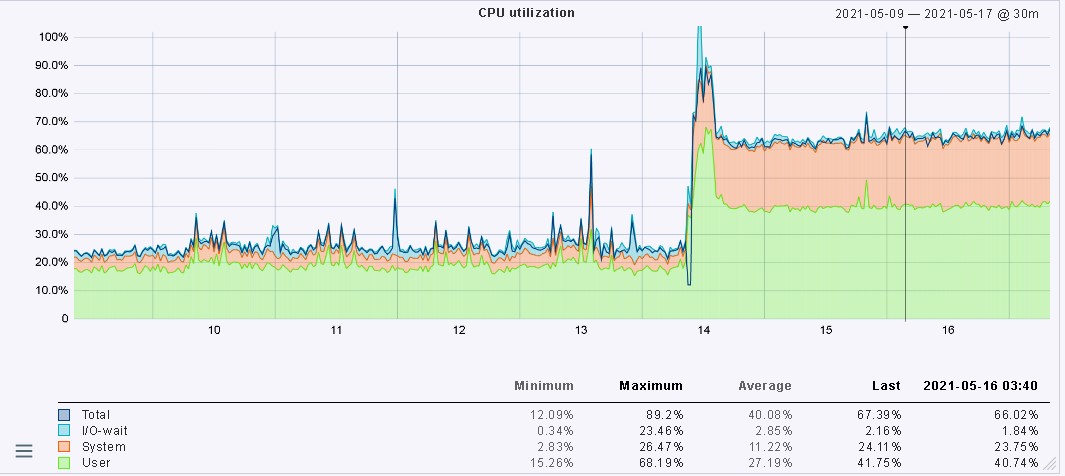
With this version you have two different helper processes - fetchers and checkers.
Fetcher will only transfer the data from the agents/devices to the checkers to be checked then.
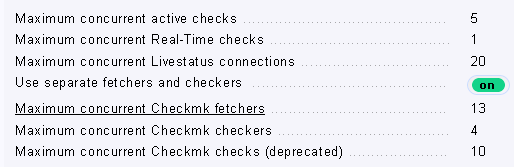
Can you have a look how many of these two helpers are defined in your system?
Rules are → Maximum concurrent Checkmk fetchers/checkers
You can also switch back to the old model with “Use separate fetchers and checkers” turned off.
This can be used to test if there is some difference in the load.
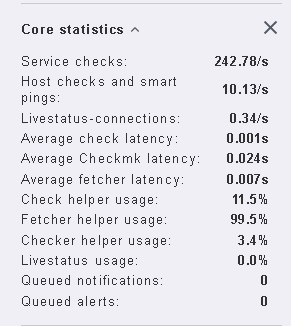
In your case you need more fetchers if they are nearly 100% in usage.
Latency looks ok. I would decrease the check helpers a little bit and increase the fetcher helpers.
You can have also a view at the graphs from the “OMD nagios performance” to see how high your helper usage was with 1.6
It is a possible problem to go from combined helpers as it was with 1.6 to the separate helpers for checks and to fetch data. You need to test and find the sweet spot between booth.
If you have only agents with a short runtime you need fewer fetchers compared with the same amount of hosts but all checked with snmp.
I think there is no general solution or good advice.
Same issue for me with checkmk cee 2.0.0p12 update with 1.3K snmp hosts & 24K services. I had to move gradually ‘fetcher helper usage’ from 13 to 200 !
Now the fetcher helper usage drops from 99% to 54%
Meanwhile the monitoring core services check rate rises from 33 services check/sec to 340/sec
Not a big surprise, now my checkmk VM memory is critical
But I know well the sysadmins guys
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.