Einer der Netzwerkswitches ist defekt und schickt seit dem alle 1-3 Stunden einen SNMP Trap an den Check_MK Host. Wir warten auf ein Ersatzgerät und würden solange diese Meldungen von dem Switch quasi “acknowledgen”, sonst ist der Service “Events” am Host immer wieder im kritischen Zustand. Wir archivieren das Event, aber in 1-3 Stunden kommt eine neues rein und der Service wird wieder rot.
Wie lässt sich ein Event von der Sorte von diesem Gerät “in downtime” setzen? Ich würde sehr ungern den ganzen Service “Events” in downtime setzen, denn dies würde auf alle möglichen Events angewendet. Ich könnte höchstens eine neue Rule erstellen, die solche Meldungen von diesem defekten Switch ignoriert.
Habt ihr eine Idee, wie man das sonst bewerkstelligen könnte?
Hallo Hermann,
es lassen sich schon einzelne Events nicht Downtime setzen, aber als ACK flaggen. Ich denke dein Problem an dieser Stelle ist, das du Regelsätze hast die Events nicht zusammenfassen.
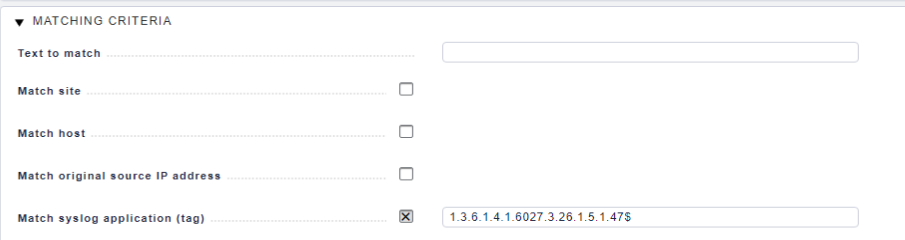
Es wird immer ein Key aus Hostname und Application gebildet. Bu kannst den Key erweitern wenn du Matching Grpous verwendest. Hier solltest du feste Werte verwenden, Datum oder Uhrzeit sind hier ungeeignet. Mit diesem Key kannst du ganz einfach das >Counting drauf legen, so das du nur ein Event hast wo der Counter hoch zählt. Dann Ist auch ein ACK fest auf das Ereignis gebunden.
Da der Status des “schlimmsten” Events “Critical” ist, bleibt der Gesamtstatus des Service Events an dem Host auch im Status “Critical”. Dass ich das Event bestätige (Acknowledgement setze), ändert leider nichts am Gesamtstatus des Services.
Hallo Hermann,
die Beiden anderen Traps zu der Maschine haben wahrscheinlich einen anderen Application Tag, oder?
Der Status zu dieser Gruppe ändert sich. Hier ein abstraktes Beispiel für IF-UP IF-Down:
Appl Tag UP: 1.2.3.5.12324.1.0
Message Text: Updtime 5d, 1.2.3.4.1234.2.47: eth0 1.2.3.4.1234.2.48: UP
Appl Tag DOWN: 1.2.3.5.12324.1.2
Message Text: Updtime 5d, 1.2.3.4.1234.2.47: eth0 1.2.3.4.1234.2.48: DOWN
Möchtest du jetzt eine Regel erstelen für IF dan sollte die so aussehen:
Application Tag: 1.2.3.5.12324.1.*
Text to match: ^.2.47: (.) ..2.48: (.)$
Application to cancel: 1.2.3.5.12324.1.0
OK: match ..2.48: UP
CRIT: match ..2.48: DOWN
Rewrite text: Interfcae \1 in state \2
Rewrite Appl: My IF
Jetzt wird nur eine Event erzeugt, was den Key Appl und Interface hat.
Ich hoffe das hilft dir.
Leider wird durch das Acknowledgen eines Critical-Events der Gesamtstatus des Services Events nicht OK. Für mich sieht es nach einem Bug aus, sonst sehe ich auch keinen Sinn in Acknowledgen.
jetzt verstehe ich was du meinst. Die Event Console ist einen andere Quelle im Livestatus. Das Acknowledgement beeinflusst nicht den Status eines Ereignisse, auch nicht einer Monitoring Ressource, sonder unterdrückt nur die weitere Alarmierung.
In deinem Fall würde ich das Event einfach via State Change auf OK setzten.
danke für den Tipp, ich habe das Event nun auf OK gesetzt. Dadurch hat sich der Gesamtstatus des Service Events auf OK geändert. Sieht gut aus soweit.
Ich warte auf das nächste Event und berichte, was passiert.
Leider wird beim Eintreffen eines neuen Events der Stauts doch überschrieben:
War der Status des Events OK, wird er in Critical geändert. Dadurch ändert sich der Gesamtstatus des Service “Event” auch wieder Critical.
Noch Ideen?
Ich glaube, ich habe es gelöst.
Ich habe die entsprechende Regel in WATO unter
“Rule-Based Configuration of Host & Service Parameters” → “Event Console” → “Check event state in Event console” modifiziert, indem ich die Option “Ignore acknowledge events” aktiviert habe:
Der Switch schickt ein SNMP Trap an den Check_MK. dies generiert ein Event im Status “Critical”, was den Service “Events” in “Critical” versetzt.
Dann wird das Event händisch bestätigt und es bleibt im Zustand “Critical”, aber der Service “Events” ist im Zustand “OK”.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact @fayepal if you think this should be re-opened.