Liebe Monitoring Kollegen, vielen Dank für Eure Erklärungen und Meinungen.
@andreas-doehler
Einfach den Anwendern erklären, dass Stale Services so zu behandeln sind wie kaputte Services.
Ich bin mir sicher Sie werden dann sofort eine Alarmierung für Stale Services einfordern,
die ja nicht möglich ist, da staleness kein Status im Core ist.
Zudem ist bei uns vorgesehen, dass der Check_mk Service an die Monitoring Admins alarmiert wohingegen die Applikation Health Checks an die Applilaktionverantwortlichen gehen sollen.
Ich versuche hier gerade ein Pre-Nagios System durch Checkmk abzulösen, welches nur mit aktiven SNMP Checks arbeitet.
Unsere Anwender sind es halt anders gewohnt und haben daher nur wenig Verständnis.
Und überzeugend erklären, dass das halt so ist mit passive checks kann ich auch nicht,
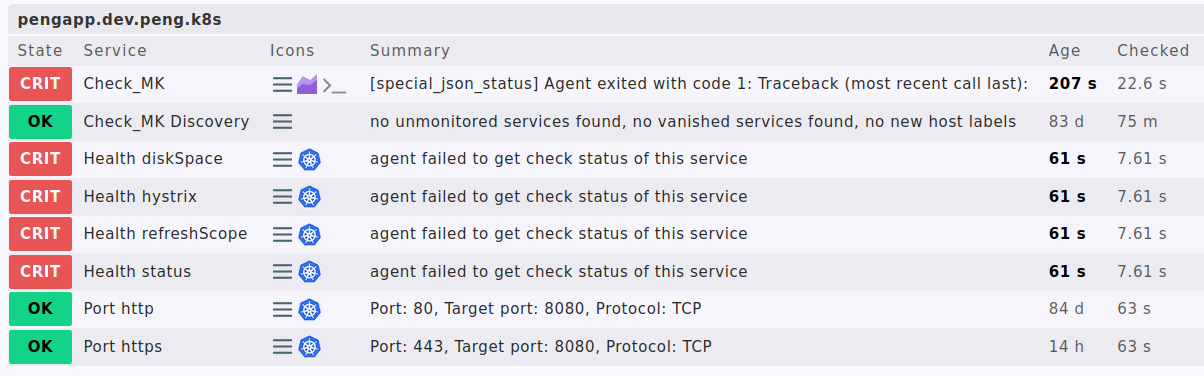
denn stale Checks die grün/OK anzeigen sind nicht das was der Kunde braucht und erwartet.
Mein Hauptproblem ist aber vermutlich, dass ich auf Basis von stale Checks nicht notifizieren kann.
Ich werde da wohl irgendwie ein Workaround finden müssen.
Als Workaround habe ich erst einmal zusätzlich ein aktiven check_http
eingerichtet auf die selbe URL, auf die auch mein special_agent geht.
Langfristig schwebt mir aber vor vom livestatus eine Liste der hosts, service
mit staleness > 3 zu erfragen und für die dann den status auf UNKNOWN oder CRIT zu setzen, weil Checkmk das ja selbst nicht unterstützt.
Entweder global per cron und script einmal mal pro Minute oder vom special_agent selbst,
wenn er kein 200 bekommen hat vom Host den er prüfen soll oder das JSON nicht parsen kann.
Da ist aber die Hürde aus dem Livstatus zu erkennen, welche Services denn genau durch diesen special_agent entstanden sind.
Könnte ja auch sein, dass der Special Agent nur <<<local>>> Sections liefert, wie soll ich dann im Livestatus in der service tabelle erkennen von welchem agent der service befüttert wird, gar nicht vermutlich ?
Also belibt meinen special_agent so zu schreiben, dass er pro Service Item noch ein Spalte agent:special_json emmitiert,
und den zum special_agent korrespondierenden check so schreiben, dass er daraus eine service label macht, dann kann ich mit einer livestatus query alle von diesem special agent erzeugten, Stalen Services finden und zu CRIT machen)
So in der Art (Syntax ist nicht geprüft):
GET services
Columns: host_name display_name
Filler: host_name: $host
Filler: label = agent:special_json
Filter: staleness > 3
Dann damit Nagios Core External Commands PROCESS_SERVICE_CHECK_RESULT auf UNKNOWN oder CRIT setzen siehe.
https://assets.nagios.com/downloads/nagioscore/docs/externalcmds/cmdinfo.php?command_id=114
Hab das mal für das konkrete Beispiel getestet:
#!/bin/bash
host="foobar.dev.team-one.k8s"
commandfile=$HOME/tmp/run/nagios.cmd
now=$(date "+%s")
echo -e "GET services\nFilter: host_name = $host\nFilter: display_name ~ ^Health \nColumns: display_name" \
| lq \
| while read service
do
echo service:$service on $host
printf "[%lu] PROCESS_SERVICE_CHECK_RESULT;$host;$service;1;special agent can not get status" $now | tee $commandfile
done
@r.sander
Wenn das Euer Spezialagent ist, dann schreibt ihn so, dass er im Fehlerfall auch Fehler liefert.
