Hello everyone, since we migrated our check mk to version 2.0 we have some problems, all checks go in stale and we do not understand why, to solve the problem we had to create a new instance, anyone has any idea what could be?
Hi @lucafound and welcome to the checkmk community.
Could you please provide us with some more information to have some points to dig into your problem? Maybe the exact version is a beginning and maybe some performance values of your monitoring, like server performance, amount of hosts and services your are monitoring, …
Hello, we have several servers each with about 200 hosts, but the problem occurs randomly and so far has happened on two servers, in the first we solved by recreating the site, in the second (which incidentally has only 70 hosts) we are still deciding what to do to solve, specifically this server has version 2.0p9 (I rollback from 2.0p15 to understand if the problem was the update) with:
Hosts 73
Services 3023
Services in Stale 2934
It’s like the scheduler doesn’t work anymore and he doesn’t check the various services anymore.
Thanks in advance.
Can you please show the server performance from the sidebar? Maybe some global settings are not appropriate for the amount of hosts/services anymore. Also please check if something on the master control is switched of. It seems like no passive service check is done so far. Can you also check if all services of you site are running by executing omd status on the command line as site user?
Hello, I already checked the status, i try to restart the server too but the issue is still present.
mkeventd: running
rrdcached: running
npcd: running
nagios: running
apache: running
redis: running
xinetd: running
crontab: running
Overall state: running
How can i show the server performance? Do you mean the top command on the server?
There should be a sidebar snapin showing your overall site performance and give some hints if the site is properly configured. Should looks similar like:
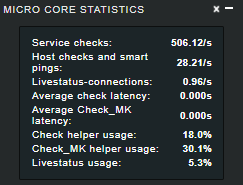
(from older version and enterprise edition)
Also check the master control:
Ok, I found these panels:
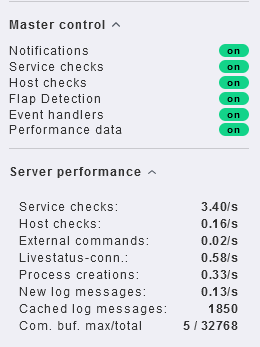
Looks normal to me.
Can you show the service view of a host with this problem? Especially the check_mk.* services?
What happens if you manually reschedule the service checks of a host?
Hello,
Sorry for delay, when I refresh manually the checks nothing happens.
Here is an example of some check in stale:
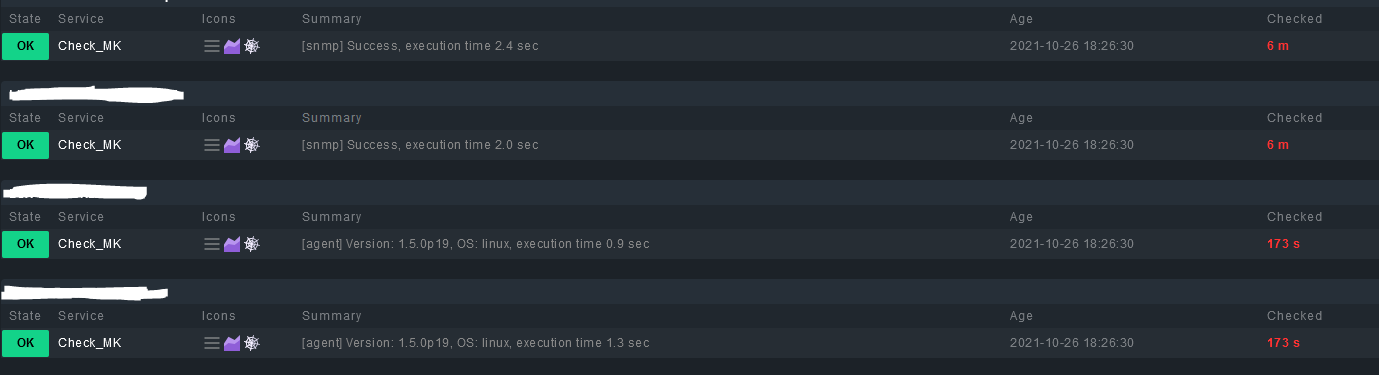
Regards
The curious thing in your picture ist the Checked (last check time) value. There is something blocking the check of your services or the parsing of the results.
