How to change parameters and which one ? which rule ?
I’ve tried to change “service_check_timeout” value to 120 (instead of 60) in tuning.cfg but it’s the same thing.
I also changed snmp check interval with 5 minutes.
Thanks for your help
It is not a problem with overall timeout. For myself it looks more like a SNMP timing problem.
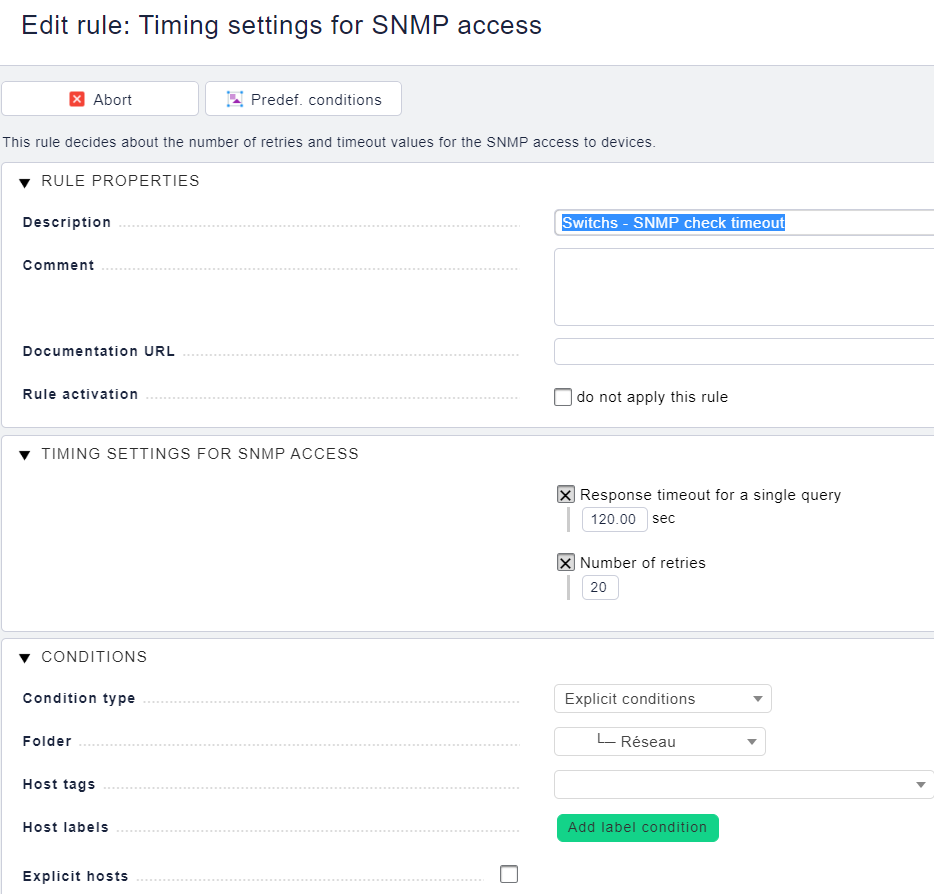
Inside WATO you can find a rule Timing settings for SNMP access. You should play around a little bit with the parameters. I think the timeout for a single query can help. Set it to something like 5 seconds and test.
Bad cheap hardware if a stack with 3 switches needs 100 seconds to get the whole interface table.
Small switches should not have this problem.
