Edition 2.2.0p16
Linux/Debian11
Hallo zusammen,
eine sehr simple Aufgabe, welche allerdings nicht funktioniert und ich nicht weiß weswegen.
Aufgabe: Führe für einen Host x eine periodische Serviceerkennung im Zeitintervall x durch.
Es wurde eine entsprechende Regel zur Serviceerkennung (periodical service discovery) erstellt, nur scheint diese nicht zu greifen. Bei einer manuell ausgelösten Serviceerkennung funktioniert alles.
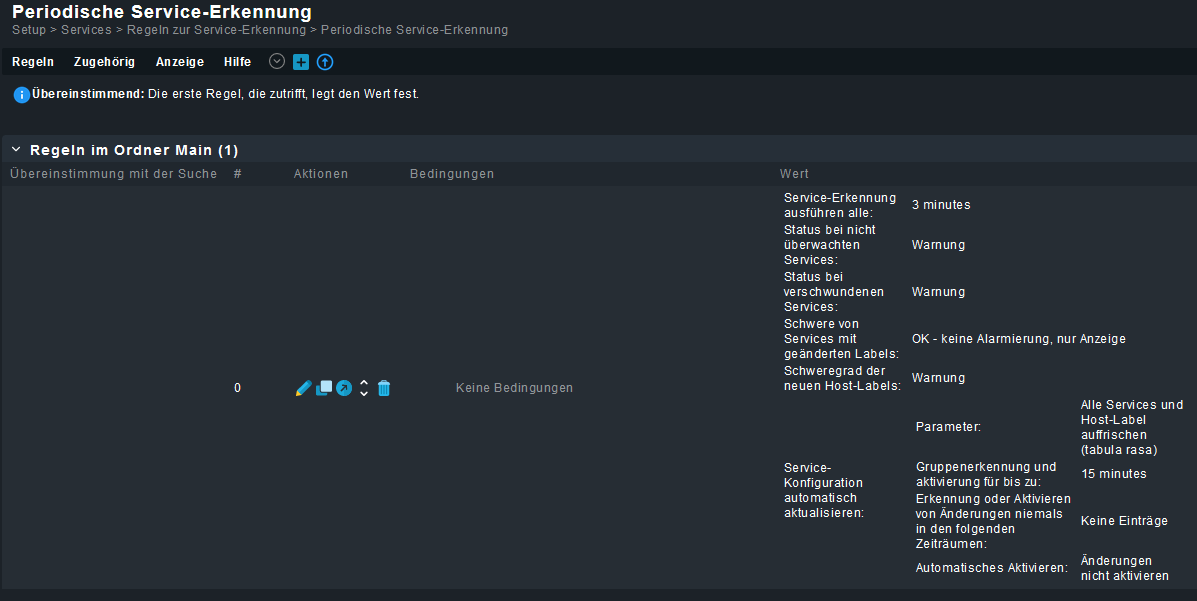
Hier die Regel, welche erstellt wurde:

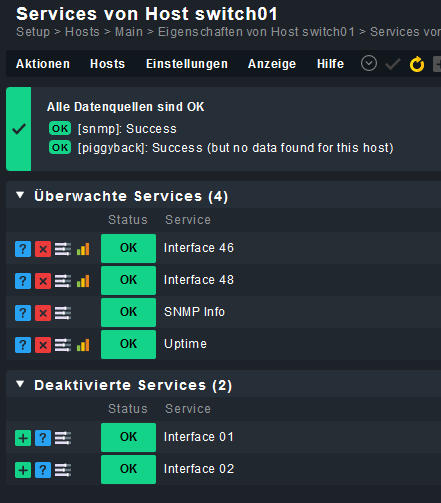
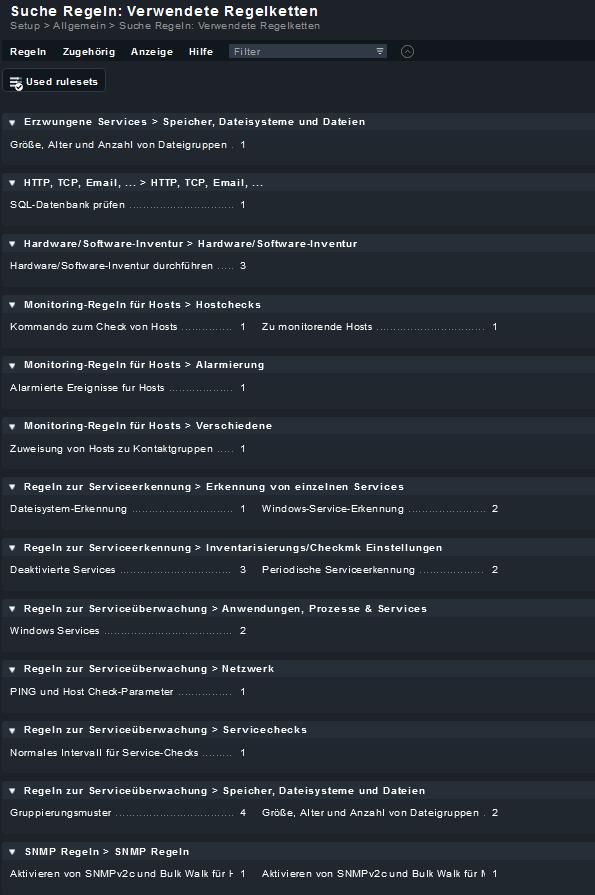
