CMK version: Checkmk Managed Services Edition 2.2.0p25
OS version: Debian 11.9
Hello everyone,
We are currently facing an issue with our Check_MK setup, where the master instance is located in our data center, and we have Check_MK satellites running in the Azure Cloud. The instance in Azure is responsible for performing website checks, while the websites themselves are hosted in our data center.
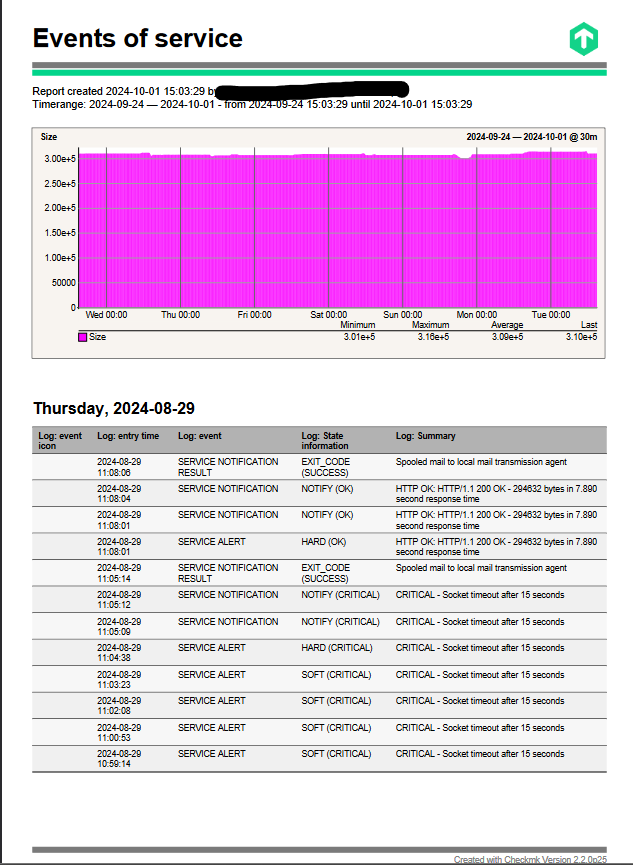
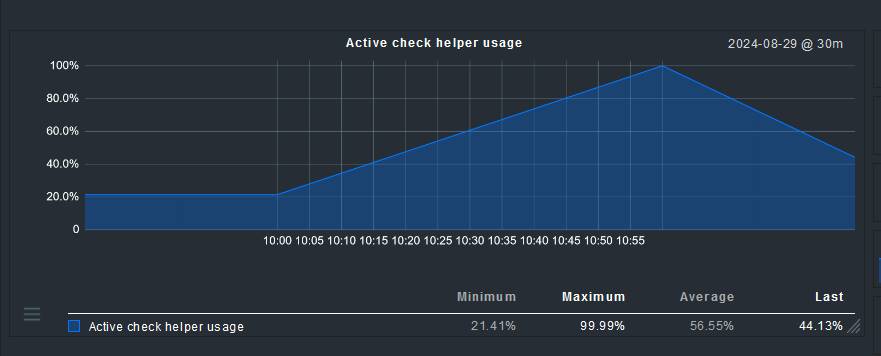
During a recent storage issue in our data center, nearly all virtual machines were forced into read-only mode. Unfortunately, it seems that no website checks were executed during this outage, which has resulted in highly inaccurate SLA reports. I’ve attached an example report to illustrate the problem, along with a log file from one of our proxies that was unaffected by the read-only issue, as its storage remained intact.
In our setup, most website checks are performed using custom plugins. For instance, we use the following command to carry out the checks:
check-mk-custom!check_http --sni -t 15 -H $_HOSTURL$ -f $_HOSTFOLLOWREDIRECT$ -S -E
Our Azure site is connected to the data center via VPN, and the website checks are executed against the public IP addresses of the websites hosted in the data center.
However, at the exact moment when the master instance became unavailable due to the outage, it appears that all website checks ceased. This is puzzling, as the satellite instance in Azure should theoretically be capable of performing these checks independently. It raises the question of why these checks failed to execute once the master was offline.
I’m wondering if there is some kind of hidden dependency between the master instance and the satellite in Azure that could explain this behavior. Could it be that the master was responsible for scheduling the checks or processing their results, and if so, is there a way to configure the system to allow the checks to continue when the master is down?
Outtage-Time: 10:29-10:49
Proxy_logfile.txt:
Src-IP: 50.50.50.50 => Customer CMK
100.100.100.100 => Our Azure CMK Site
I’d greatly appreciate any insights or recommendations on how to prevent this issue in the future and ensure that the website checks continue running smoothly even if the master instance becomes unavailable.
Thanks in advance for your help!
proxy_logfile.txt (4.9 KB)