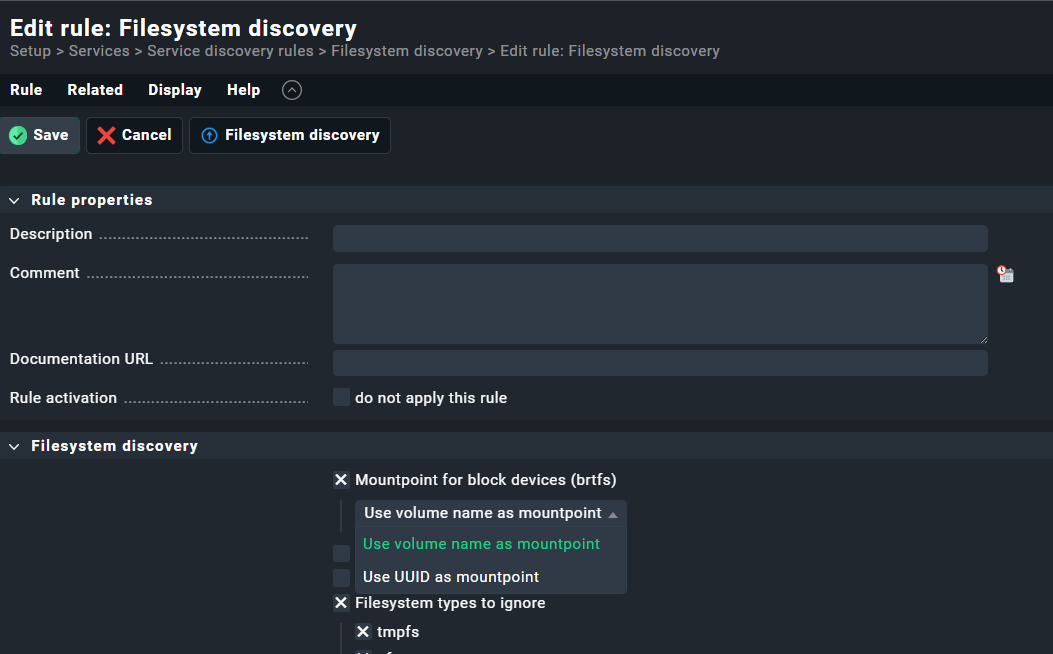
Output of check_mk_agent on the HAOS host:
<<<check_mk>>>
Version: 2.4.0p18
AgentOS: linux
Hostname: a0d7b954-ssh
AgentDirectory: /etc/check_mk
DataDirectory: /var/lib/check_mk_agent
SpoolDirectory: /var/lib/check_mk_agent/spool
PluginsDirectory: /usr/lib/check_mk_agent/plugins
LocalDirectory: /usr/lib/check_mk_agent/local
OSType: linux
OSName: Alpine Linux
OSPlatform: alpine
OSVersion: 3.22.2
FailedPythonReason:
SSHClient:
<<<checkmk_agent_plugins_lnx:sep(0)>>>
pluginsdir /usr/lib/check_mk_agent/plugins
localdir /usr/lib/check_mk_agent/local
<<<labels:sep(0)>>>
{"cmk/device_type":"container"}
<<<nfsmounts_v2:sep(0)>>>
<<<cifsmounts>>>
<<<mounts>>>
/dev/xvda8 /ssl ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /media ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /share ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /backup ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /homeassistant ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /addon_configs ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /data ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /addons ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /run/audio ext4 ro,relatime,commit=30 0 0
/dev/xvda8 /etc/asound.conf ext4 ro,relatime,commit=30 0 0
/dev/xvda8 /run/cid ext4 ro,relatime,commit=30 0 0
/dev/xvda8 /etc/resolv.conf ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /etc/hostname ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /etc/hosts ext4 rw,relatime,commit=30 0 0
/dev/xvda8 /var/log/journal ext4 ro,relatime,commit=30 0 0
/dev/xvda8 /etc/pulse/client.conf ext4 ro,relatime,commit=30 0 0
<<<ps_lnx>>>
[time]
1767352878
[processes]
[header] CGROUP USER VSZ RSS TIME ELAPSED PID COMMAND
- root 440 100 00:00:00 09:16:33 1 /package/admin/s6/command/s6-svscan -d4 -- /run/service
- root 220 80 00:00:00 09:16:32 19 s6-supervise s6-linux-init-shutdownd
- root 208 60 00:00:00 09:16:32 21 /package/admin/s6-linux-init/command/s6-linux-init-shutdownd -d3 -c /run/s6/basedir -g 3000 -C -B
- root 220 76 00:00:00 09:16:32 30 s6-supervise ttyd
- root 220 72 00:00:00 09:16:32 31 s6-supervise s6rc-fdholder
- root 220 76 00:00:00 09:16:32 32 s6-supervise sshd
- root 220 76 00:00:00 09:16:32 33 s6-supervise s6rc-oneshot-runner
- root 208 68 00:00:00 09:16:32 41 /package/admin/s6/command/s6-ipcserverd -1 -- /package/admin/s6/command/s6-ipcserver-access -v0 -E -l0 -i data/rules -- /package/admin/s6/command/s6-sudod -t 30000 -- /package/admin/s6-rc/command/s6-rc-oneshot-run -l ../.. --
- root 6704 4696 00:00:01 09:16:31 305 sshd: /usr/sbin/sshd -D -e [listener] 0 of 10-100 startups
- root 7884 2844 00:00:00 09:16:31 308 ttyd -d1 -i hassio --writable -p 64851 tmux -u new -A -s homeassistant zsh -l
- root 7168 5112 00:00:00 08:33 73224 sshd-session: hassio [priv]
- hassio 7468 4032 00:00:00 08:33 73226 sshd-session: hassio@pts/0
- root 1936 1504 00:00:00 08:32 73227 sudo -i
- root 1936 852 00:00:00 08:32 73229 sudo -i
- root 4612 4336 00:00:02 08:32 73230 -zsh
- root 3480 2836 00:00:00 00:00 75605 /bin/bash ./check_mk_agent
- root 3496 2460 00:00:00 00:00 75622 /bin/bash ./check_mk_agent
- root 3452 2388 00:00:00 00:00 75624 /bin/bash ./check_mk_agent
