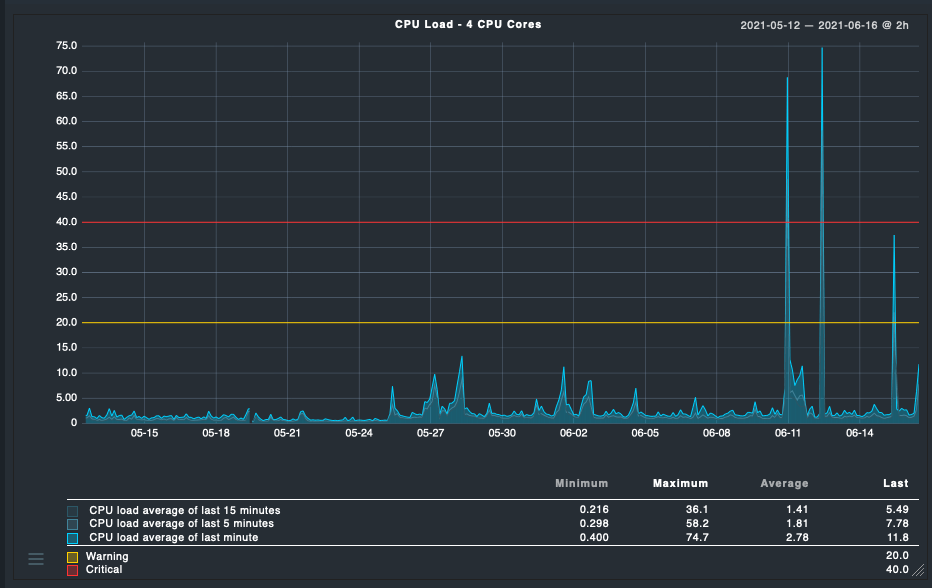
We are using: CMK version : 2.0.0p5 (CEE) OS version : Ubuntu 16.04.7 Number of hosts : 740 Number of services : 15000
CMK is running in AWS, m4.xlarge instance (4 vCPU, 16 GiB)
Under normal conditions CMK is running absolutely fine, but when we face some huge outages (like DB failures, cloud provider outages, internal chaos testing) CMK faces huge delays in processing notifications, and notification processes are using quite big amount of CPU.
During such periods we also face alerts from CMK about site performance (fetcher and helper usage). Not sure, but seems like it’s throttled by notification processes. Some screenshots for CPU load and helper usage:
CFriedrich pagerduty + mail (mails directly from host). I know PagerDuty has throttling limit, but it doesn’t look like we reach it, as soon as I can see only 2xx responses from PagerDuty.
wittmannthom hosts mainly go DOWN state. Services something like 90% CRITICAL and 10% WARNING. But both OK → WARN and OK → CRIT changes are handled by the same notification rule, if it’s important.
Out of the box i’d think there might be too many notification rules doing the same thing.
Can you confirm that that all notification rules which do not handle mails are properly set up? In the past i have seen setups that trigger notifications more than once per hard state and thus caused a “jam”.
Also, what does your ~/var/log/notify.log and ~/var/log/mknotify.log say when this occurs?
I have had Checkmk stalling to a near-stop during large connectivity outages because:
SNMP queries keep a worker process busy while waiting for a response, even if there isn’t one coming (because of the outage)
We do SNMP every five minutes, with a minute timeout, and attempt five retries (that’s 1+5 attempts, times 1 minute, = 6 minutes of waiting on a device in a 5 minute window)
The default worker process count is less than the number of SNMP devices we have
… resulting in Checkmk being totally clocked out waiting on SNMP messages and having no time for real checks.
Possibly you have something similar going on?
We resolved this by increasing the helper process count (under global settings - warning, does slightly increase site restart time (not reload, that’s still fast) so don’t go craaazy with it), reducing the SNMP attempts to 2, and reducing the SNMP timeouts to 30 secs for a particular large group of devices for which I can tolerate slightly less resilient monitoring (though I still have not had problems with them anyway).
We also contemplated having an extra distributed site just for monitoring SNMP devices, so at least the damage will be restricted to a small section of our monitoring. We didn’t end up doing this, but it’s another option.
I’ve learnt that now I inherited this setup from a predecessor who picked some awfully over-cautious settings without fully contemplating/understanding the end effects of them and interplay between them. Although at the same time, I believe some SNMP devices tend to awfully under-deliver when it comes to performance - I don’t think that timeout was raised so high on whim.
I’m not recommending those settings, they did cause us problems, simply describing the scenario under which I had problems with symptoms similar to OP, in the hope that it may provide clues and a direction of investigation.
I our case the problem was because of poorly configured PagerDuty notifications.
Each notification to PagerDuty takes nearly 0.6 seconds. And in out case we had “Notify all contacts of the notified host or service.” option selected. Hosts have 3-5 users in contact group, so this leads to a significant load.
Also, because of the incident_key requests were not duplicated on PagerDuty side, so it was not so obvious.
Creating a separate service user and reconfiguring notification rules to just notify this user should more or less solve the problem. We haven’t had huge failures so far, but at least tests are quite promising.
Ideally, this should be noted somewhere related to PagerDuty because I suffered the same problem.
An additional minor problem with PagerDuty is that it does not deal with Downtime related notifications by default, and the pagerduty_event_type dictionary needs to be expanded to deal with it.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.