CMK version: Checkmk Enterprise Edition 2.2.0p21
I have a small Kubernetes cluster with three control planes and no worker nodes. Currently there isn’t much workload, so everything can run on one node. When I drain two of the three nodes, I see two issues with the Kubernetes checks in CheckMK:
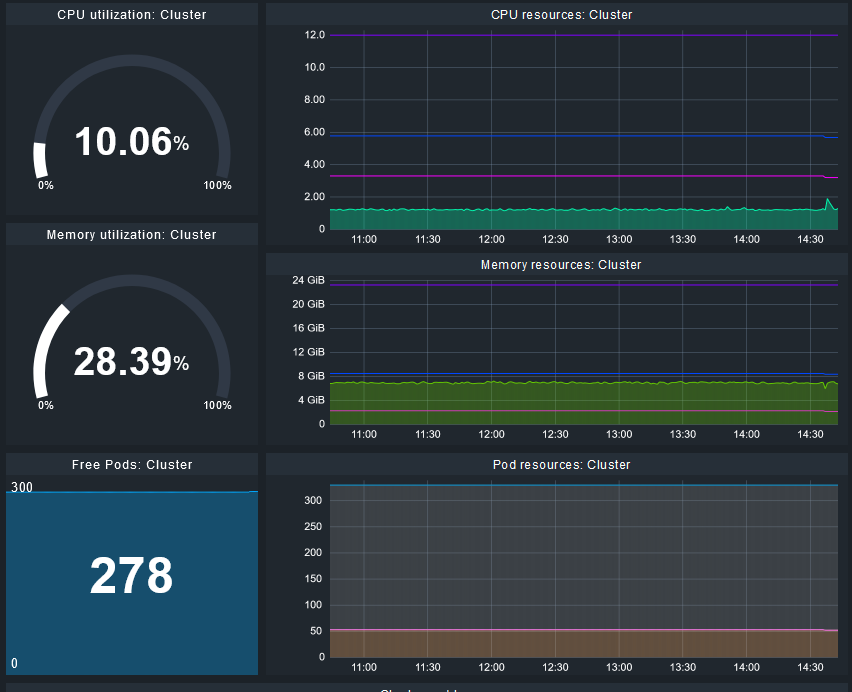
- Actually I don’t see any issue. Everything is still ok. This doesn’t feel right to me as there’s no redundancy in the cluster now.
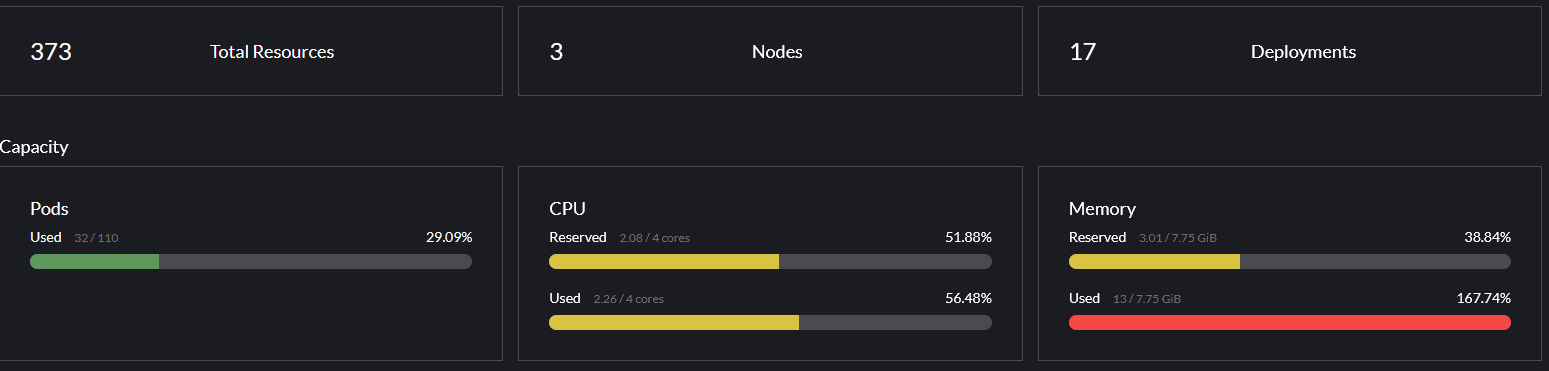
- CPU resources, memory resources and free pods behave as if all nodes are ready to schedule. Rancher handles it “the right ways” IMO:
You can probably argue about the first thing. In an enviroment with dynamic node management it might be intended when a node is drained, but for me this is an indicator for an upcomming issue.
