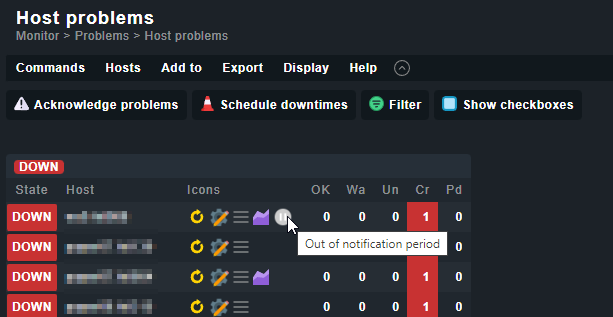
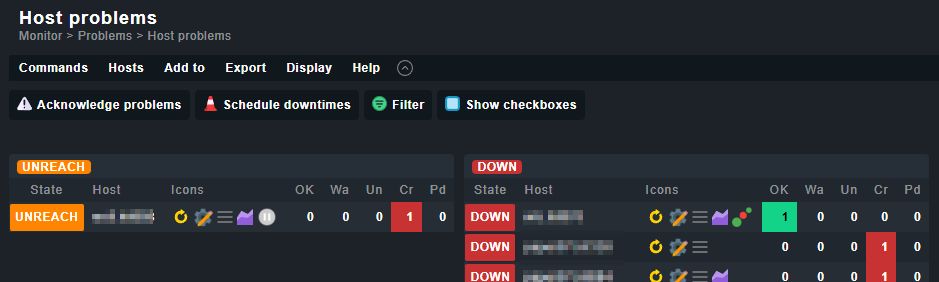
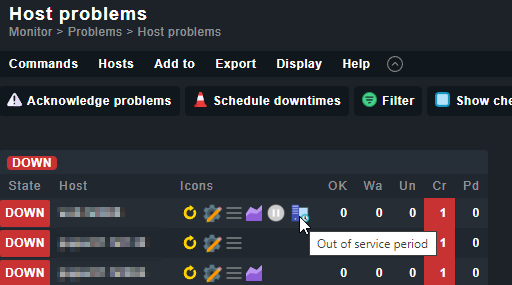
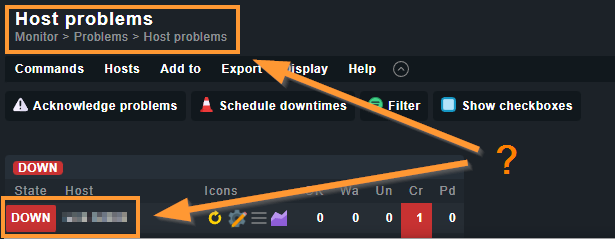
I am monitoring some hosts which aren’t online all the time. But it should be directly visible if they have the state DOWN, so I don’t want to add a rule which sets them permanently to UP. Instead I like to avoid producing problems which needs to be acknowledged.
Is it possible to “Auto-acknowledge all host problems of hosts …” or something like “Ignore problems of hosts …”?
At the moment I solved it by setting them into a 10 year downtime. This works, but does not feel right.
I’m not sure, but I think I found the correct way, but it is interpreted wrong by CheckMK:
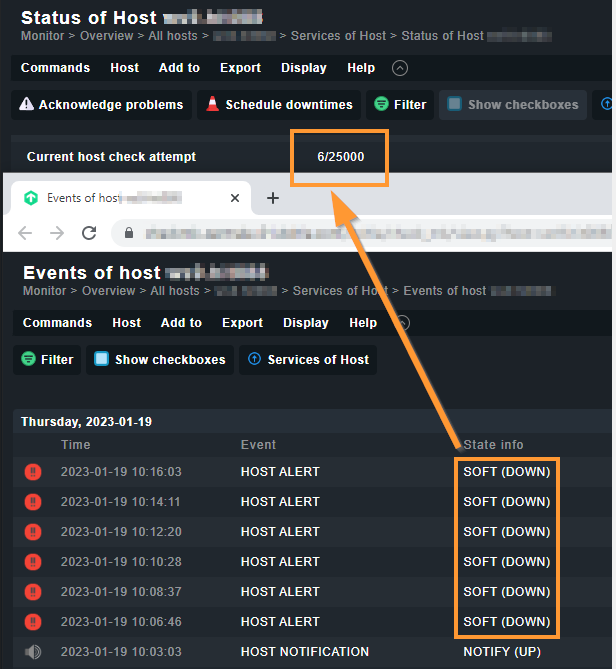
I changed the “Normal check interval for host checks” to 44 seconds
I changed the “Maximum number of check attempts for host” to 25000
By that every 110 seconds (44 seconds x 2,5 intervals) a Host State Change is triggered and as the maximum is 25000 its host state changes from “SOFT (DOWN)” to “HARD (DOWN)” after around one month (25000 seconds x 110 seconds = 31.8 days).