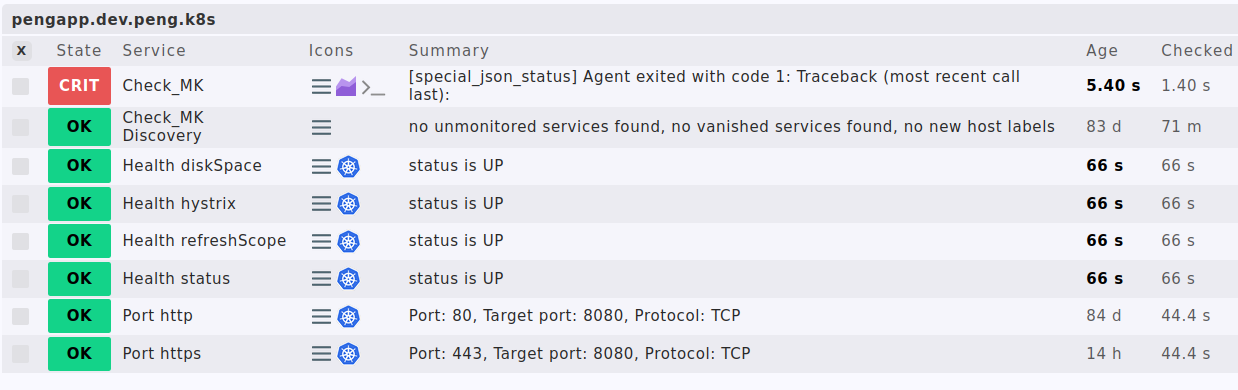
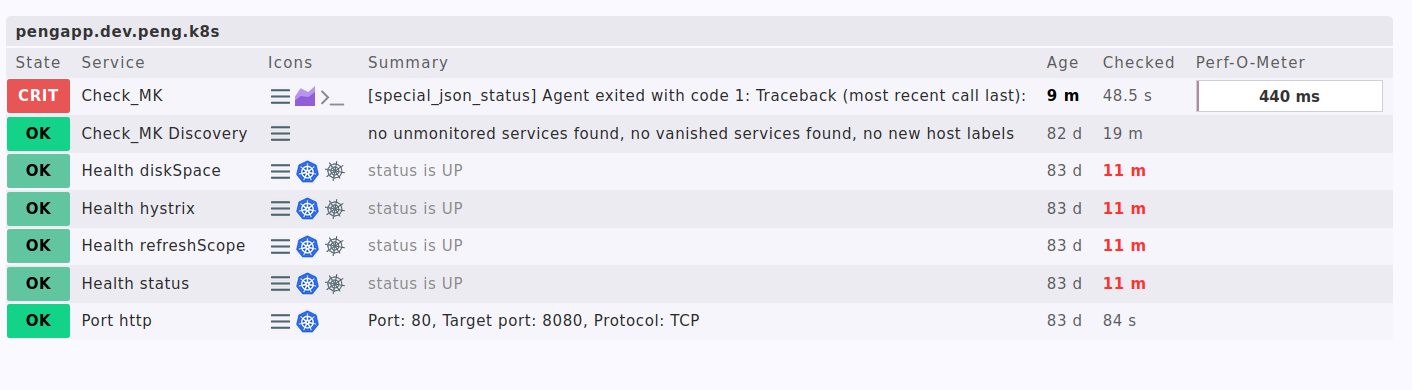
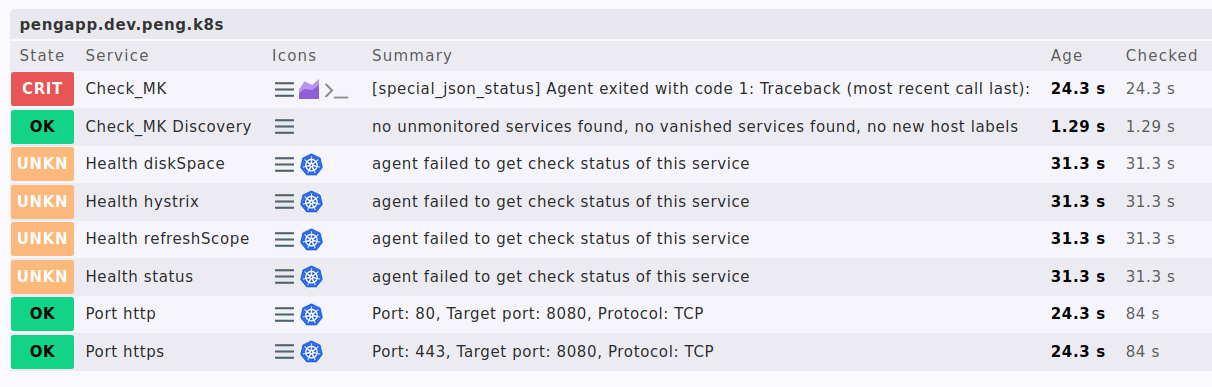
Ja, das tut er ja, aber dann wird halt nur der Check_MK Service rot.
