und mk_inventory verteilt. Der Check_MK HW/SW Inventory läuft alle 24h.
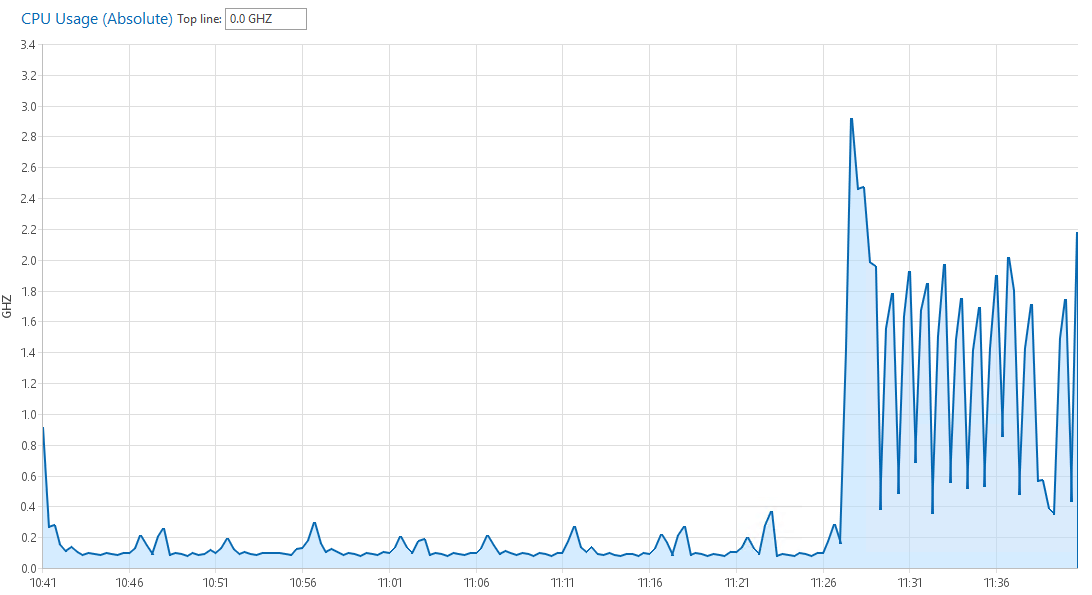
Bei den virtuellen Maschinen macht sich der CheckMK Agent auch bemerkbar. (Siehe Bild)
Um ca. 11:27 habe ich den CheckMK Agent aktiviert.
Daher einfach meine Frage, ob es Möglichkeiten zur Optimierung gibt, oder ob das Verhalten normal ist.
Ich weiß, dass bei einem Upgrade auf die Enterprise Version CPU Ressourcen eingespart werden können, wollte aber erst andere Möglichkeiten prüfen.
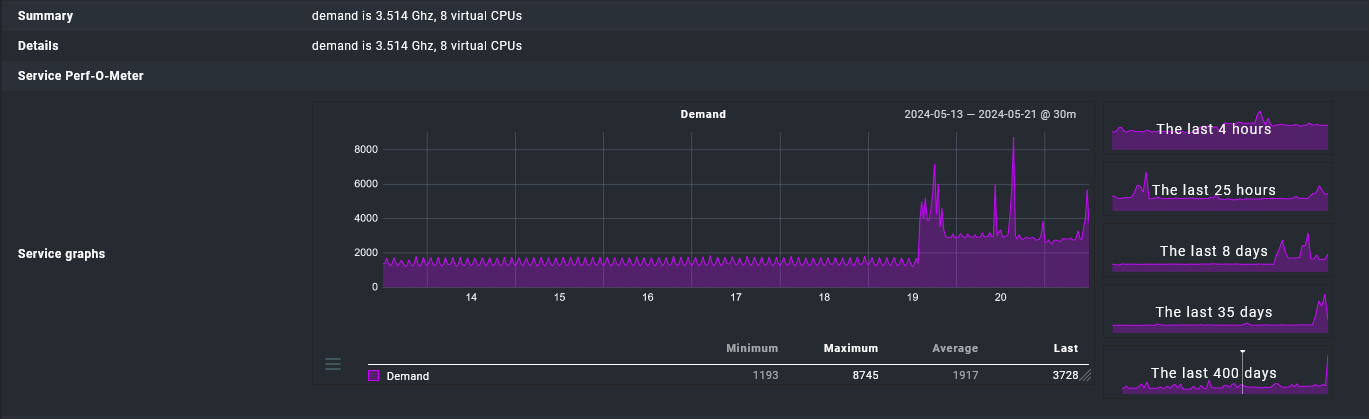
Mit Graphen habe ich keine Problem. Nach dem Update von 2.2 auf 2.3 ist die CPU starkt angestiegen. Ich finde, dass es aber auch vorher schon recht viel ist.
Anbei Messwerte der ESX CPU. Man erkennt genau, wann das Update gemacht wurde.
