I have a few devices that can only be tested by ping.
One of these devices is perfectly happy to respond with 100% reliability, essentially forever, to the classic “ping -t” (on Windows) or “ping” (on Linux). PRTG checks are also normal.
When I use the ping host check on CheckMk I get back a lot of critical failures on this device.
How is CheckMk different from Linux ping and how can I make it work like Linux, since that seems to work OK?
I am on 2.1.0b7 and I also see this. It is good to know that I’m not alone.
I’m running the raw edition inside docker on a libvirt host in Openstack… Also I have hundreds of hosts with more than ten thousand services. I have only recently added back checkmk and we have previously seen interesting behaviour of checkmk 1.x installed via rpm on an LXC container.
Before seeing your post my guess would have been that it is related to containerized network with many concurrent network connections.
What is your setup?
My next steps in debugging would be to move my site to running rpm installed on the VM and then try to go for a bare metal machine.
2.1.0b6 raw on Ubuntu Focal. Ubuntu is on a Hyper-V instance on a Windows 10 Pro (fast) machine. Network connection is a dedicated IP on the Hyper-V bridge.
There is absolutely no problem pinging from that instance of Ubuntu so it’s not a problem with Hyper-V, the bridge, Windows, or anything else. The problem is peculiar to CheckMk.
I was able to search out some old topics but most are very hold and no longer relevant to modern versions of CheckMk, or had no answers.
This is a shot into the dark - which amounted to nothing.
I found it a bit hard to imagine that something like ping/ICMP in particular is an issue. However, I have seen problems with default configuration of Linux hosts with many network connections before (Ceph on RHEL based distros). I have put the following into /etc/sysctl.d/10-tune-net.conf followed by a sysctl -w -p /etc/sysctl.d/10-tune-net.conf.
# The following are taken from OSD network tuning
kernel.pid_max=4194303
vm.zone_reclaim_mode=0
vm.swappiness=10
vm.min_free_kbytes=2054760
vm.dirty_ratio=40
vm.vfs_cache_pressure=100
net.netfilter.nf_conntrack_max=10000000
net.nf_conntrack_max=10000000
net.netfilter.nf_conntrack_buckets=2500000
net.core.somaxconn=10000
net.core.netdev_max_backlog=100000
net.ipv4.tcp_max_syn_backlog=100000
net.core.optmem_max=40960
net.core.rmem_default=56623104
net.core.wmem_default=56623104
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_syncookies=0
net.ipv4.tcp_tw_reuse=1
fs.aio-max-nr=1048576
net.ipv4.tcp_fin_timeout=12
net.core.rmem_max=67108864
net.core.wmem_max=67108864
net.ipv4.tcp_rmem=4096 87380 33554432
net.ipv4.tcp_wmem=4096 65536 33554432
net.ipv4.tcp_congestion_control=htcp
net.core.default_qdisc=fq_codel
However, this did not help at all… Very interesting.
Again, normal ping from the Linux command line on my CheckMk machine works 100% fine, for thousands of pings. The CheckMk ICMP check is screwed up somehow, or at least not the right kind of ping test for this device.
I’ve found many topics in the forum archives describing this same problem, but no solutions going back over ten years.
I currently have 20 hosts with approx. 330 services monitored. Not a large site at all. And that also should have nothing to do with it.
Short remark to this problem.
check_icmp → sent’s 5 ICMP packets at the same time and waits for the return of all or for a timeout
check_ping → sent’s 5 ICMP packets one after another with 1 second time in between
The check_ping behaves like a ping on the command line, but the execution time is longer. This is one reason why you don’t want to do this in a large environment.