Can you please check the general performance of your server? Also take a look into the log files if something conspicuously appears there.
From the number of your services monitored, your server should check at least around 50 services per second but your performance snapin shows only 3.4/s.
I have already done a check on the server and it is very unloaded, the CPU and the Memory are very unloaded, so it should not be a server problem. We also have other machines identical to this one that have about 200 hosts and 6000 services each and do not suffer from this problem while having the same configuration and the same version of check mk installed
@andreas-doehler, @r.sander any ideas where to locate the problem? I am out of ideas.
I add that on another server I had the same problem and resolved by copying the site with the omd cp command and deleting the old site.
Before checkmk 2.0 I never had a similar problem
This problem looks like “only” a Nagios core problem.
First step i would do for troubleshooting is a look inside the nagios.log file.
If there is nothing inside then the next step is to check with an “cmk -vv hostname” if a check triggered on the command line leads to valid check results.
If the manual made check results are transferred to the core then only the “Check_MK” service stays in stale all the other services (non active ones) should have an actual check result.
From the screenshot - is there only the “Check_MK” service stale on this hosts?
What says a “cmk --debug -vvR” on the command line? No errors or warnings?
I would do these tests with an actual p15 version of 2.0.
1 Like
What ist the value of num_client_threads in./etc/nagios/nagios.d/mk-livestatus.cfg.
We have changed it from 20 to 80. (500 hosts)
Perhaps this solves the problem.
Hello everyone and thank you so much for your suggestions,
with the command “cmk -vv hostname” from the cli we receive a correct answer and no errors, the services that went in stale were not only “Check_mk” as in the screenshot but also others, within the file nagios.log we did not find any particular error.
With the command “cmk --debug -vvR” the problem seems to be solved, we are observing the behavior of the site that seems to be fine now, in any case we try to modify also the parameter num_client_threads in. /etc/nagios/nagios. d/mk-livestatus.cfg. and we will update you
Hi,
I’m experiencing the same problem, I have just installed from scratch this version: check-mk-raw-2.1.0p3_0.jammy_amd64.deb
I have 23 hosts and 746 services, I always have stale services that eventually get completed but there is always something stale.
The "Service checks: " values from performance never goes above 13/s
“cmk -vv hostname” lead to a valid check result
“cmk --debug -vvR” doesn’t give any error or warnings
I have also tried to change num_client_threads in ./etc/nagios/nagios.d/mk-livestatus.cfg from 20 to 80 but still the same problem
how can increase the volume of serice check per second? The CPU goes at maximum at 20%
@andreas-doehler @r.sander any idea?
Thank you
Here are the performance with all the server just restarted
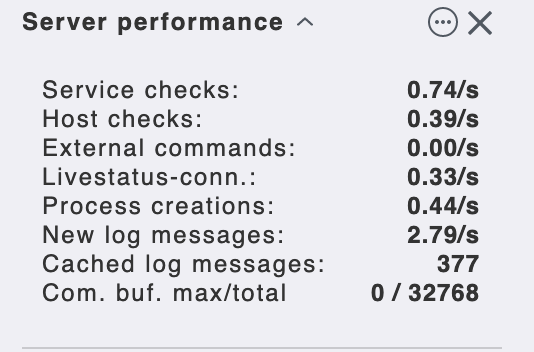
Update: I have noticed that now the stale service are always the same 4 hosts that took about 40secs to complete the execution of the agent. While I was adding new host all the server systems seems blocked, maybe the cause was this stale services that was blocking also the pending service of new hosts?
If I change some rules for example I have 300 services in stale with a Service checks: of 7/s or 8/s
This setting is only relevant in bigger sites with many web users.
That’s perfectly fine → 746 services divided with 60 seconds → 12,4
Then you have a agent configuration problem. A proper configured agent should not need more than 3-4 seconds to complete. SNMP devices are a different subject for the runtime.
2 Likes
Thank you very much for your reply, I have removed some local check that was slow and now I don’t have stale services
Thank you
If you configure the local checks as cached or asynchron it would also help.
1 Like