I have a few temperature sensors in servers.
Monitoring works no problem, but I recieve Notifications for every service state change.
Example
Whenever a server temperature reaches WARN or CRIT even for a second I get a notification.
I’d like it to send notifications after 10 minutes continuous in CRIT state.
It should not send a notification if the state changes from CRIT to WARN and back to CRIT, instead on reaching WARN the “10 minute timer” should stop and upon reaching another CRIT a new 10 minute timer should be starting.
After all, being over 80°C (which is standard CRIT value for temperature) for a second isn’t harmful at all and I don’t need to know that.
I would suggest using the rule “Delay service notifications”. It does exactly what you want. It delays the notification for a specified amount of time. If the service returns to OK during this time, there will be no notification.
Regards
Udo
Sadly, the proposed solution with the notification rule restrict n-th to m-th notification does not work as well.
Giving it a thought or two, I think I know why it wouldn’t work:
The Temperature Service only creates 1 notification per service change, so Notification 10 and 11 never occur.
Even if it would have a periodic service notification every minute, it would still be sending out notifications for WARN and CRIT without taking the 10 minutes CONTINOUS CRIT STATE into account.
With the rule “periodic service notification” it’s also not possible to say “only for CRIT state”.
Somebody else have some kind of idea on this?
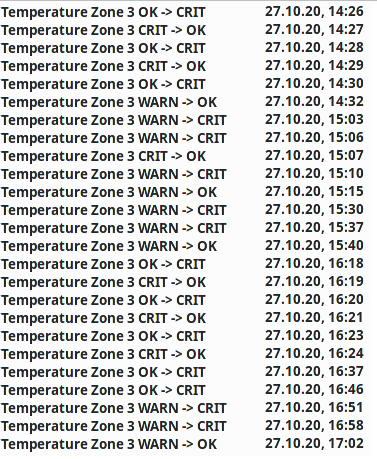
Screenshots of the notifications + time when they arrived:
We observed how this happens (management jobs, cleanup jobs, backup jobs, many simultanous user queries, etc etc)
Except for the planned jobs we cannot set a service period because user queries happen randomly
80°C is okay for CRIT
But we don’t want to recieve 30 mails a day whenever the temperature exceeds the threshold for a very limited time
That’s why we would like to recieve mails but only if the temperature exceeds the limit for too long.
I could set CRIT for 90°C, but we wouldn’t get any notifications at all (or close to any, the server reached 90°C for a few seconds once in the last months).
You could use the “Maximum number of check attempts for service” ruleset: The maximum number of failed checks until a service problem state will be considered as hard. Only hard state trigger notifications.