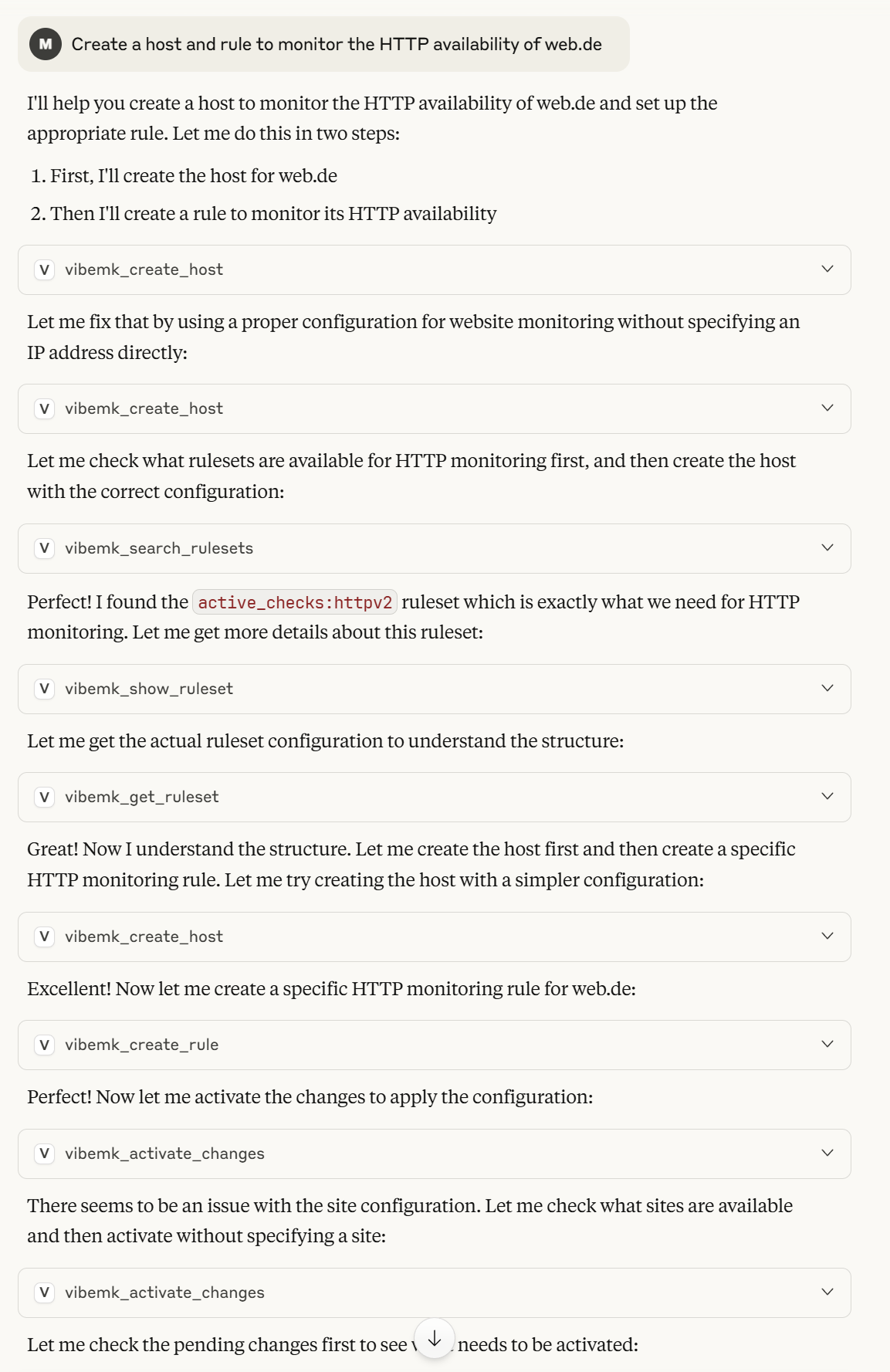
I have been vibecoding over the last few nights and created a new tool called vibeMK, an MCP server that connects your checkmk with your AI / LLM. It has currently been tested with Claude Desktop but should/might also work with others. It is open source (GPLv3), contributions welcome.
With vibeMK, you can now perform tasks in checkmk using natural language in your AI.
An already working example:
Can you please create the user johndoe with a random password in checkmk?
