My setup includes ( 1 master -> 2 slaves) both 1.5.0p24 . Now, I have an independent old site (devB 1.2.8) which I want to add as a view only site(so no replication) to my maste-slave setup.
I was able to do so successfully. But when I refreshed the master site GUI, I get the below message under Master control >> devB
To overcome this error, I logged into devB and changed the proxy-port.conf
from ProxyPass http://127.0.0.1:5000/devB retry=0 disablereuse=On
Where exactly do you see this error?
Normally this should not work. As version 1.2.8 has not all the livestatus data what is expected from a site running 1.6.
I see this error on my master site GUI. There is a snapin Master Control where you see all you site status and you can disabled/enable lot of configurations like notification,service checks etc. I tested this behaviour on my master site 1.5.0p24 and 1.6.0p11 and 1.6.0p12 and the issue remains the same.
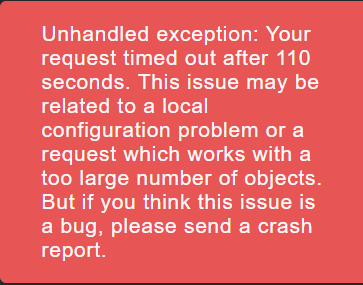
So, initially when I login to my master site, it takes more than 5 minutes to load the complete webpage and then I check the Master control snapin and I see this error once the page is loaded.
Okay. But what is the 110 seconds in the error message ? I see all the 3000 hosts defined on site devB(1.2.8) on my master site (1.5.0p24,1.6.0p11 and 1.6.0p12) which is also strange to me if this doesn’t work. So, looks like it works but I still see this error.
There are some queries made by your master site that cannot be answered by the old site.
110 seconds is the hard coded timeout for Apache queries inside the CMK environment.
This cannot be changed at the moment. All queries longer than 110 seconds will lead to an error message.
Thanks for the tip. However, if I change the connection and “Connect directly without using Livestatus Proxy” and activate the config, then the error is gone. and the webpage refresh takes few seconds.
But, I have no clue about this behaviour why not using the Livestatus proxy it works fine or what is the recommended approach ?
The recommended approach is - all connected sites should have the same main version like 1.5 or 1.6.
All other things can work but not must work.
Why is an update of this old site not possible?
First step is upgrade to 1.4 on your old system. This should work without problems if all changes and extensions done are inside the local structure.
Check if all checks are working as expected and fix problem if existing.
The step from 1.4 to 1.5 needs significant more CPU power from your monitoring system, keep this in mind for the next step. Other question is as this is a fairly old system with 1.2.8, what operating system do you use there?
Only with upgrade i lost no performance data until now and i upgraded in the meantime over 200 systems. But backup is every time a good advice
Why “synced” as it is a standalone system at the moment, it will stay a standalone system also after the upgrades. To integrate such a big system in a existing distributed monitoring is not easy.
Just to clarify, you mean the 1.4 → 1.5 update process (“omd update”) is very CPU intensive? Why is that? (I’m trying to plan various major upgrades and finding this kind of information is quite difficult)
The update process has no problem.
You need more CPU power for the monitoring system itself after the upgrade.
The reason is, that the system is more complex and how the check files are build is quicker but needs more CPU resources at execution time.