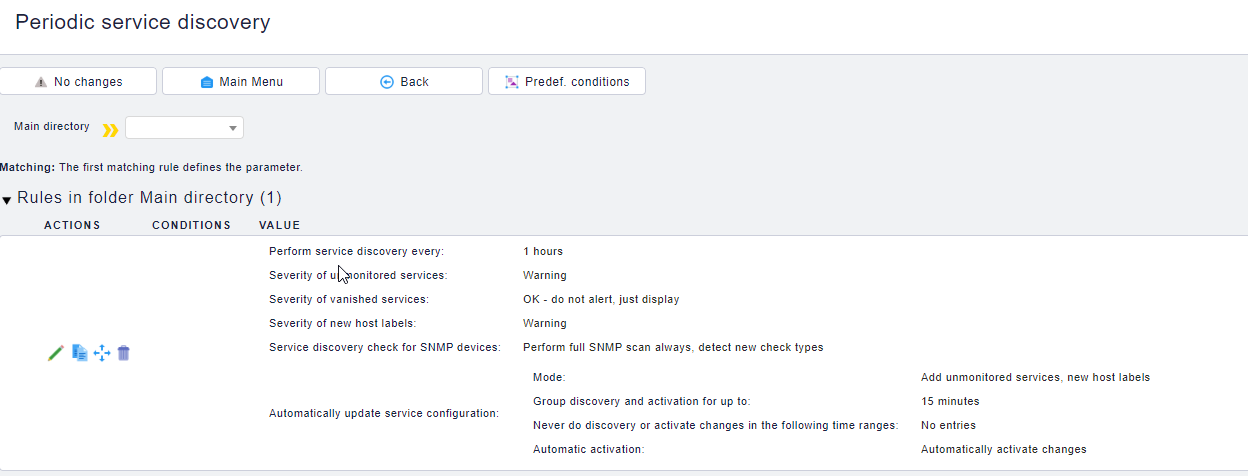
I added a rule for periodic service discovery (checmk raw 1.6.0p6) with the following settings:
|Perform service discovery every: |2 hours|
|Severity of unmonitored services: |Warning|
|Severity of vanished services: |OK - do not alert, just display|
|Severity of new host labels: |Warning|
|Service discovery check for SNMP devices: |Perform full SNMP scan always, detect new check types|
|Automatically update service configuration: ||
|Mode: |Add unmonitored services, new host labels|
|Group discovery and activation for up to: |2 hours 15 minutes|
|Never do discovery or activate changes in the following time ranges: |No entries|
|Automatic activation: |Automatically activate changes|
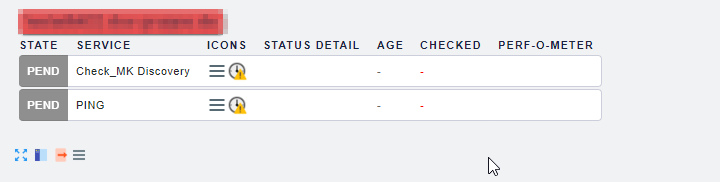
This works partially. The “Check_MK Discovery” switches to warning and shows the correct amount of new services:
But these are not added as monitored services. I expected that this would be done automatically according to the mode “Add unmonitored services, new host labels” and automatic activation. But there seems to be nothing processed at all after that.
If I do an "cmk -I " and an “cmk -r” via command line the found services are added.
Also if I do an “Edit services” everything works as expected.
Only the automatic adding is not done. What should do this and are there any logs which I could check? I did not found anything according this process.
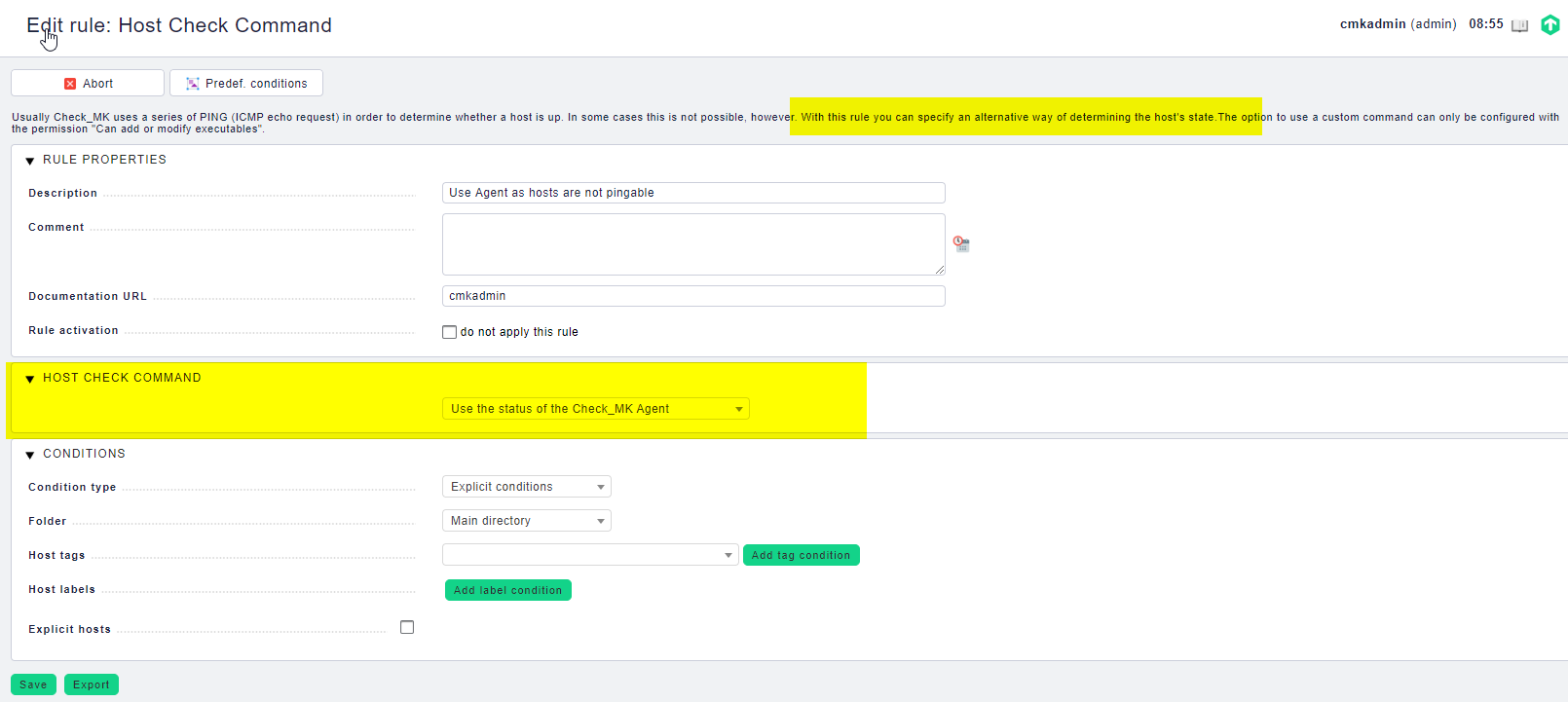
One thing to note (not sure if this is relevant): the nodes are not pingable. Therefore a rule exists which switches the Host check command to use the status of the Check_MK agent (which is enabled globally)
Not much.
The scheduled rediscovery is done with the cron job what runs every minute inside your monitoring site.
Can you test if the behavior is different if you use the default settings for the “Group discovery and activation for up to:” - this was 15 minutes if i remember it correctly.
I think the group activation should not be longer than the check interval (2 hours in your case).
Can you test if the behavior is different if you use the default settings for the “Group discovery and activation for up to:” - this was 15 minutes if i remember it correctly.
This does not make any difference. Previously we used the default of 15 minutes. As we had the problem above we changed the settings to 1:1 to the settings of a working installation (and they use 2:15).
Enterprise <-> Raw should not be the problem as i also have some Raw versions running where this is working. But I don’t know if there is/was a problem from p6 to p13 what is the actual 1.6 version
I updated to p13 but with no success regarding this issue.
I assume that the followin entry in crontab should do the job:
*/5 * * * * cmk --discover-marked-hosts
I ran it manually with -vv but the only output is:
Doing discovery for all marked hosts:
(with no hosts)
