we have set notifications delay for services, but it doesn’t apply to clustered services on a virtual host without IP, once a service gets critical it immediately goes to a hard state and triggers an alert. Now we’ve disabled the notification delay rules, apparently due to issues with notification delay and virtual hosts and setup the following instead:
Maximum number of check attempts for service: 5
Retry check interval for service checks: 1 minute
Normal check interval for service checks: 1 minute
but still the service goes critical and a hard state is triggered and a notification is sent, this is very annoying and creating a spam of notifications. These clustered services are the same local checks on each member of the virtual host with the aggregation option of Best node wins. The check provides the same output from each host.
Is there anyway to apply this kind of delay for clustered services on virtual hosts without IP? For hosts with an actual IP in CheckMK it is working as expected.
Nevertheless what is the best practice to achieve this, using delay notification or the check attempts and the retry check interval way for normal hosts as well as for virtual hosts?
All hostnames are custom and not FQDN but they are configured with the host IP.
i tested it with checkmk 2.4p19 and the amount of check attempts and it works as expected:
Are the services in question attached to the cluster host and removed from the cluster nodes correctly ?
When you configure the nr of check attempts for the services, do you see the correct value in the Service Overview of that service on the cluster object (when clicking the service you will find it in the resulting table “current check attempt x/y) ?
Do you have configured the correct rule, as there is one for the host and one for the services ?
yes all the clustered services are attached to the virtual host correctly
not at the beginning, we had delay service notification in the beginning, only later on after we fixed the issue with this service and setup the max check attempts
yes, sure
while we had the delay service notification without the max check attempts, the service was in SOFT (WARNING) state, then it went to HARD (CRITICAL) and the alerts was immediately triggered, it was a false positive and it went back to SOFT (WARNING) in a few seconds, an hour later it went again to HARD (CRITICAL) and the alert was also immediately triggered without respecting the delay time. I read somewhere in the forum that the delay notification only works for the first notification but not for the subsequent ones from the same service, only if it got back to HARD (OK), the delay works again.
Furthermore the hostnames are custom, but are setup with IPv4 address, the virtual host is also a custom hostname without IP. This could influence the notification delay as I read here in the forum, not sure though.
So I decided to disable all delay notification rules and setup the max check attempt with the retry check interval to give critical states enough time to recover if it is a false positive.
I saw in this setup that the service state never reaches HARD (CRITICAL) unless the max check attempts are reached, but it only worked after fixing the SOFT (WARNING) state of this service to become HARD (OK) again, because it always fell to HARD (CRITICAL) from SOFT (WARNING), so both ways (delay/check attempts) would immediately trigger an alert because the notification triggering state is reached → HARD (CRITICAL) as I understood.
For all other services the process was correct, it reaches the HARD (CRITICAL) only if the max check attempts were exhausted.
As for delay notifications without the max check attempts, if a service goes critical, it immediately becomes HARD (CRITICAL) and the notification is triggered after the delay time was reached. So for me it looks like how the delay/check attempts work with the service state SOFT/HARD if I am not mistaken.
Now I could verify that the max check attempts also don’t solve our problem.
We notify only critical states of some services
if a service goes soft (warning) the counter starts !!!
after max check attempts is reached it become hard (warning)
service goes to critical, it immediately becomes hard (critical) and the alert is triggered
it seems the max check attempts counts both states (warning/critical) until it gets hard, but we want to wait for the hard (critical) alert 5 minutes, always, also for the subsequent alerts, because it could be always a false positive, that could fix itself by the next check period.
The main problem with delay service notification is that each subsequent state change of the service from warning → critical triggers the alert immediately and doesn’t respect the delay time, if the service state never went to OK.
So the general question would be:
Is it possible to delay all critical alerts for 5 minutes, even critical alerts for subsequent state change, even if the service state toggles between warning and critical without becoming OK in between, so all notifications are sent only after the delay time has expired?
That is completely correct behavior. Warning state does not mean soft state. A soft state means only that maximum number of check attempts was not reached.
This is expected.
That is also normal for every other check not only clustered services.
If i service has reached a hard state also a state change from warning to critical or from warning to unknown does not change the state back to soft.
Delay times only count from OK to any other state not between bad states. That is also for every check the same.
I think it is possible. First i would define a rule.