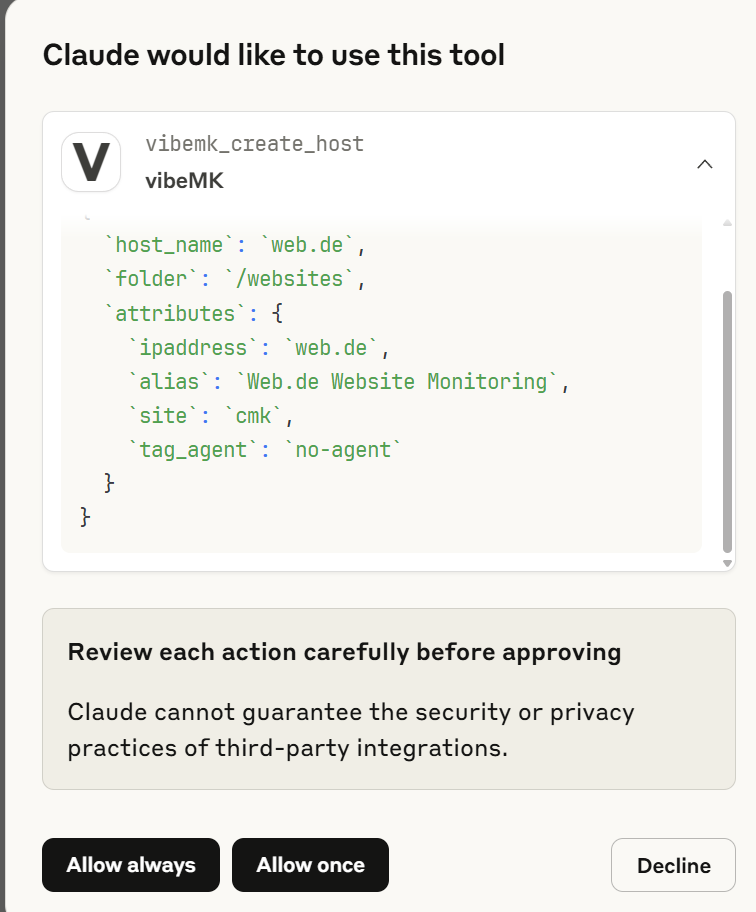
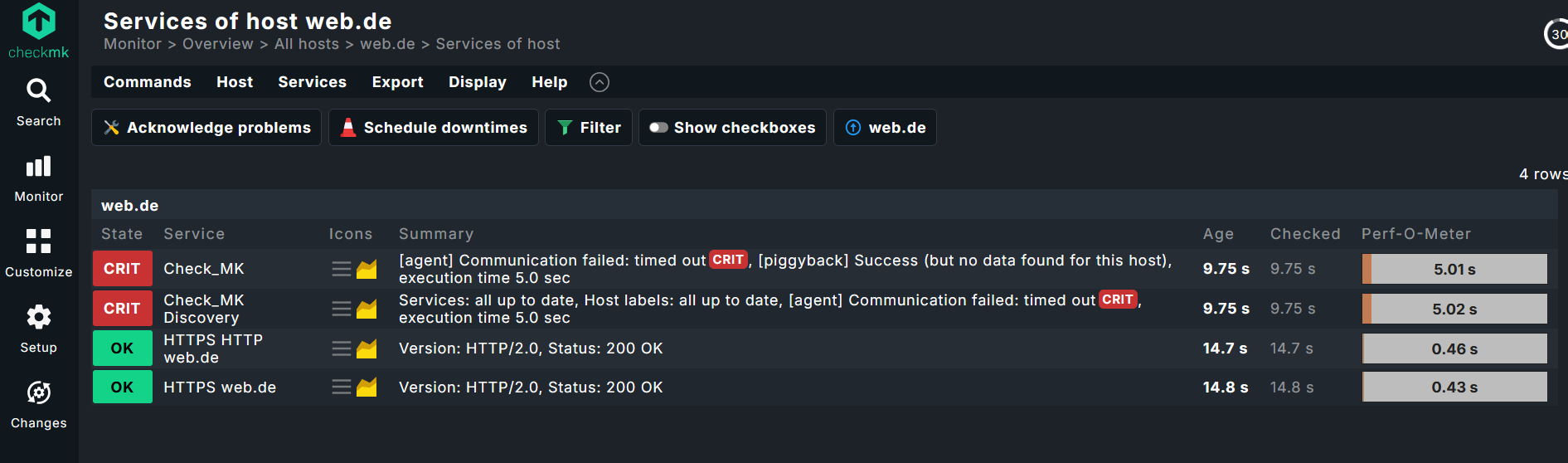
Then create a host called myshinyserver with the IP address 192.168.211.12.
