in einem anderen Beitrag (Stale Hosts und Services nach Update auf 1.6) habe ich davon berichtet, dass nach einem Update ein großer Teil der Services regelmäßig auf Stale ging und die Site nicht mehr funktionierte.
Mittlerweile habe ich de Backups mit Version 1.5.0p24 zurückgespielt. Leider tritt das Problem mit den stale Services zwischendurch immer noch auf.
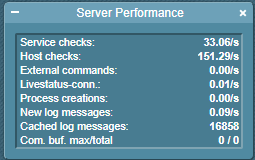
Die Server Performance sieht so aus (bei 913 Hosts und 4169 Services):
Nach einem Neustart der Site ist alles in Ordnung, nach einiger Zeit sinkt die Anzahl der Service-Checks, während die Anzahl der Host-Checks konstant in einem hohen Bereich bleibt und teilweise sogar noch auf bis zu 300/s steigt.
Ich kann das cmc.log unter mysite/var/log/ leider nicht finden, um dort nach weiteren Informationen zu schauen.
Hat jemand eine Idee, woher diese hohe Anzahl an Host-Checks stammen kann?
Schau mal bitte als erstes in deiner Site auf den Check - OMD <sitename> performance
Hierbei sind die Werte für “Check helper usage” und “Check_MK helper usage” relevant.
Wenn dort keine Werte von 100% stehen, sollten im Core noch genug Reserven da sein um alle Checks auszuführen.
Falls hier Werte von 90-100% raus kommen dann einfach in der Konfiguration mal in den Regeln “Maximum concurrent active checks” und “Maximum concurrent Check_MK checks” schauen und die Helfer Prozesse je nach Bedarf dort erhöhen.
Dies schaut mir sehr nach “Smart Ping” aus als Hostcheck. 900 Hosts alle 6 Sekunden ein Ping Paket das macht ca. 150 Pings pro Sekunde.
Es tritt immer auf, wenn ich Änderungen von der Master-Site auf diese Slave-Site pushe. Nach einem Neustart ist bis zum nächsten Pushen von Änderungen wieder alles in Ordnung.
Macht es deiner Meinung nach trotzdem Sinn, die Parameter in den maximalen gleichzeitigen Checks zu erhöhen? Das Problem scheint ja durch das Distributed WATO zu kommen.
Aktuell habe ich folgende Parameter gesetzt:
Kurze Rechnung
900 Hosts mit 1 min Check Intervall = 15 Checks pro Sekunde (Check_MK Services)
Das sollte eigentlich mit 20 “Check_MK helpern” machbar sein. Es kommt hier noch auf die Ausführungszeit deiner Check_MK Services an.
Sind da einige dabei welche recht lange brauchen (Switche oder andere SNMP Devices) dann können die 20 Helper welche konfiguriert sind natürlich zu wenig sein.
Das gleich trifft halt auf die 5 aktiven Helper zu. Dort lässt sich nur die Ausführungszeit nicht so schön sehen wie bei den Check_MK Services.
Setze die einfach mal auf 10 und 30. Teste danach ob es immer noch zu dem seltsamen Verhalten kommt.
Direkt nach der Aktivierung ist es normal, dass man einige Stale Services und Hosts hat. Während der Aktivierung der Änderungen ist das Monitoring inaktiv und sobald der Kern gestartet ist, müssen die ausgefallenen Checks nachgeholt werden. Das Phänomen sollte sich aber nach wenigen Minuten erholen.
Hallo @tosch,
ich habe es grade nochmal versucht und das ganze länger beobachtet. Auch nach mehr als 10 Minuten bleibt die Anzahl der stale Services so hoch (3200 von 4200 Services stale). Bei den Hosts habe ich das Problem überhaupt nicht, die sind wirklich nur maximal kurz nach dem Start stale.
Was mich stört sind die 100% “Check_MK helper usage” - wie viele sind da zur Zeit konfiguriert?
Wie lange ist bei dir im Schnitt so die Laufzeit des Check_MK Services der einzelnen Hosts?
Ansonsten kenn ich es auch nur so wie @tosch schon geschrieben hat kurz (1-3 min) nach dem Restart des Cores sind Services stale. Beim klassischen Nagios Core ist das viel extremer dort kann das schon mal bis zu 10-15min dauern bis sich wieder alles eingeschwungen hat. Beim MicroCore kenne ich das Verhalten nicht.
Der ARP Cache des Systems ist voll (kernel: [] neighbour: arp_cache: neighbor table overflow!). Das halte ich allerdings eher weniger für den Verursacher des Problems, da ich diese Meldung auch nach einem Neustart des Cores habe, wenn alles läuft.
Ich bekomme regelmäßig die Meldung “[icmpsender 23330] SOCK3: Could not send 64 bytes of ICMP data to xxx.xxx.xxx.xxx: Invalid argument”. Kann mir jemand sagen, woher das kommt? Der Host in der Meldung ist seit 29 Stunden im Status up, die Meldung ist von gerade eben.
wir haben in unserer Umgebung ebenfalls Check_MK Server mit >800 Hosts und >30k Servicen und bei uns reicht die Einstellung mit 10/30 für ne grobe Auslastung von 80% der Helper. Bei uns kommt es daher noch nicht zu Verzögerungen oder Stale-Services.
Eine Sache zu prüfen wäre noch die hier:
Das können z.B. auch TCP-Checks auf Ports oder ähnliches sein. Die verantwortlichen Service lassen meist auf eine Antwort warten anstatt zu “refusen” und das beschäftigt die Helper zu lange, sodass die nicht mit den Checks hinterher kommen.
Eine Prüfung z.B. auf einen offenen SSH-Port wäre ein valider Grund.
