Hi @marbaa
OK, now I get what you mean, and what your initially posted problem is. As far as I understand, I have to say that your “issue” is more of a “cosmetic” nature. I believe that this can easily be overcome by good internal documentation and communication regarding this particular check, but… I may be wrong. I know: people can be weird, and not be able to “tolerate” this “duplicated output”. Seriously though: Is that such a big deal? 
In any case, I did some very brief research about MapR and what I found, is perhaps not really news to you, but that thing has apparently its own CLI (maprcli) one could probably (ab)use to write a check that will do what you want:
https://docs.datafabric.hpe.com/62/ReferenceGuide/maprcli-REST-API-Syntax.html
There is a myriad of commands, such as node list or dashboard info which do look useful… maybe others, too. I’m sure as someone who is working with that thing, such as yourself, you’ll have some experience with it, and will be able to find the right combination of commands to achieve what you want: It shouldn’t be too hard to do.
In summary
What you need to code into your script - whether you want to use it as local check or via MRPE - is some sort of condition, that, in case both your nodes are active, only generates the output you posted above, on one of them… which is what Andreas already said above. This shouldn’t lead to those “pesky” duplicates anymore.
I wanted to add that you will not find any documentation on how to do that, because it strictly depends on the application you want to write it for (in your case: that MapR thingie…): Without wanting to sound rude, you will need to come up with the logic. Again, the existing CLI toolbox should provide plenty of stuff to play around with.
Oh and by the way - quoting myself - the tip to use
does do something useful, but… perhaps not for your case, so I’m sorry if I misled you with that advice. With all that said, I sincerely hope that you will come up with a satisfying solution for your issue, and please do post your results: I’m sure they will provide helpful advice for similar issues others have…
Thomas

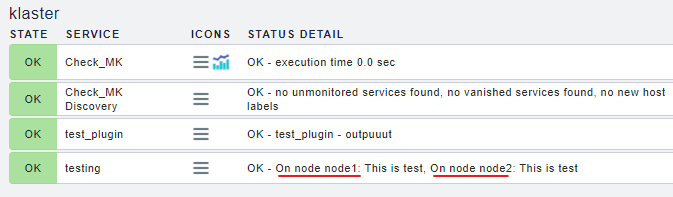
 Probably I don’t understand docu correctly and don’t understand correctly what to use for my need.
Probably I don’t understand docu correctly and don’t understand correctly what to use for my need.
 the way how they are collected is not relevenat.
the way how they are collected is not relevenat.