Es geht dabei um die erste Regel (Beschreibung): periodische serviceerkennung mit servicetracking
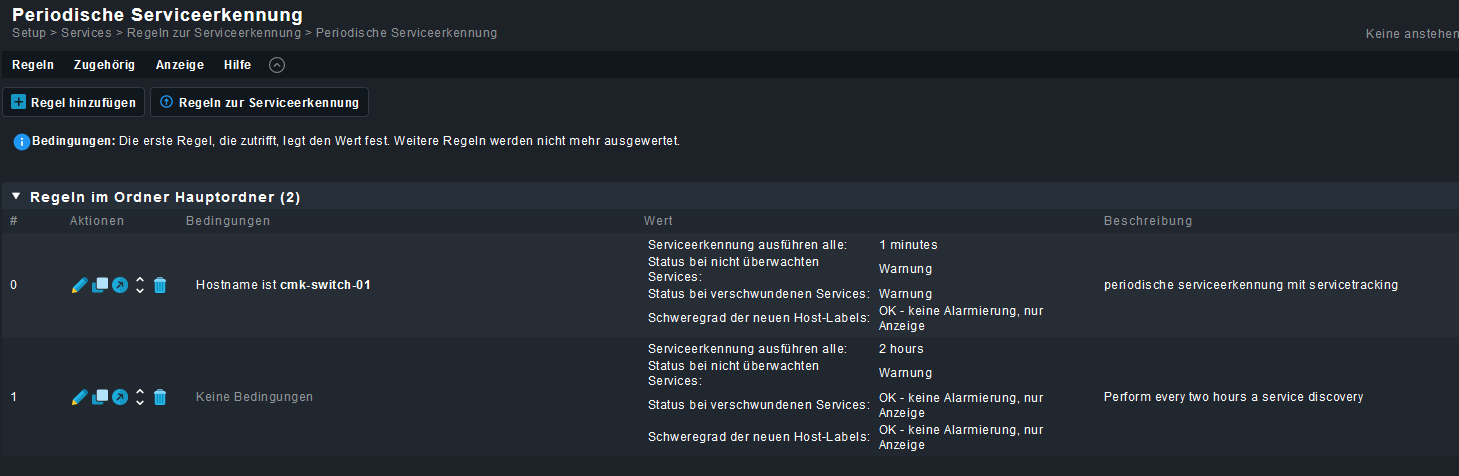
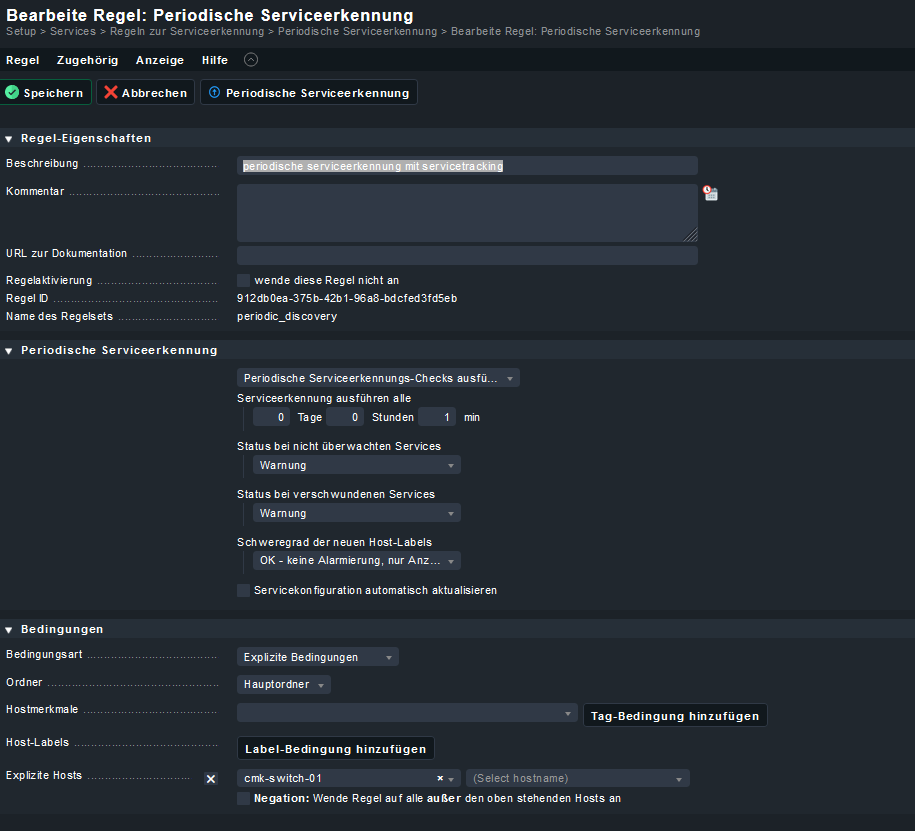
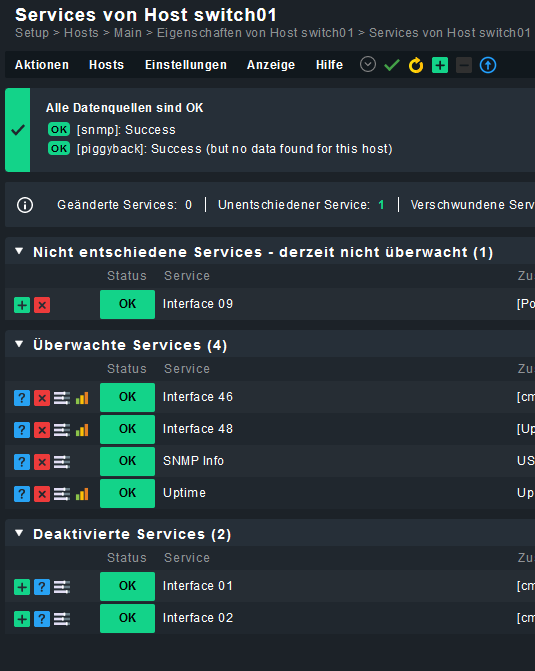
Die Regel ist damit gültig für Host cmk-switch-01 und soll jede Minute ausgeführt werden. Dabei soll angezeigt werden, wenn sich bei den Service etwas ändert, sowohl welche neu hinzukommen (nicht überwacht) oder wegfallen (verschwinden). Bei einer manuellen Auslösung funktioniert dies auch.
Das Problem ist, dass diese Regel eben nicht jede Minute angewendet wird. Warum nicht?
Hier noch die Liste aller definierten Regeln im System
