I configured “Delay Host Notifications” to 5 minutes. I’ve noticed that notifications normally trigger after only 3 or 4 minutes (not 5). Worse yet, in a recent instance I observed a notification occur after only 1 minute and 39 seconds!!!
I cannot explain the extremely inconsistent behavior. Has anyone else observed this?
It is greatly frustrating our NOC team because they don’t want to be notified unless a host has been down for at least 2 minutes. The trigger behavior seems so premature and inconsistent that I am going to be forced to push the delay up to 6 or 7 minutes (if that will even fix it).
I believe there may be some fundamental bug in how interval calculations are made in checkmk.
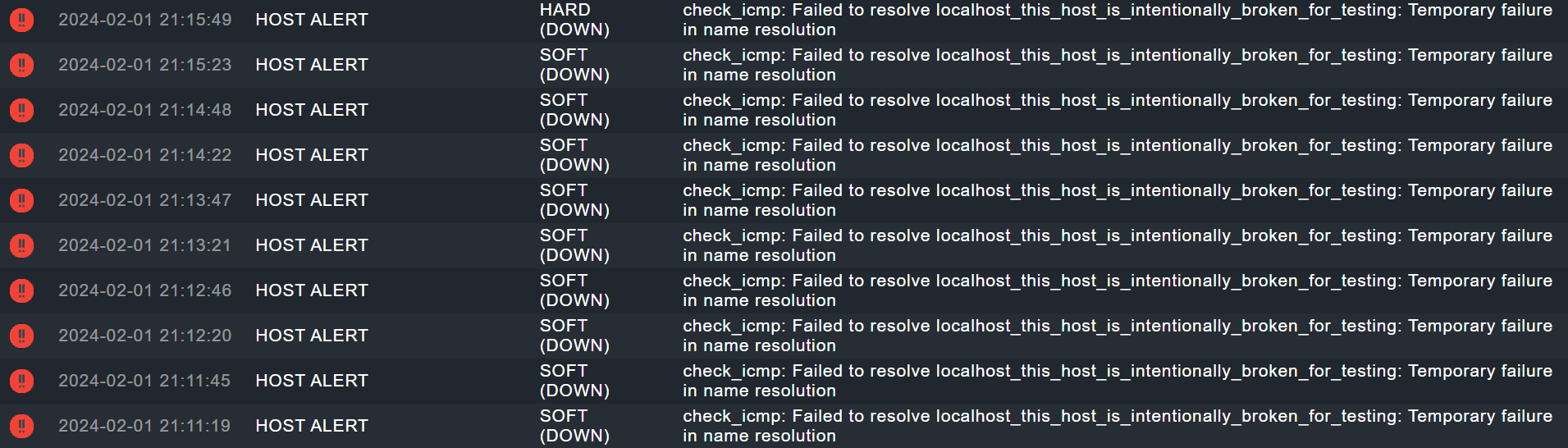
I deactivated notification delay rule and switched to “Maximum number of check attempts”, which I configured to “4”. I tested and the result is shown in this screenshot:
I am using an out-of-the-box Checkmk 2.2 raw configuration. I did not change the check interval. You will notice from the screenshot that the intervals are:
16 seconds
45 seconds
16 seconds
My understanding is that the default ICMP check is supposed to be on a 60 second (“1 minute”) interval. Other than the fact that its clearly not 60 seconds, its not even consistent!! Why is the interval so inconsistent?
I’m beginning to suspect that the inconsistent intervals might be the underlying cause of the notification delay period inconsistenty.
when the host status of a host is not ok, the regular check interval is not used any more but the “Retry check interval for host checks”.
Can you check, what the setting of this host is ?
The default is 6 seconds for smart ping and 60 seconds for all other (e.g. check_icmp)
“Retry check interval” is unconfigured. So if the default is truly 60 seconds and the retry is being used, that might explain the intermittency. However…
I configured the “Check interval” (NOT RETRY INTERVAL) to 60 seconds (previously unconfigured). And it completely cleared up the erratic behavior. I get SOFT DOWN alerts consistently 60 seconds apart.
The fact that changing the “Check interval” to 60 seconds (a value it was supposed to default to) cleared up all behavior seems bizarre.
If you use the RAW edition, it can only be a problem of the Nagios core.
I would inspect the Nagios core log. It is also possible to increase the log level of the core for some specific things.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.