Version: Checkmk Raw Edition 2.2.0p7
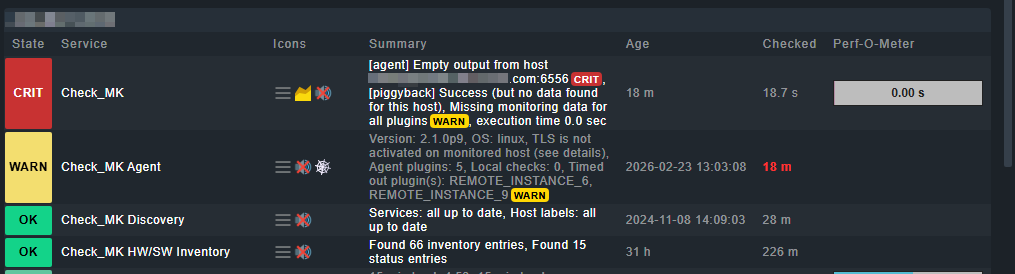
I’m monitoring Oracle instances across multiple RDSs. I’m using the plugin and the .cfg file. It works fine, but when one or more RDSs disconnect (4), the configuration file becomes corrupted, throwing a timeout error. The entire configured universe stops reporting, sending no notifications, and if I run a discovery, the monitoring alerts are deleted.
The objects are displayed on fake servers, use the endpoint name, and were configured without an IP address.
If I run the script manually, it works fine, only flagging timeout errors. The other configured RDSs do show information, but as I mentioned, the Check_MK web interface is empty.
The CheckMK agent on the server where it is configured disconnects and throws a timeout message.
This event lasts quite a while, then everything connects and everything is OK again.
During the issue, if I remove the lines in the .cfg file of the RDS that throw an error when running the manual script, everything resets. The next day when I run the manual script and see that they work, I add them back and everything works without a problem.
This is typical of the Oracle agent when being used in a remote config and one or more instances in the config are offline. I’m assuming you have the following config as an example in the /etc/check_mk/mk_oracle.cfg:
INST1
INST2
INST3
INST4
etc
INST3 goes offline - the agent will wait for the SQLNET timeout to fail - which is governed by the TCP timeout and is usually longer than the agent timeout.
You might be able to get a solution by using SQLNET.OUTBOUND_CONNECT_TIMEOUT in the sqlnet.ora to limit the connection duration attempt to Oracle. Take a look at the following:
Unfortunately the only reliable work around I have found to keep the other instances monitored is to comment out the failing instance(s) from the mk_oracle.cfg.