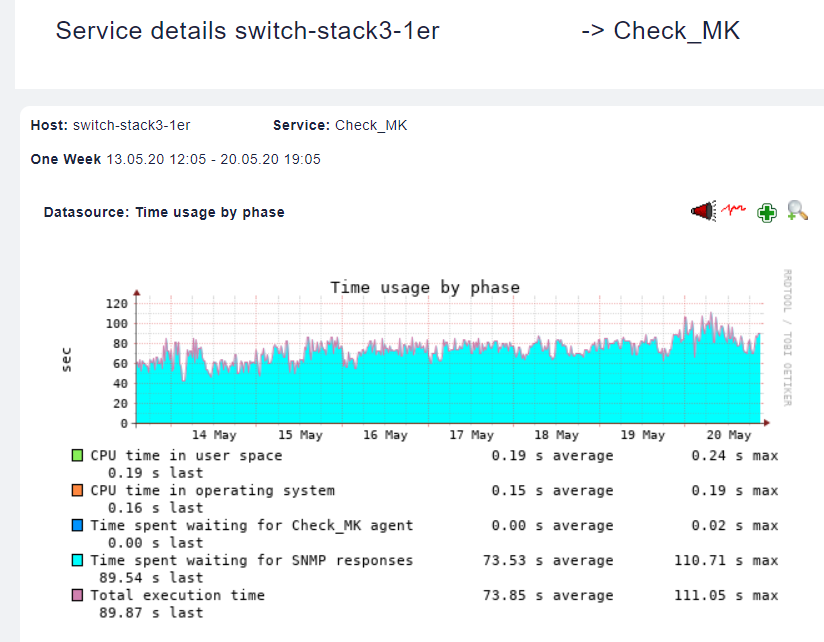
The only diagram important is the “Datasource: Time usage by phase”. There you see your system is only waiting for SNMP response.
Is this device configured to use bulkwalk?
If all this is done you don’t have many possibilities to solve this problem.
I think you only have a chance to increase check_interval and snmp_timeouts to reduce your false alarms. Because if you have a 60s check_interval and you have to wait 70s for response it the next check is scheduled.
Do all your switches have this problems or only larger ones?
Hmm, sometimes you don’t have the choice… I have these SNMP problems with management boards of not-so-cheap servers too. For a long time, I tried to tweak time values, bulk mode, different SNMP protocol versions – nothing really helped. Finally, I have set the check count so the first failure will not cause notifications – it will switch to OK with 99% certainty on next invocation.
My SNMP check interval is 5 minutes and timeout is 120s.
It’s very strange because I have problems on all switches, (smallers like HP-1810-8G and larger switches like HPE Office Connect 1950 12 XGT 4SFP+ or stacks HPE Office Connect 1950 48 ports)
If it also happens on small devices then it looks more like a general problem.
You can only inspect the response of your devices on the command line with a call like “cmk --debug -vv hostname”.
If you see that all devices are slow at the interface table then you have a general problem with all the devices. If you have other brands available to compare you will see very different behavior.
Maybe it is also a good idea to test some of the device with a pure snmpwalk, to see if this gives you some new/more details on your problem or what makes it so slow.
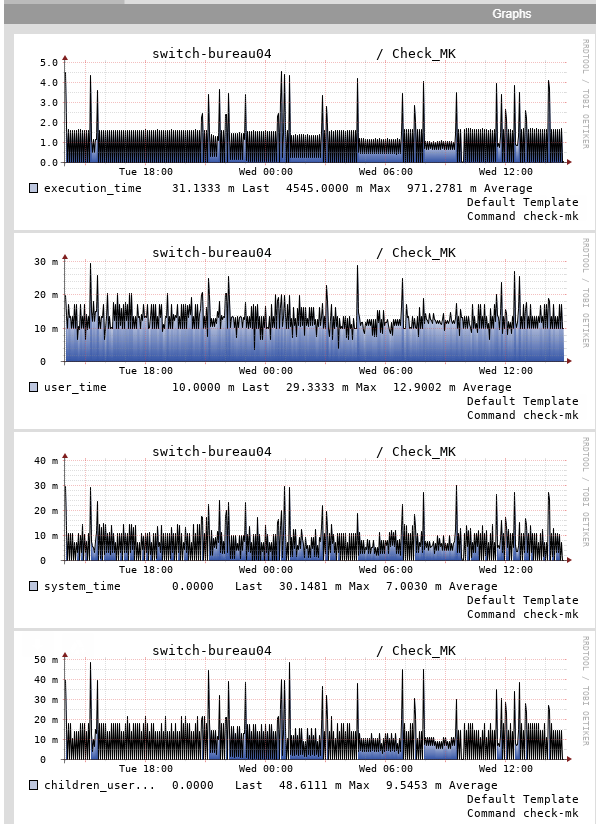

 if a stack with 3 switches needs 100 seconds to get the whole interface table.
if a stack with 3 switches needs 100 seconds to get the whole interface table.