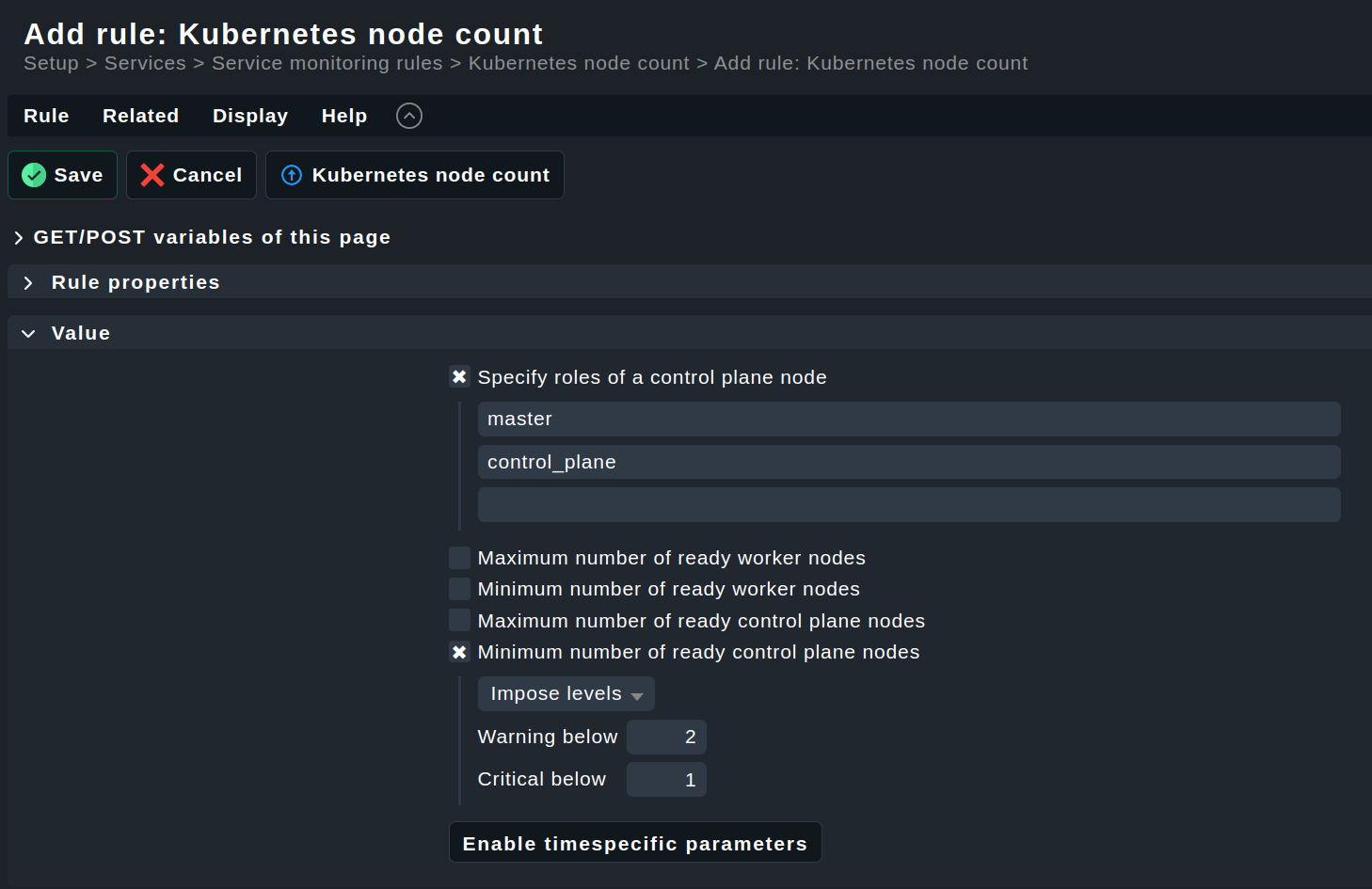
Maybe enhance the check “Nodes” by updating “Control plance nodes ready” to “Control plance nodes ready and scheduling enabled”?
The issue here is, that the nodes are still Ready, but also SchedulingDisabled:
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node-01 Ready control-plane,etcd,master 68d v1.27.11+rke2r1 10.0.4.79 <none> Ubuntu 22.04.4 LTS 5.15.0-105-generic containerd://1.7.11-k3s2
node-02 Ready,SchedulingDisabled control-plane,etcd,master 64d v1.27.11+rke2r1 10.0.4.80 <none> Ubuntu 22.04.4 LTS 5.15.0-105-generic containerd://1.7.11-k3s2
node-03 Ready control-plane,etcd,master 64d v1.27.11+rke2r1 10.0.4.81 <none> Ubuntu 22.04.4 LTS 5.15.0-105-generic containerd://1.7.11-k3s2
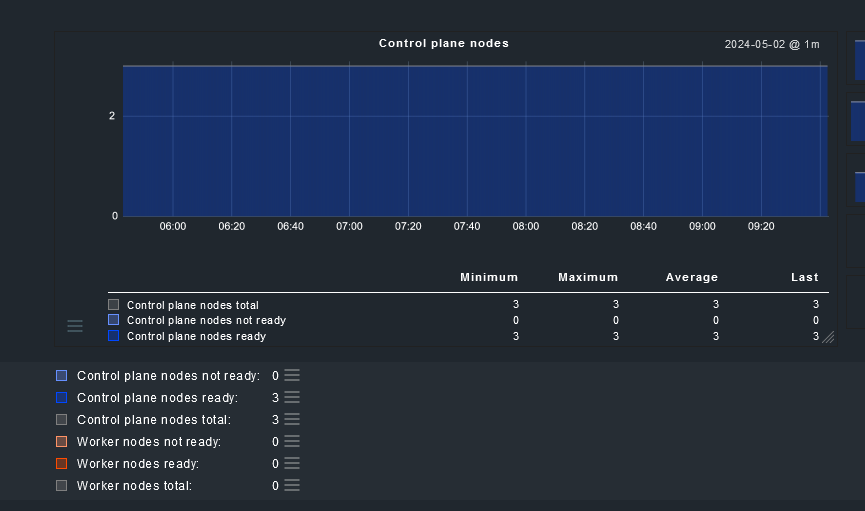
Thus they are counted as ready in CheckMK and are indistinguishable from nodes that are really ready:
I send you kubectl describe node via PM.
Thanks! It is sth. I have to discuss internally. I share your view, that they are basically irrelevant. But have to discuss with the team as not counting them as ready is also not correct. Introducing a third state also is not right.