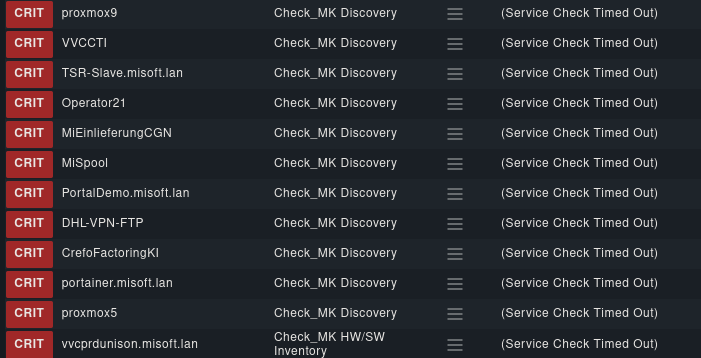
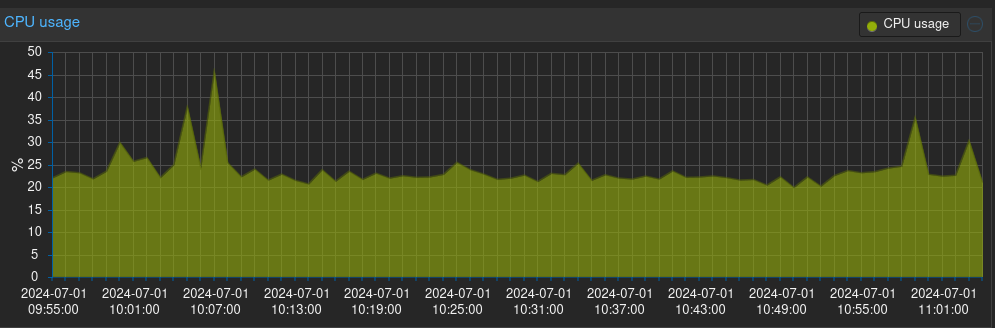
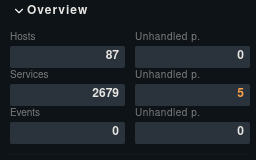
If I run “Reschedule Check”, they become OK again.
I do not get why I have to do this manually, why they become stale like this.
Rebooting the host does not fix this.
Is there any way I can mass reschedule all of them?
can you please share the server specs of the Checkmk server? (CPU, RAM)
And can you share how many hosts and services you are trying to monitor with that affected Checkmk site?
Is it only the discovery service with the timeout problem?
If yes - i would go to the command line and do a cmk --debug -vvI hostname to check what happens at discovery time.
Hi. Just to say, we experienced this problem recently as well. But cmk --debug -vvI would generally work fine for us, and if we rescheduled that check it would go green again.
We fixed it by doing a “Reschedule Active Checks” on all the Check_MK Discovery services, spread over 60 minutes.
My theory is that maybe the checks all got bunched up together somehow, and then were all trying to run simultaneously. Is that possible?
I too am seeing this with CRE version 2.3.0p36. We’ve recently upgraded from 2.0.0 but we’ve also recently added some 400 Windows hosts onone site and that site is having the problem.
It seems that all discoveries run at the same time, per schedule. It causes load on the site’s server, but the network is probably the more constrained choke point. So, adding more CPU or memory will probably not work around the problem.
What I really need is to spread the discovery checks out over time. I don’t know how to do that.