Please apologize for the mistake, indeed I doesn’t recognized that its another user.
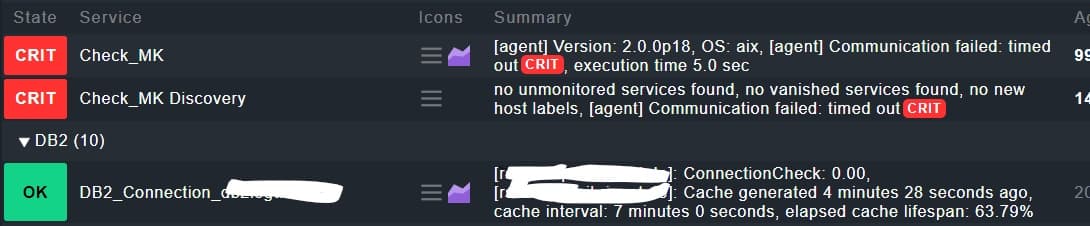
We have exactly same Situation with DB2 on AIX HACMP. What I can definitely say is that DB2 checks are not cluster aware in 1.6. We didnt tested in 2.0 but I am sure that they still run the same code as in 1.6 for DB2. Because of that we did a complete rework of the DB2 plugin and checks.
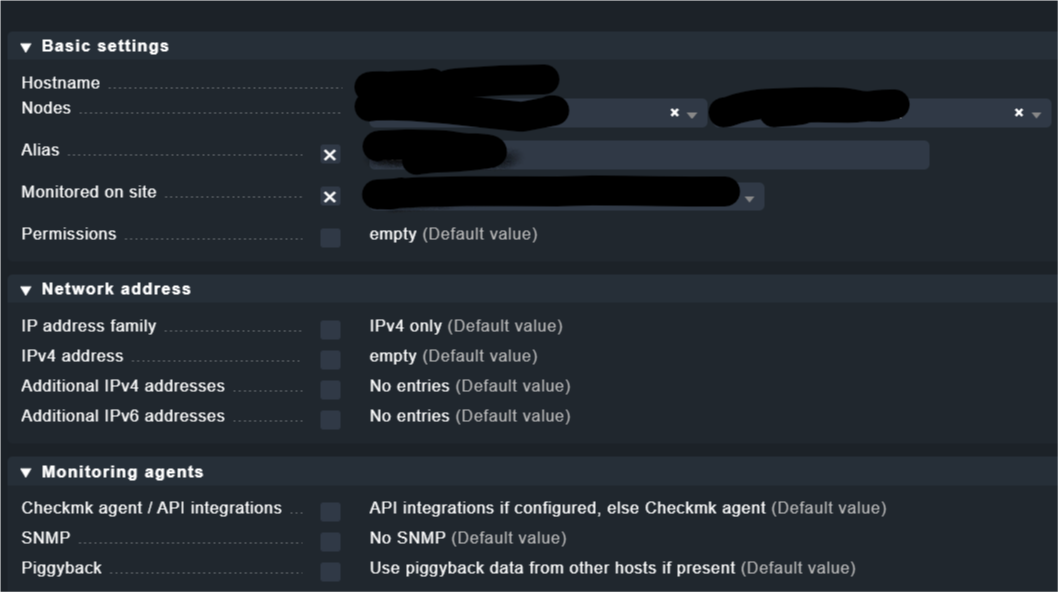
Our configuration looks like that. Maybe you can compare.
OMD[master]:~$ cmk -D DB2RC4
DB2RC4 (cluster of nodea, nodeb)
Addresses: 10.20.30.40
Tags: [address_family:ip-v4-only], [agent:cmk-agent], [aix:aix], [criticality:prod], [hosttype:aix_vm], [ip-v4:ip-v4], [networking:lan], [piggyback:auto-piggyback], [site:master], [snmp_ds:no-snmp], [tcp:tcp]
Agent mode: Normal Checkmk agent, or special agent if configured
OMD[master]:~$ cmk -D nodea
nodea
Addresses: 10.20.30.41
Tags: [address_family:ip-v4-only], [agent:cmk-agent], [aix:aix], [application:db2], [criticality:prod], [hosttype:aix_vm], [ip-v4:ip-v4], [networking:lan], [piggyback:auto-piggyback], [site:master], [snmp_ds:no-snmp], [tcp:tcp]
Agent mode: Normal Checkmk agent, or special agent if configured
OMD[master]:~$ cmk -D nodeb
nodeb
Addresses: 10.20.30.42
Tags: [address_family:ip-v4-only], [agent:cmk-agent], [aix:aix], [application:db2], [criticality:prod], [hosttype:aix_vm], [ip-v4:ip-v4], [networking:lan], [piggyback:auto-piggyback], [site:master], [snmp_ds:no-snmp], [tcp:tcp]
Agent mode: Normal Checkmk agent, or special agent if configured
regards
Michael