What i cannot say without live testing is, reaches the counter of the notification sent 0 again without OK state. This you can see inside your current notifications inside the “Analyze recent notifications”.
we have set this in the notification setup: Service events → State change: any → critical
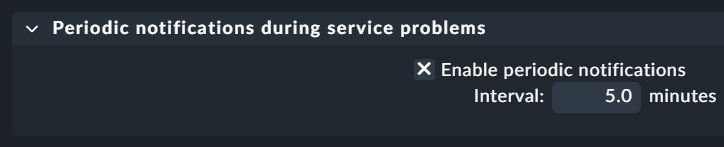
we set 30 minutes for the interval for periodic notifications during service problem to avoid notification spam while it is not fixed. If the fix takes more than 30 minutes we setup a downtime until it is fixed otherwise the alert will be triggered again in 30 minutes if not fixed.
would this setting still have the effect of delaying subsequent notifications that between warning and critical?
take the following example:
```
A service (CPU load) is in warning state for 20 minutes, then it goes to critical only for 3-4 minutes and recovers gets back to warning, regardless of how often the service toggle between warning and critical, no alerts should be sent, as long as delay time is not reached.
```
This is a case where we don’t notifications, because the on a DB host for instance, this could happen regularly. So we set the delay time exactly to avoid this.
For services that get critical for the first time, the delay time is respected, but not the subsequent critical states (in our case).
These are general rules:
delay service notifications: 5 minutes
Periodic notifications during service problems: 30 minutes
Normal check interval for service checks: 1 minute
Notifications rule:
Triggering events: Service events → State change: from any to critical
Service groups: selected service groups for notifications
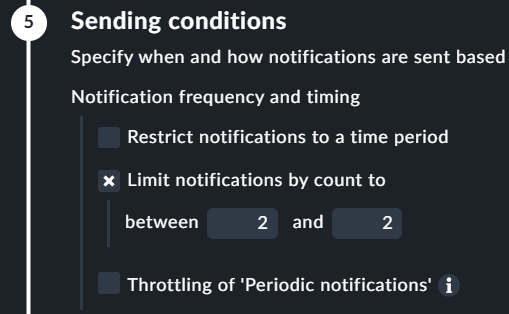
Would the limit notifications by count help in this regard?
The difference is to define when you monitoring system is generating notifications. In your case you have way more then really needed. And also you cannot count the notification number correctly.
will differently do, I just need to be sure about the setup:
So I keep:
delay service notifications: 5 minutes
Periodic notifications during service problems: 30 minutes
Normal check interval for service checks: 1 minute
and replace the rule in the notification system:
Service events → State change: any → critical
With this one:
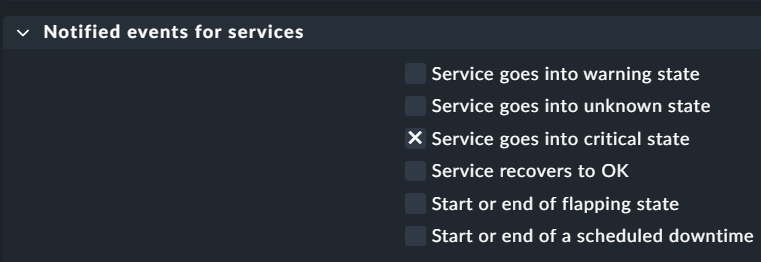
Notified events for services: Service goes into critical state?
I need to mention the 30 minutes are to avoid spam during service problems.
delay service notifications: 5 minutes
when ever a service goes to critical wait 5 minutes before sending the notification, just in case it is a false positive and will recover within 5 minutes.
Periodic notifications during service problems: 30 minutes
the service is already in critical, but it takes a while until it is fixed, so wait 30 minutes for the next notification for the same service, which is still in critical state.
This is meant while the state remains in critical for the 30 minutes as I understood it.
The only issue we have as I described,:
if a service goes critical for >= 5 minutes → send notification → all good
service goes to warning → no notification → all good
ISSUE: same service goes to from warning to critical again → notification is sent immediately, without the delay of 5 minutes > not good, critical state should generally remain for >= 5 minutes before sending notification during a state change to critical. This happen when a service toggles between warning and critical, like CPU Load on a DB host for instance because of some long queries.
So generally speaking a service state change between:
warning → critical → warning → critical → warning → critical etc. triggers the first notification after 5 minutes, all subsequent critical states trigger notifications immediately and not after 5 minutes.
would that mean, disabling Periodic notifications during service problems will restore the delay notification time for a service state transitions between non-OK states (e.g., CRITICAL → WARNING → CRITICAL) ??
we disabled the rule:
Periodic notifications during service problems
Maximum number of check attempts for service
Retry check interval for service checks
and the notification flow worked as expected with the following setup:
Notified events for services: Service goes into critical state
Delay service notification: 5 minutes
Normal check interval for service checks: 1 minute
and kept the rule in the notification system for the service groups to send alerts:
Service events → State change: any → critical
The only one incoherent event was that a critical service event triggered a notification after 3 minutes instead of 5 while the service was toggling between warning and critical without being OK in between, this is something we can live with at the moment.