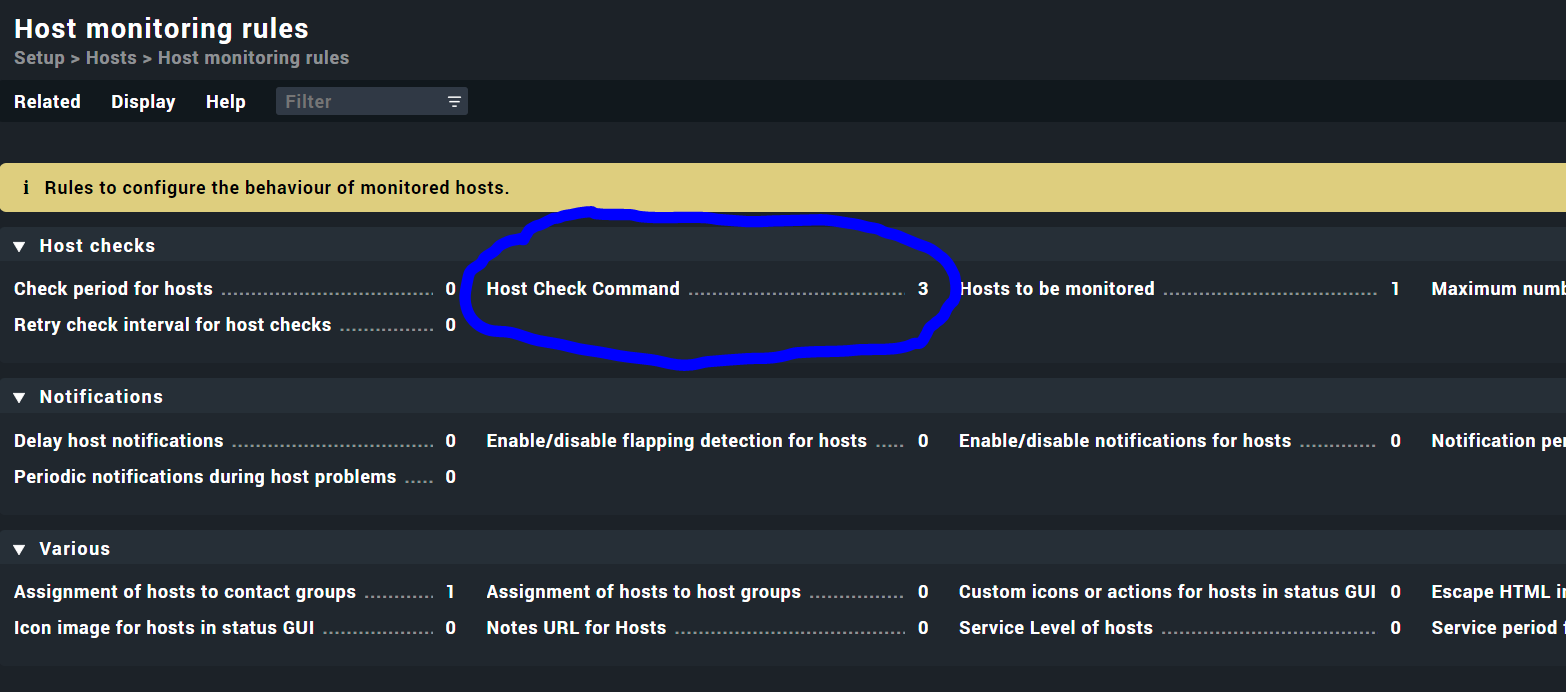
You can change the host check command inside the rule “Host Check Command”. Here you need to select the “Use a custom check plugin…”.
As command line you can use something like this $USER1$/check_ping -H $HOSTADDRESS$ -w 100,10% -c 200,20%
I had some firewall devices that are blocking some ICMP packets if all packets are coming at the same time. That is bad behavior.
For example, what if I want to change the round trip warning and critical levels for this check? Where would I find the flags for that and the syntax documented? And where and how would I know to use "$USER1$ ?
The easiest way is to go to the folder “~/lib/nagios/plugins/” and execute the wanted plugin with the “–help”. In the web you can find the documentation to most of the plugins at https://www.monitoring-plugins.org/
This is a variable the core need to know. The value is set inside the file “~/etc/nagios/resource.cfg”.
There you have some predefined values like the mentioned $USER1$.