I found out some places regarding the filesystem and checked these:
var/log/autodiscovery contains empty marker files for the hosts
var/log/autochecks does not contain anything about them
So I assume that either the process which reacts on the marker files is not called or is not working.
As long as I do not manually activate the changes there is still a service “Ping” which is in error state (as ICMP is not possible). On manual editing the services ping is replaced by “Check_MK Service”
Perhaps the rule which switches to Agent output is not applied before a service was added and the process which is doing the autocheck -> autodiscovery transformation is skipped as long the host is not “reachable” (which is currently pingable as rule does not apply)?
I cannot help directly in your problem as i have no systems without ping at the moment at hand.
But today i had a system - Raw p13, relatively new, no rules defined. I setup the discovery with automatic activation and it found some new services and labels. After 30min all the changes where active inside the monitoring without any problem.
If the host is not pingable you need to define something else as a host check what is really existing, if you want to use this automatic feature.Like a active check for some TCP port or so.
In your case there was no valid host check and as a result no automatic discovery. I don’t think that this is a real bug, more like an edge case.
I disagree that there is no valid host check. The CheckMK agent is running, callable, retrieves a ton of services via discovery these are just not activated as checkmk still uses ping (disregarding its own rule)
I aggree that this may be an edge case but I would assume that using standard features should work - it seems more than a overseen dependency between these two functions.
and stays in this situation. If I manually use “Edit Services” and activate all services the host check is replaced. cmk -vv --discover-marked-hosts should do the same but will do nothing.
If I patch discovery.py and remove the “skip not up host” everything works as expected!
Even it is an edge case I would call this definitly a bug. The only workaround is to either patch the discovery.py manually or to use tcp port 6556 as host check (but I do not know if this would work or would have the same issues) - but I assume the agent would be triggered twice (via host check and via check mk check). This should be the reason there is an explicit “use check mk agent” as host check
Just removing the skip in discovery.py fixes this issue and at least a verbose output about skipping as “host not up” should be added to get this situation at all.
@micha FWIW, I highly appreciate your effort! I have the exact same problem with our unpingable hosts. I have also set the state of the Checkmk-Agent as a replacement for ping but as soon as that service vanishes (or goes non-OK), the auto-discovery ceases to work. I’m using 1.6.0p8.cee.