Warum jede Minute? Es ist ein Test. Eine Minute ist das kleinste Zeitintervall.
Warum diese Überwachung? Es soll aufgezeigt werden, ob jemand sich an einem Switch zu schaffen gemacht hat, z.B. einen freien Port aktiviert hat. Man könnte auch alle Ports überwachen, doch ich möchte dies hierüber lösen. So wenig wie möglich und nur das notwendige Überwachen. Ich möchte auch keine unnötigen Regeln bezgl. nicht überwachte Services haben. Das ganze soll so schlank wie möglich bleiben.
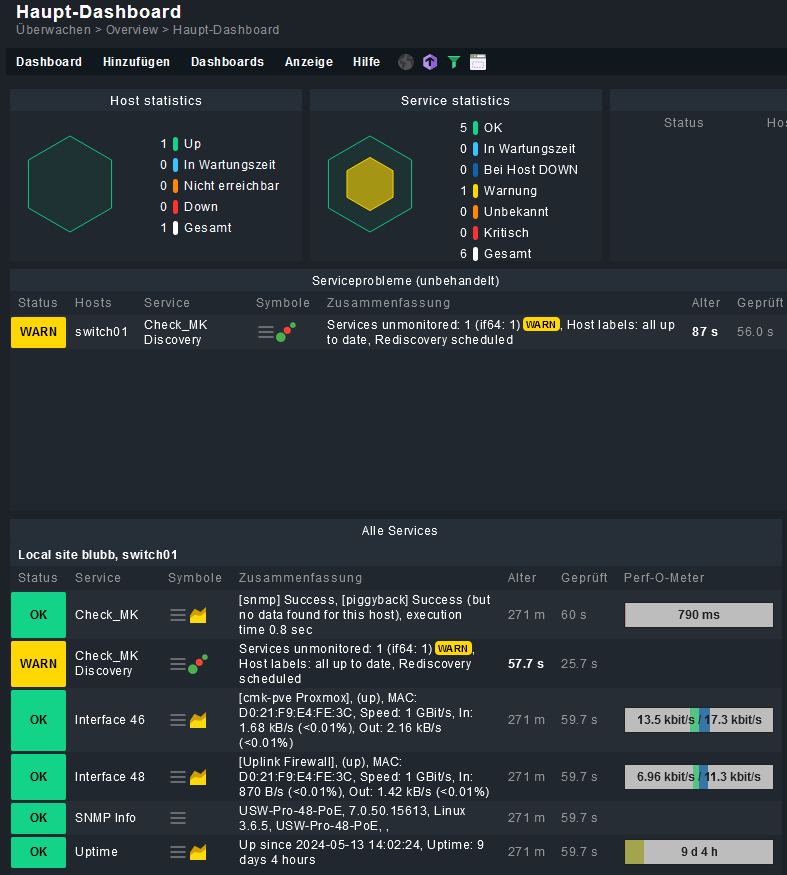
Am Ende die Taskliste von CheckMK
Der letzte Eintrag ist doch der dazu gehörende Hintergrundjob, oder?
