CMK version:
2.0.0p20 (CEE) OS version:
CentOS Linux Release 8.3.2011 Error message:
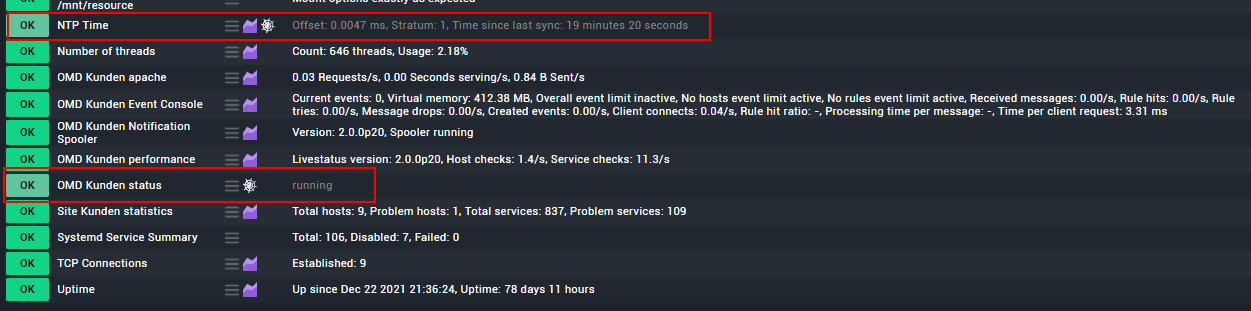
NTP Time Stale
Offset: 0.0000 ms, Stratum: 1, Time since last sync: 49 days 11 hours (warn/crit at 1 hour 9 minutes/2 hours 9 minutes)
Zusätzliche Angaben:
-Für die Zeitsynchronisation wird chrony verwendet.
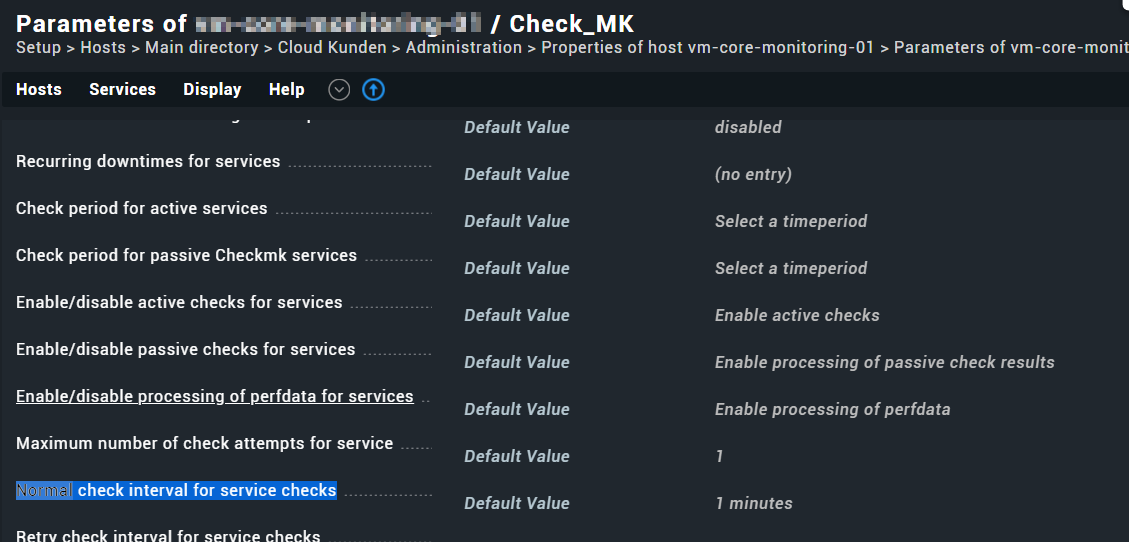
-Checkintervall ist default 1min
-Rule: State of NTP time synchronisation
Thresholds for quality of time
critical at stratum 10
warning at 200.00ms
critical at 500.00ms
Phase without synchronization
warning at 1hours 9mins
critical 2hours 9mins
Die Datei /var/lib/check_mk_agent/cache/chrony.cache wird nicht aktualisiert:
<<chrony:cached(1641866810,30)>>
Reference ID : 50484330 (PHC0)
Stratum : 1
Ref time (UTC) : Tue Jan 11 02:06:41 2022
System time : 0.000000019 seconds fast of NTP time
Last offset : -0.000271347 seconds
RMS offset : 0.000085864 seconds
Frequency : 6.711 ppm slow
Residual freq : -1.600 ppm
Skew : 0.269 ppm
Root delay : 0.000000001 seconds
Root dispersion : 0.000057570 seconds
Update interval : 8.0 seconds
Leap status : Normal
Der Server auch welchem der Dienst überwacht werden soll ist ein monitoring server, der als distributed monitoring zum main server hinzugefügt wurde. Dieser sendet seine Daten über das Internet zu uns ins Netzwerk, weil der Server innerhalb einer Azure Infrastruktur steht.