By that the host check attempt counts upwards as expected:
Its the standard Nagios behavior. First its an soft alert and after reaching max check attempts it change to a hard state. A hard state trigger a notification.
Thats what it is doing. What are you missing?
Yes, you can do this with an alert handler and livestatus.
Can you explain in detail what you expect? What do you want to “ignore”
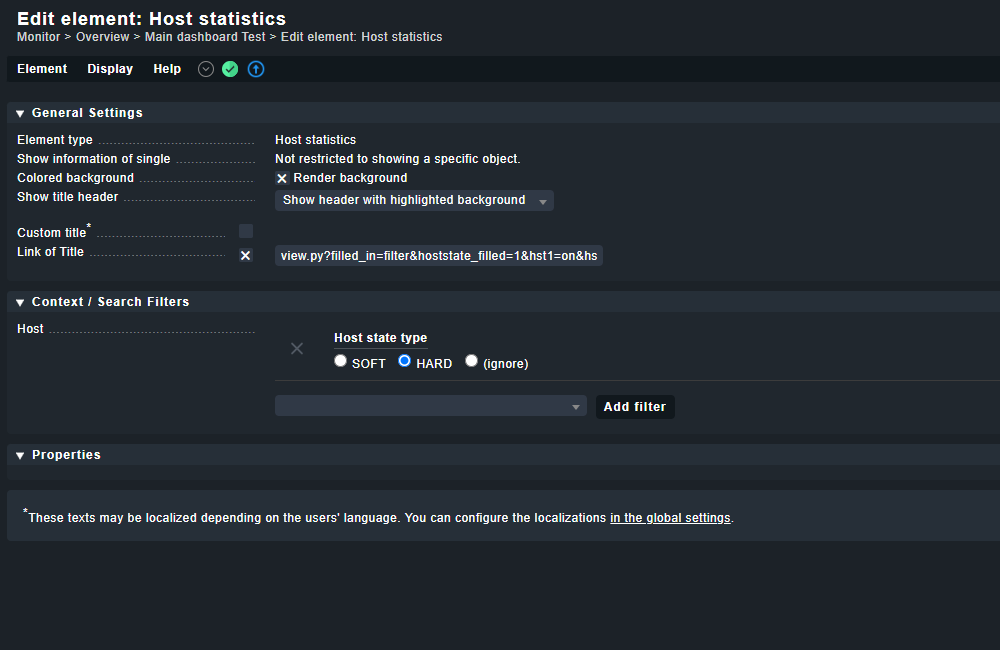
Ok, this means I could replace the default “hostproblems” view with a custom view which contains an additional filter. If this is possible, it’s worth a try.
Hmm, this could cause confusion in the team “Ok, there are still problems left … loading list … no problems found”. “Hey mgutt, solve this bug in the sidebar”
Do you now confirm my opinion regarding “the soft state already triggers an unhandled problem, which I think is incorrect”? Then I would open a feature request regarding this.
As a remedy you may disallow this sidebar snapin in the user role. This way you force the user to use your custom dashboard. Maybe another community member knows a way to customize the snapin.
No I do not agree.
The behavior is exactly what we have since more than 20 years in nagios and the community is used that
way. Nevertheless in checkmk you can customize the views and dashboards to make it work as you expect.
I’d say … instead of fiddling with views, periods, soft/hard states, etc.:
just put these hosts in an “everlasting” downtime and all is fine. keep it simple.
On Enterprise edition, instead of a downtime for the next say 10 years, you could also create a “recurring downtime” rule for these hosts with say downtime for 1 month, repeating monthly.
Same result, but you (or your future colleagues) won’t have a surprise in 10 years from now in their then “legacy” monitoring system
From my perspective i would just set disabled notification to this host/service and exclude them from the default view of host/service problems. Nearly as simple as a endless downtime but more the right way in my opinion. This also enables you to search for these host/services especially via some host tags. I guess they are handily built-in, if i am not wrong.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.