I noticed that the default ping thresholds seem to be already more relaxed than what you are applying now, as suggested by this line in the ping service of one of our affected hosts: Service check command check-mk-ping!-w 200.00,80.00% -c 500.00,100.00% 172.16.65.180
The latency and packet loss of our affected hosts are even higher, so I went with some quite generous thresholds: $USER1$/check_ping -H $HOSTADDRESS$ -w 1000,90% -c 2000,100%
While this may seem high, in our scenario the affected hosts are only pinged on their BMC IP.
Each machine is basically redundantly/separately monitored as another host with a checkmk agent (due to being an OpenStack Nova Ironic instance). So I think in our case we are safe with these thresholds while minimizing ping warnings and flapping. You might want/need more strict thresholds in your setup.
Thank you. That is phenomenally helpful information! I searched and searched through the CheckMk documentation, and this forum, and found none of that. And that is some super important and super basic stuff, too.
Overnight the host in question seemed to do better with check_ping instead of check_icmp. However, now armed with your information, I was able to appreciate that the default check_icmp ping size is 68, which is not the normal Linux size of 56 (in both cases without the additional 8 bytes of the ICMP header). I suspect that this might have something to do with the problem. That revelation, combined with the knowledge that an explicit IPV4 flag is available, and the lack of any documentation on or control of the ping size for check_ping, I’ve switched back to check_icmp with the following custom parameters:
If this starts to show good, reliable performance then I can tighten up the warning and critical limits although that may be unnecessary. Typical response times are running in the 6ms range, 20 is quite generous, 500 is merely catastrophic, which is all I need.
I also like that the check_icmp command collects stat’s while the check_ping command does not.
We’ll know if this worked well in about four hours or so. I’m trying very hard to not have to invoke a “maximum number of check attempts” rule on top of this.
Slightly off topic, but do you know how to clear the event log? As I develop my CheckMk configuration it is terribly distracting to see a ton of old events when I am starting a new period of monitoring the performance of a new change.
I’ve tried check_ping with this host and if fails regularly.
I’ve tried check_icmp with this host with a lengths 56, 64 and 68 and it fails regularly with any of those settings. I also tried the Windows default of length 32, but that is not supported by check_icmp.