Ich bin einige Beiträge hier im Forum durchgegangen und bin auf keine Lösung gekommen.
Hi,
We are also experiencing issues with NTP monitoring for chrony since we updated
Checkmk MD and agents from 1.6.0p27 to 2.0.0.p20.
Since then, several of our hosts report errors in Checkmk for NTP services (example below)
Offset: 0.0818 ms, Stratum: 3, Time since last sync: 7 days 16 hours
When I check chrony status on the host, it reports last update as being n seconds ago (91 in example below, see LastRx value)
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* ntp01-internal.domain 2 8 377 91 -650us[ -693us] +/- 4004us
Update Intervals are normal at approx 260 seconds:
# chronyc tracking
Reference ID : A1320112 (ntp01-internal.domain)
Stratum : 3
Ref time (UTC) : Tue Mar 08 23:10:44 2022
System time : 0.000028481 seconds slow of NTP time
Last offset : -0.000037280 seconds
RMS offset : 0.000100630 seconds
Frequency : 15.387 ppm slow
Residual freq : -0.003 ppm
Skew : 0.122 ppm
Root delay : 0.004392941 seconds
Root dispersion : 0.001860444 seconds
Update interval : 261.1 seconds
Leap status : Normal
Running chronyc sourcestats shows the interval between the oldest and newest samples to be 73 minutes.
Name/IP Address NP NR Span Frequency Freq Skew Offset Std Dev
==============================================================================
ntp01-internal.domain 17 9 73m -0.001 0.091 -221ns 113us
I have verified that our check interval for the Check_MK service is set to 1 minute as suggested in
this discussion.
When I look at the check_mk cache directory on the host, the chrony cache file is not being updated.
I have tried removing the cache file but no new cache file is being created.
Any further suggestions on solving this problem would be appreciated.
Attempts to run the check from the checkmk monitoring server against the host via the cmk utility
show no errors but the chrony cache file on the affected hosts is not being updated.
When we run the check_mk_agent manually from the command line on the affected
Linux hosts, the /var/lib/check_mk_agent/cache/chrony.cache file is updated and the monitoring alert reports ntp status as being normal.
Only one idea, is the CMK agent executed as root or do you use some “normal” user for the agent execution? I had one such systems some time ago and the normal user could not write to the “/var/lib/check_mk_agent/cache” directory. This was there the reason for stale cached services.
We tried this and it worked for us with all the affected systems with stale ntp caches (chrony) now updating correctly and no further errors reported by checkmk.
Just for general comparison, as mentioned previously, not all of our systems displayed the error.
They run a mix of Oracle Linux and Red Hat Linux 7 and 8 with all systems running chrony for time synchronisation.
We currently run checkmk rel 2.0.p22 on all systems.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.