- root 1688 928 00:00:00 00:00 75626 cat
- root 3496 2340 00:00:00 00:00 75641 /bin/bash ./check_mk_agent
- root 2844 1908 00:00:00 00:00 75642 ps ax -ww -o cgroup:512,user:32,vsz,rss,cputime,etime,pid,command
- root 1628 844 00:00:00 00:00 75643 tr -s
<<<docker_container_mem_cgroupv2>>>
anon 8572928
file 41893888
kernel 16797696
kernel_stack 344064
pagetables 864256
sec_pagetables 0
percpu 960
sock 0
vmalloc 0
shmem 0
zswap 0
zswapped 0
file_mapped 5906432
file_dirty 4096
file_writeback 0
swapcached 0
inactive_anon 0
active_anon 8548352
inactive_file 9936896
active_file 31956992
unevictable 0
slab_reclaimable 14833896
slab_unreclaimable 519960
slab 15353856
workingset_refault_anon 0
workingset_refault_file 0
workingset_activate_anon 0
workingset_activate_file 0
workingset_restore_anon 0
workingset_restore_file 0
workingset_nodereclaim 0
pgdemote_kswapd 0
pgdemote_direct 0
pgdemote_khugepaged 0
pgscan 0
pgsteal 0
pgscan_kswapd 0
pgscan_direct 0
pgscan_khugepaged 0
pgsteal_kswapd 0
pgsteal_direct 0
pgsteal_khugepaged 0
pgfault 13460159
pgmajfault 287
pgrefill 0
pgactivate 0
pgdeactivate 0
pglazyfree 0
pglazyfreed 0
swpin_zero 0
swpout_zero 0
zswpin 0
zswpout 0
zswpwb 0
memory.current 67325952
memory.max max
MemTotal: 3025580 kB
<<<docker_container_cpu_cgroupv2>>>
uptime 33406.87 31688.80
num_cpus 1
usage_usec 110325155
user_usec 57559752
system_usec 52765403
nice_usec 4000
nr_periods 0
nr_throttled 0
throttled_usec 0
nr_bursts 0
burst_usec 0
<<<uptime>>>
33404
<<<lnx_if>>>
[start_iplink]
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP qlen 1000
link/ether 00:16:3e:f2:93:d2 brd ff:ff:ff:ff:ff:ff
inet 192.168.200.2/24 brd 192.168.200.255 scope global dynamic noprefixroute enX0
valid_lft 571403sec preferred_lft 571403sec
inet6 fe80::188f:a3de:9a13:e9cc/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 0e:2d:40:0c:28:ed brd ff:ff:ff:ff:ff:ff
inet 172.30.232.1/23 brd 172.30.233.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::c2d:40ff:fe0c:28ed/64 scope link
valid_lft forever preferred_lft forever
4: hassio: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 66:03:e9:e6:e3:d0 brd ff:ff:ff:ff:ff:ff
inet 172.30.32.1/23 brd 172.30.33.255 scope global hassio
valid_lft forever preferred_lft forever
inet6 fe80::6403:e9ff:fee6:e3d0/64 scope link
valid_lft forever preferred_lft forever
5: veth9f14b13@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether 9e:b5:c6:4a:a6:07 brd ff:ff:ff:ff:ff:ff
inet6 fe80::9cb5:c6ff:fe4a:a607/64 scope link
valid_lft forever preferred_lft forever
6: vethdccf4dd@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP
link/ether 16:d4:ab:8b:3b:da brd ff:ff:ff:ff:ff:ff
inet6 fe80::14d4:abff:fe8b:3bda/64 scope link
valid_lft forever preferred_lft forever
7: veth1192fe3@docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether e2:5b:14:39:b6:5e brd ff:ff:ff:ff:ff:ff
inet6 fe80::e05b:14ff:fe39:b65e/64 scope link
valid_lft forever preferred_lft forever
8: veth26f9732@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether c2:32:1e:ab:93:38 brd ff:ff:ff:ff:ff:ff
inet6 fe80::c032:1eff:feab:9338/64 scope link
valid_lft forever preferred_lft forever