Das würde auch erklären, warum nach einem Neustart erstmal alles klappt
Und ich gehe mal davon aus, dass du hier kein Master-Slave Konstrukt hast?
Hallo @Kruzgoth,
auf dieser Site haben wir relativ viele SNMP-Abfragen.
Ich habe mir die Execution Time der SNMP-Checks mal stichprobenartig angeschaut, die langsamsten Abfragen haben eine Execution Time von 3 s, die meisten Abfragen laufen jedoch mit 0,2 bis 0,6 s.
TCP-Checks haben wir auf dieser Site nicht.
Mittlerweile ist mir aufgefallen, dass, nachdem ich die Anzahl der Helper verdoppelt habe, die Check_MK Helper Usage beim ersten pushen von changes von circa 50 % auf 80 - 90 % steigt und auch in diesem Bereich bleibt. Beim zweiten pushen von changes kommt es dann wieder zu dem Problem, dass die Usage auf 100 % steigt und die Services alle stale werden und bis zum Neustart der Site bleiben.
Was meinst du mit Master-Slave-Konstrukt? Diese Site ist im Distributed Monitoring mit Distributed WATO und dem Parameter “Slave:Push Configuration to this Site” angebunden.
Ich habe gesehen, dass es einen Debug Mode für die Helper gibt, kam aber noch nicht dazu, mich in diesen tiefer einzuarbeiten. Hast du Erfahrung damit?
viele SNMP-Abfragen mit 3s Timern könnten eventuell dein Problem erklären, aber hier kommt es simple gesagt auf die Vielzahl der Systeme an. Gehen wir von aus, dass jeder Helper (30) gerade per Zufall auf ein System treffen, die alle min. eine 3s Abfrage haben, dann verzögert sich die Verarbeitung aller restlichen Checks bereits um 3s. Und das stapelt sich natürlich hoch.
Mit dem Change kann ich mir nur erklären, dass halt während der Aktivierung neue theoretisch abzufragende Checks dazu kommen und dadurch die Helper total überfordert werden dem nachzukommen.
Und mit Master-Slave Konstrukt meine ich genau, dass du einen Master-Server hast, der die Konfiguration auf die Slaves pushed, halt über “Distributed Monitoring” und “Slave: Push Configuration to this Site”. Ich hoffe mal, du hast nicht deinen Master als Slave von sich selber gesetzt ,
ich weiß nicht ob das Probleme erzeugen könnte und will es auch nicht probieren
Solltest du aber ein Master-Slave Konstrukt haben, wollte ich nur fragen, ob du auch explizit die Helper für den Slave hoch gesetzt hast oder für alle. Solltest du nämlich den normal unter “WATO Configuration” → “Global Settings” die Helper erhöht haben, dein Slave hat aber über “Distributed Monitoring” → “Global Settings of Slave” explizite Werte für die Helper stehen, werden die nicht überschrieben daher meine Frage.
Danke für deine Antwort, @Kruzgoth!
Ich habe gerade noch weitere Systeme kontrolliert, ich habe nun insgesamt 4 gefunden, bei denen die Execution Time über 1 s lag. der Rest lag unter 0,6 s. Diese 4 gehören auch zu denen mit den meisten Services.
Was mich so wundert ist, dass das Problem erst seit kurzem auftritt, obwohl keine größere Anzahl an Hosts oder Services hinzugefügt wurde.
Ich habe das Pushen der Changes auch ohne das Hinzufügen von neuen Hosts oder Services getestet, indem ich einfach eine bedingungslose Notification Rule angelegt habe und diese an die Site gepusht habe, selbes Ergebnis.
Der Master ist natürlich nicht sein eigener Slave, es sind zwei unterschiedliche Sites
Die Helper habe ich explizit für die Site, die Probleme macht, unter Distributed Monitoring hoch gesetzt.
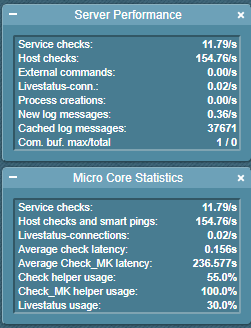
Was mir hier auch auffällt ist, dass die Verteilung für die “Latency” unterschiedlich ist:
Oben sind es die Check_MK-Service die in der langen Warteschlange stehen, unten sind es beide,
d.h. der hat unten nicht nur mit den “Check_MK” Servicen Probleme hinterher zu kommen, sondern auch mit scheinbaren active-Checks.
Hast du da welche aktiv? Oder hängen die Hosts hier auch hinterher?
Nach Erhöhen der Helper hat sich an den Zahlen hier nichts geändert?
Und was hier das Problem ist, meiner Meinung nach, ist nicht das Pushen mit Regeln oder Hosts, sondern generell das Pushen, weil dadurch der Core durchgestartet wird, was wiederum all Helper zum Zeitpunkt stoppt. Anschließend muss der Core erstmal wieder alles laden und dadurch steigt deine vorhandene Last nur, da die leider nicht hinterher kommen.
So meine Interpretation!
Was mich generell wundert ist, dass die komplette checkmk Latenz sehr hoch ist. Eventuell ist hier die Ursache zu suchen, dass die Helper dann auch am Anschlag arbeiten. Wie sieht denn die RAM-Auslastung deines Servers aus? Jeder Helper benötigt ca. 60MB. Swapt dein System vielleicht, das könnte eine hohe Latenz erklären.
Die RAM-Auslastung sieht gut aus (die CPU-Auslastung auch) und das System scheint nicht zu swappen.
Interessanterweise tritt das Problem nicht mehr auf, seit ich den Debug Mode für die Helper aktiviert habe. Die Helper Usage steigt beim Pushen von Changes nicht mehr merklich an. Auch die Latenz ist niedriger als vorher.
 ,
,
 daher meine Frage.
daher meine Frage.