Kaputt ist aber in diesem Fall die Applikation.
@mike1098
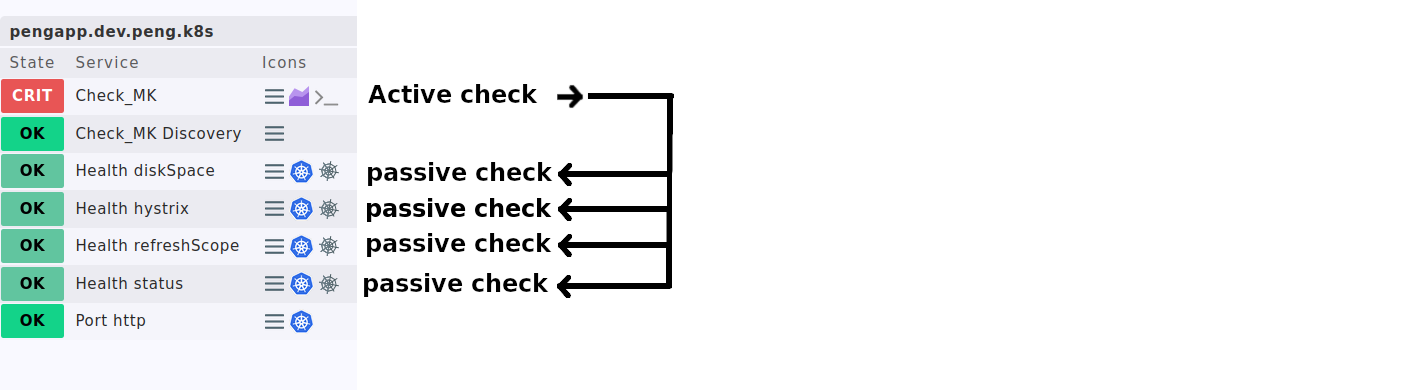
… habt Ihr es ja selber in der Hand welchen Zustand Ihr den passiven Services zuweist wenn die Kommunikation fehlschlägt.
Der einzige aktive check ist in diesem Fall der special_agent der sich dann in der GUI hinter dem Check_MK Service verbirgt.
Ich probiere gerade noch ein Ansatz, in dem mein spezial_agent immer ein Item extra liefert welches
den Erfolg der spezial_agents selbst beschreibt eine Art “Health Special Agent”, die wiederspiegelt ob er ein 200er status bekommen hat und JSON parsen konnt.
Noch etwas Kontext:
Das Webapplikationen an einem /health Endpoint Stati als JSON Stuktur zu Verfügung stellen sehe ich immer häufiger,
Checkmk hat dafür leider noch keine fertige Lösung im Gepäck.
Bei uns sieht das dann so aus:
curl --silent http://foobar.dev.team-one.k8s
{
"status": "UP",
"details": {
"diskSpace": {
"status": "UP",
"details": {
"total": 16760283136,
"free": 8138842112,
"threshold": 10485760
}
},
"refreshScope": {
"status": "UP"
},
"hystrix": {
"status": "UP"
}
}
}
Unser Special Agent macht daraus mehr oder weniger sowas:
curl --silent http://foobar.dev.team-one.k8s | jq -r '.details| keys[] as $key | "\(.[$key].status)|\($key)"'
UP|diskSpace
UP|hystrix
UP|refreshScope
Hm, ich werde mir mal was überlegen.