VMs Linux → Windows Agent 2.3.0p2
VMs Linux → Linux Agent 2.3.0p2
Switche → SNMP
NAS → SNMP
Plugins: Veeam, System Update, HW/SW Inventory
MKPs: Nextcloud, aruba_cx_sensors, redfish für ILO (Host ist aber deaktiviert), win_sys_updates_with_ignore
ich lese heraus, das du von 2.2 auf 2.3 ein update gemacht hast?
die 2.3 benötigt mehr Power als die 2.2:
2.2. Hardware-Auslastung überprüfen
Checkmk 2.3.0 erfordert etwas höhere Systemressourcen als 2.2.0. Daher ist es ratsam, vor dem Update zu ermitteln, welche freien Kapazitäten für Checkmk verwendete Server noch haben.
Betrifft Sie das? Ja. Allerdings hängt es stark von der Art der Nutzung von Checkmk ab, wie stark sie betroffen sind. Alleine das Update des Python-Interpreters von Version 3.11 auf 3.12 verursacht eine Lastzunahme im einstelligen Prozentbereich. Des weiteren können umfangreichere Checks gerade im Cloud-Bereich je nach Anteil an der Gesamtmenge der Checks für weitere Mehrlast sorgen, so dass insgesamt 10–15 % (in Extremfällen um 20 %) mehr CPU-Last zu erwarten sind.
Was müssen Sie tun? Stellen Sie sicher, dass genügend freie Kapazitäten vorhanden sind. Als Faustregel gilt: Liegt die _ CPU load_ unter Zahl der Prozessorkerne × 0,8 und die CPU utilization unter 70 %, sind keine Probleme zu erwarten. Liegt einer der beiden Werte oder beide höher, schaffen Sie genügend freie Kapazitäten, beispielsweise indem Sie Test-Instanzen auf demselben Server deaktivieren oder Hosts auf andere Instanzen verschieben.
Mit der RAW Edition beschäftige ich mich nicht, daher bin ich mir nicht sicher welche host checks es da so gibt, ich gehe mal davon aus Du hast das nicht verändert, kannst das aber auf dem Host unter ‘Host check command’ Prüfen:
danke für den Hinweis. Bei mir liegt die Mehrlast teilweise bei über 100%.
Ein Average von ca. 3.4 GHz ist für mich deutlich zu hoch für 25 Hosts. Vorher lag der Average bei ca. 1.7 GHz, aber auch das ist finde ich zu viel.
Aber vielleicht irre ich mich auch. Gibt es vergleichbare Werte? Oder ist das Verhalten normal?
Ich möchte nur vermeiden, dass die üblichen VMs unter der Last des CheckMK-Servers oder der Agenten “leiden”, daher liegt jetzt alleinig die CheckMK-Maschine auf einen DL380 Gen9.
Diese Werte sagen gar nix. Bitte auf dem Monitoringsystem den Agent nutzen um festzustellen was los ist. Ich glaube aber deine Probleme kommen von dem verlinkten Problem.
Es laufen bei dir zwei Prozesse “process_perfdata.pl” das sollte in einem so kleinen System wie deinem nicht der Fall sein.
Bitte mach mal das Troubleshooting aus dem Artikel.
Having the same problem. After 2.3 upgrade, CPU utilization has become a significant problem and the “…/var/check_mk/core/helper_config/latest/host_checks/…” seem to be at fault.
Even after upgrading the CPU which before had never been necessary, my machine often reaches 100% for certain periods from a few checks running in parallel. The baseline in between check intervals is in similar but spikes have become much, much, much more significant, graphs that used to form plateaus turned into jagged, tall mountain ranges. Unfortunately, I’ve done a lot of changes to deprecipitaiting stuff already, so reverting to 2.2 (and likely re-upgrading later) would mean a lot of time and effort wasted.
The service discoveries in particular cause large spikes and often time out and become red since they cluster. (I haven’t caught one live yet, but the spikes match the periodic service discovery interval and last checked times for SD perfectly)
Not having any problems with graphs unless I try to access them at a moment where CPU is simply dying too much to display them. Getting the those perl .so files from 2.2 over to 2.3 as advised as a workaround doesn’t seem to be improving anything for me so far (although I’ve only tried that around 15 minutes ago), my baseline utilization is actually looking worse and the nasty 100% CPU spikes keep occuring.
Edit: I had missed this recommendation, will try it and see if it does anything for the CPU…
Very highly likely it is related to the missing files. Please keep in mind that you also need to change the mentioned line to /opt/omd/versions/<2.3.0-version>/lib/pnp4nagios/process_perfdata.pl (see other). Otherwise it will not work. It will take some time until all the backlog is reduced, and then all should be back to normal.
You can also run perl -le 'use RRDs;' as a site user. If this runs an error, then please double check if you performed all actions as recommended.
@ Martin: Thank you! Classical hasty reading mistake on my part then, I didn’t see that line about editing the file and skipped the step.
I can’t entirely judge it yet, but for now I’m seeing a change for the positive.
Utilization spiked as to be expected right after reactivating the site once more, but it seems to be mellowing down. I’m still seeing spikes to 100% on all cores in htop if multiple system checks run at once, but they last notably shorter and don’t seem to be making a visible impact on the graph level anymore.
I’ll observe it some more to be certain since it has not long been long since the change yet, but it seems significantly improved.
- it seems to be indeed stabilizing at a notably lower and stable level, except for the Check_MK Discovery, which still incurred a large CPU spike and many (but less than before) failures/timeouts.