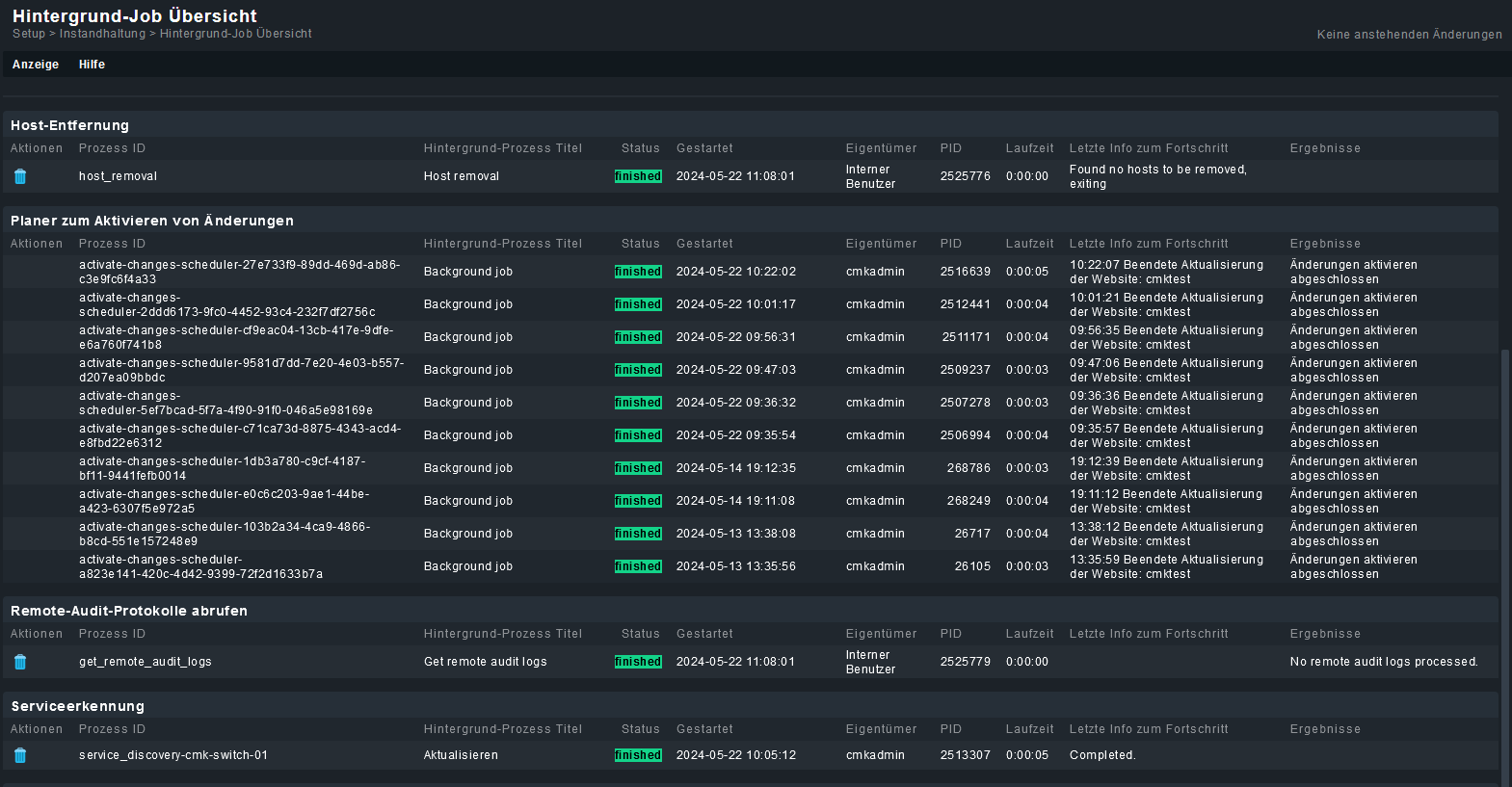
Dieser lief um 10:05:12. Mittlerweile steht die Uhr bei 11:10:xx, also deutlich über der Zeit.
Danke für Ideen und am besten einer funktionalen Lösung.