9: veth2f9876b@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether 62:87:91:32:8b:21 brd ff:ff:ff:ff:ff:ff
inet6 fe80::6087:91ff:fe32:8b21/64 scope link
valid_lft forever preferred_lft forever
10: veth7f10837@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether ae:41:62:62:7d:a4 brd ff:ff:ff:ff:ff:ff
inet6 fe80::ac41:62ff:fe62:7da4/64 scope link
valid_lft forever preferred_lft forever
11: veth6c16f62@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether 9a:3a:2a:0a:3b:d0 brd ff:ff:ff:ff:ff:ff
inet6 fe80::983a:2aff:fe0a:3bd0/64 scope link
valid_lft forever preferred_lft forever
12: veth0788af3@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether de:79:da:c4:3c:8b brd ff:ff:ff:ff:ff:ff
inet6 fe80::dc79:daff:fec4:3c8b/64 scope link
valid_lft forever preferred_lft forever
13: veth027ce25@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether da:66:f9:5d:82:62 brd ff:ff:ff:ff:ff:ff
inet6 fe80::d866:f9ff:fe5d:8262/64 scope link
valid_lft forever preferred_lft forever
14: vethe64e8f5@enX0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master hassio state UP
link/ether b2:25:63:a3:88:6a brd ff:ff:ff:ff:ff:ff
inet6 fe80::b025:63ff:fea3:886a/64 scope link
valid_lft forever preferred_lft forever
[end_iplink]
<<<lnx_if:sep(58)>>>
lo: 2984551 12424 0 0 0 0 0 0 2984551 12424 0 0 0 0 0 0
enX0: 680135059 1342789 0 0 0 0 0 0 118169041 1316766 0 0 0 0 0 0
docker0: 200916 917 0 0 0 0 0 0 473451 861 0 2 0 0 0 0
hassio: 67669145 289636 0 0 0 0 0 0 227576053 272916 0 2 0 0 0 0
veth9f14b13: 1661580 9177 0 0 0 0 0 0 3983615 19155 0 0 0 0 0 0
vethdccf4dd: 213754 917 0 0 0 0 0 0 476106 876 0 0 0 0 0 0
veth1192fe3: 497466963 268976 0 0 0 0 0 0 228316350 282805 0 0 0 0 0 0
veth26f9732: 2022 14 0 0 0 0 0 0 1499251 10151 0 0 0 0 0 0
veth2f9876b: 3640307 34960 0 0 0 0 0 0 4360914 34495 0 0 0 0 0 0
veth7f10837: 126 3 0 0 0 0 0 0 1495791 10141 0 0 0 0 0 0
veth6c16f62: 4258 40 0 0 0 0 0 0 1501626 10150 0 0 0 0 0 0
veth0788af3: 3791125 19915 0 0 0 0 0 0 1527561 10891 0 0 0 0 0 0
veth027ce25: 3162834 33280 0 0 0 0 0 0 433349740 42817 0 0 0 0 0 0
vethe64e8f5: 2897 28 0 0 0 0 0 0 1481946 10083 0 0 0 0 0 0
[lo]
Address: 00:00:00:00:00:00
[enX0]
Address: 00:16:3e:f2:93:d2
[docker0]
Speed: 10000Mb/s
Address: 0e:2d:40:0c:28:ed
[hassio]
Speed: 10000Mb/s
Address: 66:03:e9:e6:e3:d0
[veth027ce25]
Speed: 10000Mb/s
Address: da:66:f9:5d:82:62
[veth0788af3]
Speed: 10000Mb/s
Address: de:79:da:c4:3c:8b
[veth1192fe3]
Speed: 10000Mb/s
Address: e2:5b:14:39:b6:5e
[veth26f9732]
Speed: 10000Mb/s
Address: c2:32:1e:ab:93:38
[veth2f9876b]
Speed: 10000Mb/s
Address: 62:87:91:32:8b:21
[veth6c16f62]
Speed: 10000Mb/s
Address: 9a:3a:2a:0a:3b:d0
[veth7f10837]
Speed: 10000Mb/s
Address: ae:41:62:62:7d:a4
[veth9f14b13]
Speed: 10000Mb/s
Address: 9e:b5:c6:4a:a6:07
[vethdccf4dd]
Speed: 10000Mb/s
Address: 16:d4:ab:8b:3b:da
[vethe64e8f5]
Speed: 10000Mb/s
Address: b2:25:63:a3:88:6a
<<<tcp_conn_stats>>>
01 19
06 58
0A 17
<<<docker_container_diskstat_cgroupv2>>>
[time]
1767352878
[io.stat]
202:0 rbytes=41234432 wbytes=851968 rios=1983 wios=154 dbytes=0 dios=0
[names]
loop0 7:0
loop1 7:1
loop2 7:2
loop3 7:3
loop4 7:4
loop5 7:5
loop6 7:6
loop7 7:7
xvda 202:0
zram0 252:0
zram1 252:1
zram2 252:2
<<<md>>>
Personalities :
unused devices: <none>
<<<vbox_guest>>>