Hi All,
My Checkmk server (a VM) seems right-sized going by the Virtual Appliance or rack1 hardware config at The Checkmk Appliance.
But a few times a week I get a high load warning on the server that appears to be correlated with with lots of “Check_MK Discovery” “Service Check Timed Out” across lots of monitored hosts (sometimes 70+).
My configuration:
Server config: 32GB RAM + 8 CPUs (4x cores per socket, 2 threads per core, Intel (R) Xeon (R) Platinum 8272CL CPU @ 2.60GHz)
Using top utility:
top - 13:26:13 up 40 days, 23:06, 1 user, load average: 53.12, 49.32, 49.99
Tasks: 316 total, 20 running, 293 sleeping, 0 stopped, 3 zombie
%Cpu(s): 65.4 us, 34.4 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 32945940 total, 4503848 free, 4774508 used, 23667584 buff/cache
KiB Swap: 2097148 total, 1055012 free, 1042136 used. 27345340avail Mem
I have also created 4 “Service Discovery rules” and associated each rule with a subset of hosts so I can stagger when they run (24 hours, 12 hours, 7 hours, 6 hours) but it doesn’t appear to help.
The RAW edition will use a lot more CPU time than the Enterprise version. The Periodic service discovery in my environment does not behave the same way.
I have it set for every 6 hours, unmonitored services set to the warning, do not alert and just display, warning on new host labels, add unmonitored and remove vanished services/host labels, group discovery for 15m, and auto-activation.
I only have one rule for all 450 hosts.
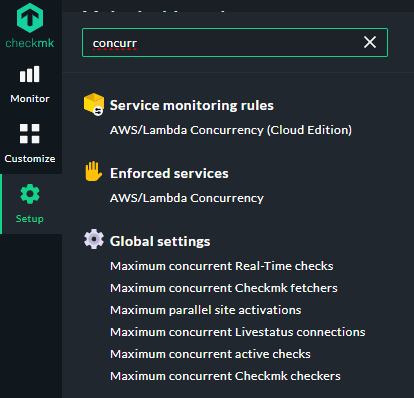
What are your max concurrent checks under the monitoring core?
Mine are from the top 50,3,20,170,8,10
I have ENT and 8 cores deployed. Running an older version of 2.1.0p27
Thanks!
Where do I find the “max concurrent checks”? Sure I have seen it before but can’t find it right now.
I have set up my default periodic discovery rule similar to yours as well and disabled the 5 others I created for the various environments.
All these settings will only work in enterprise editon of CheckMK.
The tag in the first post has “raw edition” selected.
@itababa - what you see with the spikes of high cpu load is the crappy Nagios core scheduler.
There is no good known workaround for this problem.
I would do a forced reschedule of these discovery checks over a longer period (1 or 2 hours).
Your numbers of hosts and services are not so high. Your setup should handle this without problem. What is more important is the type of hosts you monitor.
Server vs. switches/routers.
If there are many big switches or routers in your setup, it is possible that discovery checks have a problem to finish in 1 minute. This without manual modification of the core config the hardcoded timeout.
Thanks a lot. It is monitoring only Linux and a few Windows servers. No switches or other network devices.
Will just have to live with it for now and keep tweaking it :-). Some weeks the issue doesn’t crop up at all. I think there are some (NAGIOS) settings that can be changed from the backend (config files) relating to the timeout you mentioned (I will investigate that).
It may be possible to switch to the enterprise edition in future. Migrating the server soon from RHEL v7.7 to v8.9 as well so hopefully that might help as well.
Thanks again!