ich baue bei uns gerade eine neue Checkmk-Instanz auf. Bislang läuft das Ganze auch sehr gut. Nun bin gerade dabei, die ganzen Netzwerkkomponenten an unseren Standorten aufzunehmen. Wir haben dabei sehr oft die Konstellation, dass mehrere Switche als Ring gebaut sind.
Das heißt also, dass bei einem Auusfall eines Switches immer alle anderen noch erreichbar sind. Ich habe die Topologie also genau so in Checkmk abgebildet, indem ich jedem Switch als Parent seine beiden Verbindungspartner gegeben habe.
Beim Versuch, die Instanz zu reloaden, bekam ich dann einen Fehler. Ich konnte herausfinden, dass der Nagios Core ein Problem mit der Topologie hat. Leider konnte ich die Änderungen auch nciht rückgängig machen – gleicher Fehler. Ich konnte also nur ein Backup einspielen.
Nun ist so eine Ringtopologie ja nichts Besonderes. Habe ich einen Denkfehler? Wie bilde ich dieses Konstrukt am besten ab?
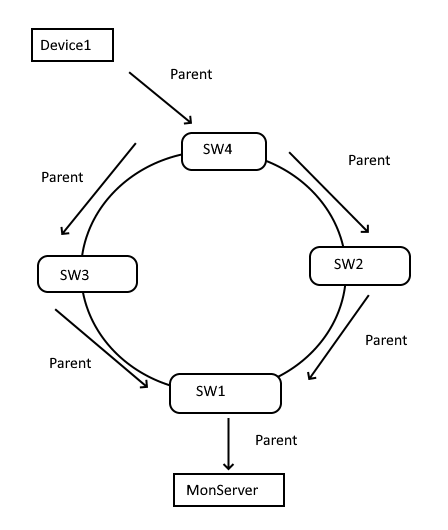
Als Ergänzung noch zu @r.sander’s Antwort. Es kann den Fall geben, dass der Switch mit dem Monitoring dran wiederum an einem Ring hängt. Hier muss dann entschieden werden welche Richtung man betrachten will. Es ist nicht möglich in beide Richtungen um den Ring rum eine Beziehung zu definieren. Hab mal ein kleines Beispiel gemacht wie es in einem Ring ganz ok funktioniert von der Beziehung her. Sollte der Ring aus mehr als 4 Devices bestehen kann es dann zu der fälschlichen Meldung der nicht Erreichbarkeit kommen.
das heißt also, dass ich die Beziehung nur in eine Richtung aufbauen darf. Ich werde das mal versuchen.
Wir haben meist mehr als vier Switche plus Core in dem Ring. Meistens werden es wohl sechs bis acht Stück plus Core sein. Das heißt, es wir vermutlich zu Fehlalarmen kommen.
Ich sag mal Jein.
Ein Core Switch ist logisch in so einer Parent Child Topologie nix anderes wie jeder andere Switch.
Es kann nur dazu führen, dass Geräte welche noch erreichbar sind als Unreachable deklariert werden. Dies ist aber immer noch “besser” wie wenn diese eine Down Meldung erzeugen welche dann ein Fehlalarm wäre.
Kannst ja mal so eine Struktur dir aufmalen immer aus Sicht des Monitoringservers denken.