check_ping and check_icmp with length 64 are nominally equivalent in performance in terms of failures per hour.
so I can get stat’s and “band-aided” it with a “Maximum number of check attempts for service” rule that requires three failures in a row before declaring the host down. This is a terrible hack but I can’t see any way around it.
Clearly both check_ping and check_icmp work differently than Linux and Windows ping–if anyone knows the how and why of this it would be great to understand.
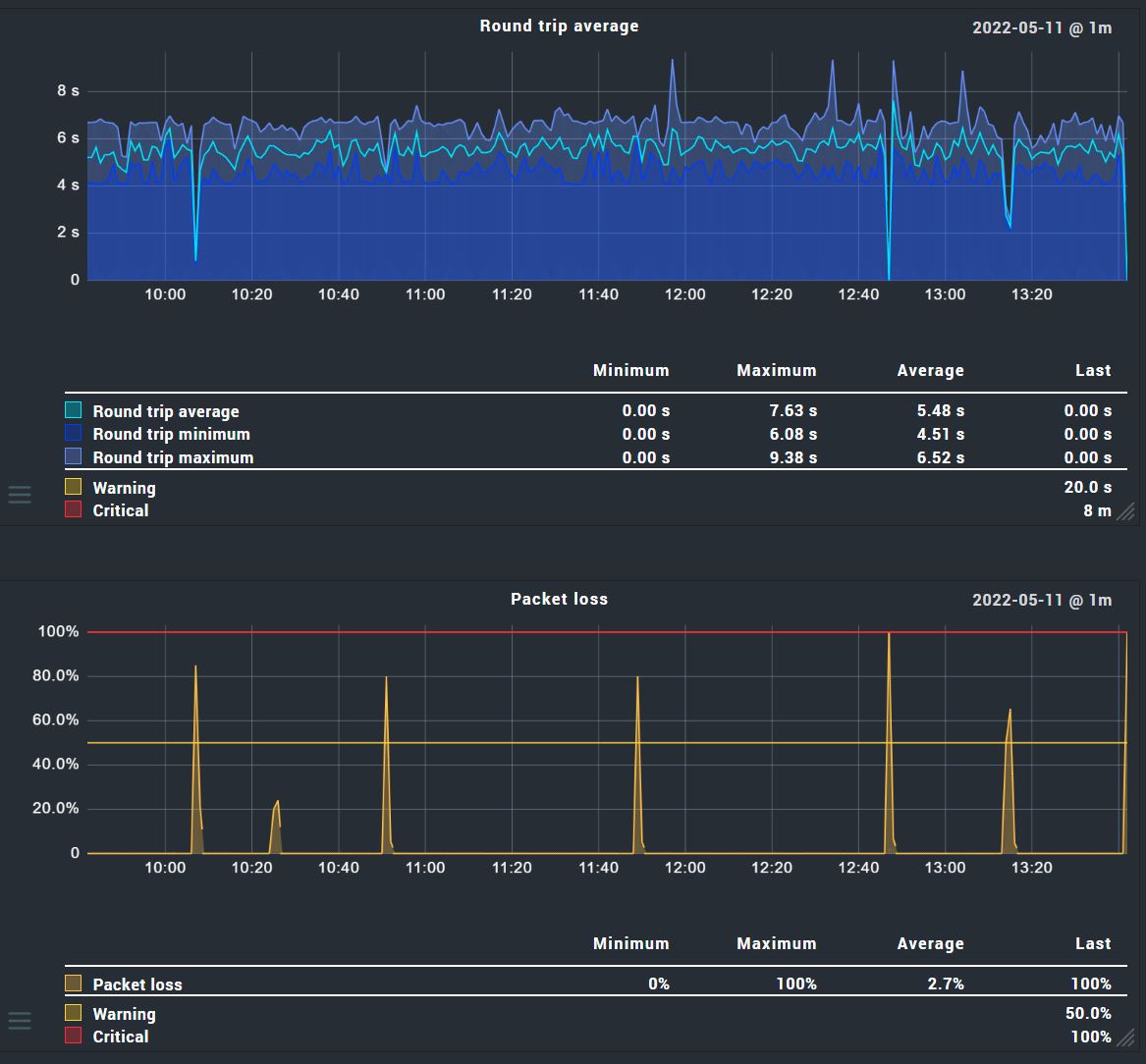
You have a rtt of 6 seconds really?
If it is only a unit bug in the graph then i would say that somewhere in between you have a firewall device filtering some traffic from time to time.
As you have only packet loss and no higher rtt then all the other time.
Packet loss can have very diverse causes.
No check_ping does exactly the same as a normal ping on the command line. As you can see here in the source code, it only calls the system ping command.
If you start check_ping with verbose output you see the system command that is called with check_ping.
No, you must have missed reading the last line in my post. That’s a bug in CheckMk.
OK, maybe you didn’t miss the last line, but then why your first statement?
There is no firewall. I can run Linux ping for hours on the command line on the CheckMk host and it never, ever skips a beat. It only fails inside of CheckMk.
Unfortunately I’m not a developer, so I’ll have to take your word for it. All I can say is that if it’s 100% good at that level of the code then it has to be failing at some other level.
I did run check_ping and check_icmp from the command line and get in the neighborhood of 6ms RTT, so there’s nothing wrong with RTT. Linux command line ping also reports 6ms.
I have there 2 rules but specific for some explicit hosts.
But for other hosts i do not have a rule , but CMK says host state up, so i assume it does a host check.
So i want to know what check it does do : check_ping, check_icmp or a smart PING (as we are a micro core user).
I can only guess that it does a smart ping? I’m a relative newbie to CheckMk, coming over from PRTG. With luck someone more knowledgeable will respond.
P.S. I had to up the “max check attempts” to 4 on my host in question. Meanwhile, PRTG continues to run in parallel until I’m ready to cut over, and it has NO trouble with this host at all.
Also correct. If @tsopgo is using the micro core (enterprise edition) then the default host check command is smart ping. For RAW installations the default is check_icmp.