Hallo.
Ich lasse diverse Cisco SG300 und SG350X Switches von checkMK → SNMP überwachen. Seit einiger Zeit meldet ein kleiner 10-Port-SG300 ständig sowas wie:
[snmp] SNMP Error on 192.168.1.66: Timeout: No Response from 192.168.1.66
(Exit-Code: 1)**CRIT**, Got no information from host**CRIT**,
execution time 20.5 sec
Eine Minute später ist erstmal wieder alles ok und es erscheint:
[snmp] Success, execution time 16.1 sec
Unter’m Strich dauert der Check aber offenbar viel zu lange und mir ist nicht klar warum. Auf anderen Switches liegt der Wert bei weit unter 10 Sekunden.
Die Frage ist, was hier die Ursache sein kann?
Probleme mit dem Kabel? Dagegen spricht evtl, dass an diesem Switch ein Client hängt, der sich ganz normal verhält (Gigabit Speed ist da)!?
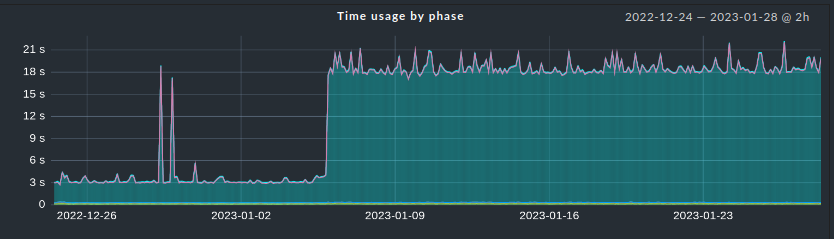
Gerade habe ich nochmal einen Service Graph aufgerufen, der eindeutig zeigt, dass das nicht immer so war:
Einen Neustart des Switches habe ich selbstverständlich schon -ohne Änderung- ausprobiert.
Wer hat eine gute Idee, woran das liegen kann bzw wie man den Wert entweder
wieder runtergeregelt bekommt oder
den Toleranzwert für diesen Check hochdrehen kann?
Hallo.
Das habe ich mir angesehen – und siehe da … wenn ich diesen Befehl verwende:
time cmk -Iv SW-Buero-R124
Discovering services and host labels on: SW-Buero-R124
SW-Buero-R124:
+ FETCHING DATA
[SNMPFetcher] Execute data source
[PiggybackFetcher] Execute data source
No piggyback files for 'SW-Buero-R124'. Skip processing.
No piggyback files for '192.168.1.66'. Skip processing.
+ ANALYSE DISCOVERED HOST LABELS
SUCCESS - Found no new host labels
+ ANALYSE DISCOVERED SERVICES
+ EXECUTING DISCOVERY PLUGINS (5)
SUCCESS - Found no new services
real 0m33.055s
user 0m2.951s
sys 0m0.858s
erhalte ich sagenhafte 33 Sek. für den Durchlauf.
Wenn ich es so mache: cmk -Ivv SW-Buero-R124 dauerte das beim ersten Mal ebenfalls lange, doch dann wurde gemeldet: SNMP walk cache cleared und danach lief der Befehl deutlich schneller (nur noch 2 Sekunden).
Die große Frage ist: Wo liegt dieser Cache und wieso läuft der voll?
Ich denke, hier wird kein Cache gelöscht. Checkmk cached die Daten, die vom System abgeholt werden für das Check-Intervall, das heißt, bis dass die Datenquelle das nächste Mal befragt wird, wird der Cache verwendet. Daher auch deine Beobachtungen mit dem Timing.
Das zugrunde liegende Problem ist und bleibt aber, dass das Gerät per SNMP nicht wirklich performant antwortet. Wobei die Fehlermeldung eher darauf hindeutet, dass das SNMP Gerät keine Daten liefert, statt zu lange zu brauchen.
Ok – aber wie erklärst Du Dir dann den Graphen da oben, der ja zeigt, dass der Switch es durchaus auch in 3 Sekunden konnte nun aber für die gleiche Aktion im Schnitt 20 Sekunden benötigt
Ich denke, am 05.01.2023 hat ein Update auf dem Switch stattgefunden. Es ist durchaus nicht unüblich, dass Cisco immer mal wieder SNMP unsauber implementiert und durch Updates komisches beim Monitoring passiert.
Gerade bei größeren Switchen können SNMP Abfragen gern auch mal mehrere Minuten dauern. Letzte Kuriosität bei uns war, dass mit einem Update alle Temperatursensoren (glaube 20 an der Zahl) live abgefragt wurden und nicht gecached wurden und er pro Sensor ca. 20 Sekunden auf eine Rückmeldung gewartet hat. Damit hat die SNMP Rückantwort ewig gedauert.
Wie der gute @tosch schon sinngemäß sagt: “SNMP is a bitch”. Aber damit du das nicht missverstehst: Er braucht nicht 20 Sekunden statt 2, nach 20 Sekunden kommt nichts vom Switch und Checkmk muss damit leben, dass es keine Daten bekommt. Und beim nächsten Mal ist der Switch gesprächiger.
Wenn es keine hochkritischen Daten sind, die du abfragst (sowas wie core Switch), reduziere die Abfragehäufigkeit. SNMP kann die Switche durchaus belasten und jede Minute kann die CPU in kleineren zum Glühen bringen. Damit umgeht man gelegentlich deine beobachten Probleme.
Wie sieht die Core statistic aus? Wie steht es um die Check helper und Fetcher herlper usage aus? Für SNMP gibt es mehrere einstellungen die bei uns geholfen haben. Leider wirst du um experimentieren nicht drum rum kommen.
Timing settings for SNMP access (gute Erfolge hatte ich mir 30 Sek. und 2 retries)
Bulk walk: Number of OIDs per bulk (default ist 10. mal mit 5 oder 20 versuchen und sehen was passiert. Mit beidem hatte ich schon Erfolg)
Hosts using a specific SNMP Backend (Enterprise Edition only): Mal auf Classic wechseln.
This topic was automatically closed 365 days after the last reply. New replies are no longer allowed. Contact an admin if you think this should be re-opened.