[Gerne auf Deutsch oder Englisch antworten]
CMK version: 2.4.0p22 Enterprise
OS version: Debian 13
Error message:
Hi, we have setup monitoring for PVE Clusters (nodes+cluster hosts) using the docs: Proxmox überwachen
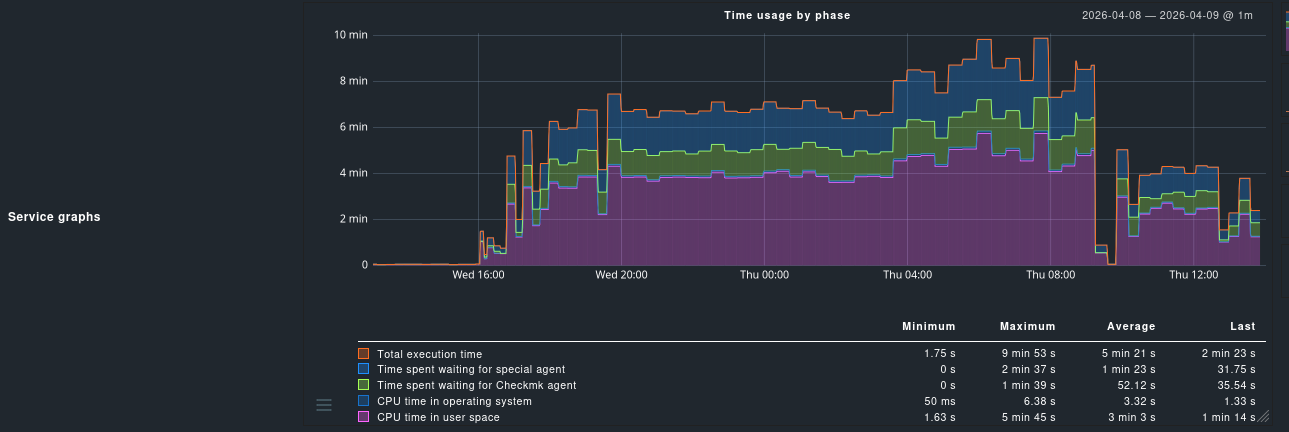
This works great so far: nodes have a a normal active checking interval of 2 minutes, while clusters normal check interval for service checks vary depending on their size (small clusters 5 min). Same goes for the service timeouts.
The biggest issue we encountered was the monitoring a pve cluster with ~30 hosts. As soon as the node checking intervals have been increased to 5 min, the cluster checks and service timeouts had to be adjusted accordingly as the execution time for Check_MK on the cluster host grew massively.
The peaks shown below stem from our experiments playing around with the node check intervals (5 min) → cluster 15min with a timeout of 10. On Thursday we briefly returned to 1min normal active check per node and later switched to 2 min.
My assumption is that it has to do with caching/validity of piggyback data: since each node piggybacks data from the others, it appears that the cluster host hits this cache?
On the other hand, it looks like the cluster host performs the check for each host again.
When running a cmk -Ivv cluster_host, the special agent appears to be called per node from the cluster host and there is a max_age=0 when checking. If I understand correctly, clean API calls are made during checks per node.
....
Read from cache: AgentFileCache(path_template=/omd/sites/plain/tmp/check_mk/cache/<node01>, max_age=MaxAge(checking=0, discovery=180.0, inventory=180.0), simulation=False, use_only_cache=False, file_cache_mode=1)
...
This brings me to my actual question: is there a correlation between the individual node interval check and how fast the checks on the cluster host actually run? If not, which factors contribute to better performance when monitoring a large pve cluster?
Thank you ![]()