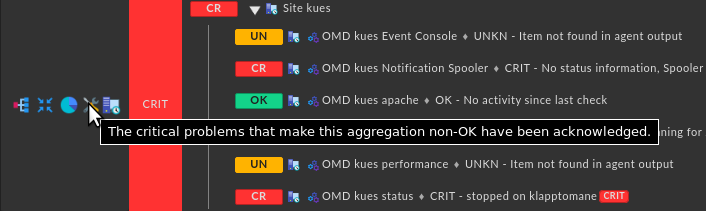
ACKs never recovered any service or aggregate back to OK and will never do so - there’s a problem, but that’s worked on (ACK’ed), that’s the way to go.
The BI article is not finished yet, so it may still contain misleading information. I’ll inform our knowledge team about this…
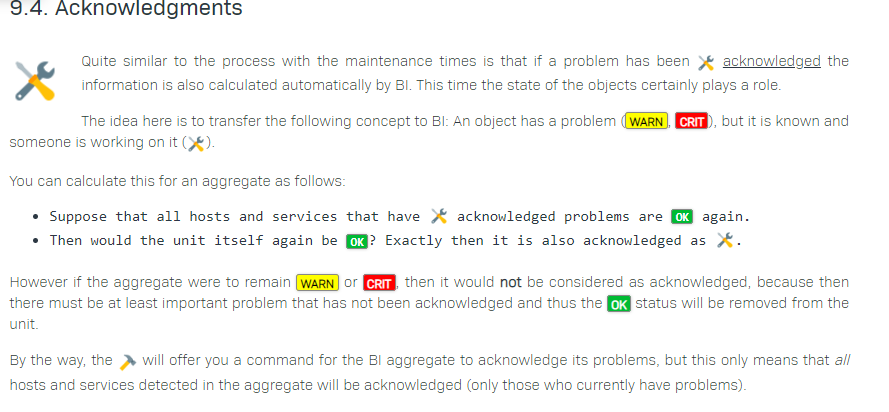
the manual is correct, it’s just formulated a bit terse. If you consider the two bullets carefully, they describe the behaviour in reference to how OK states are propagated:
An aggregate status is acknowledged if and only if all acknowledged sub-states being considered OK would make the aggregate status OK as well.
Why? Intuitively, an acknowledgement expresses that this problem is known and being worked on. (“The technician is informed”) For an aggregation that is not OK, this can be naturally extended in the following way: “If I ignore all problems that have been acknowledged, would the aggregate status still be non-OK?”
Hmm… maybe you should consider to make the behavior of the BI more flexible by having the option to set the behavior, similar to the point “Aggregation of Downtimes”.