Also, please create a contact group called server-admins and assign the user johndoe to the new contact group.
Finally, please create a folder called servers in the top-level directory and activate the changes at the end.
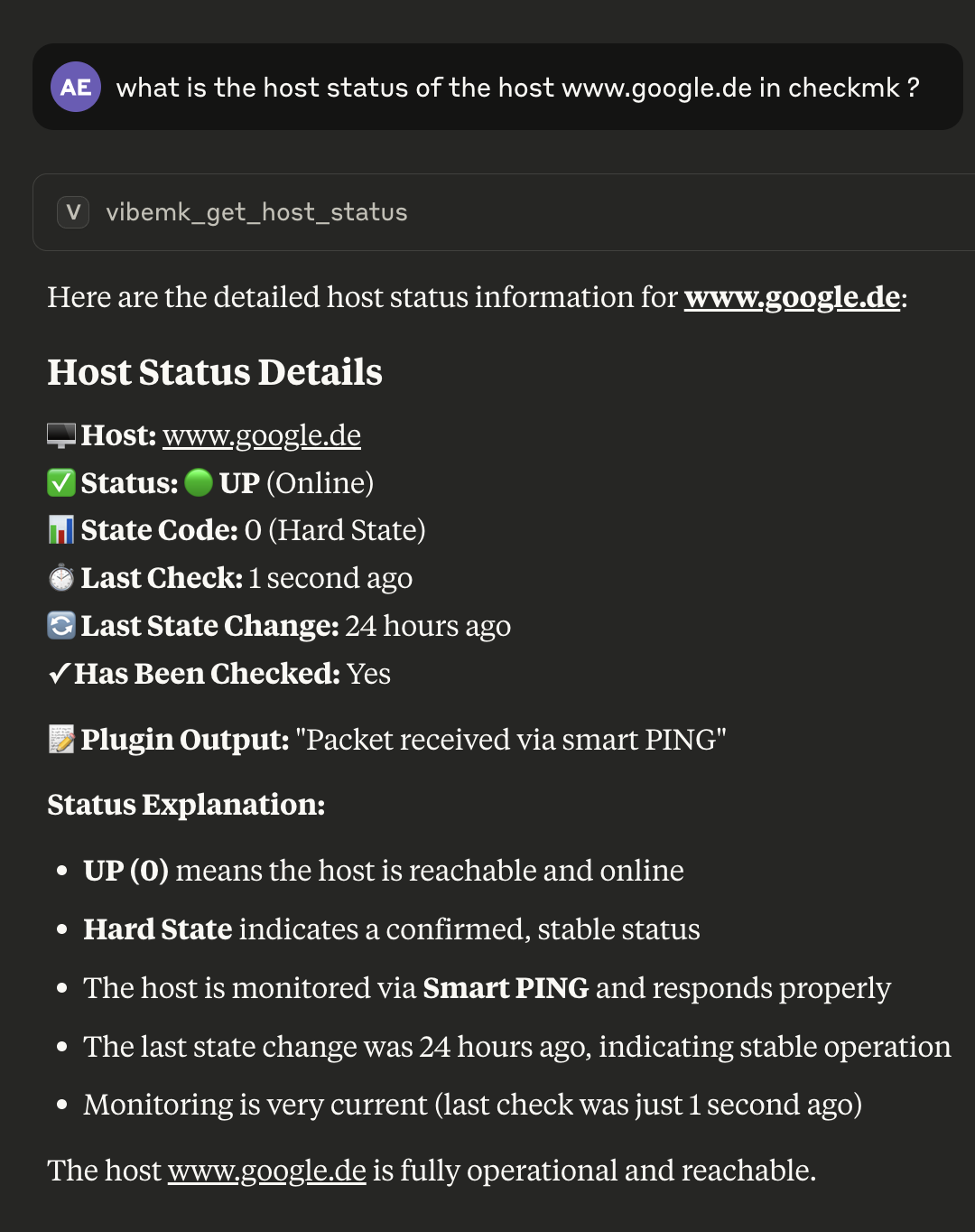
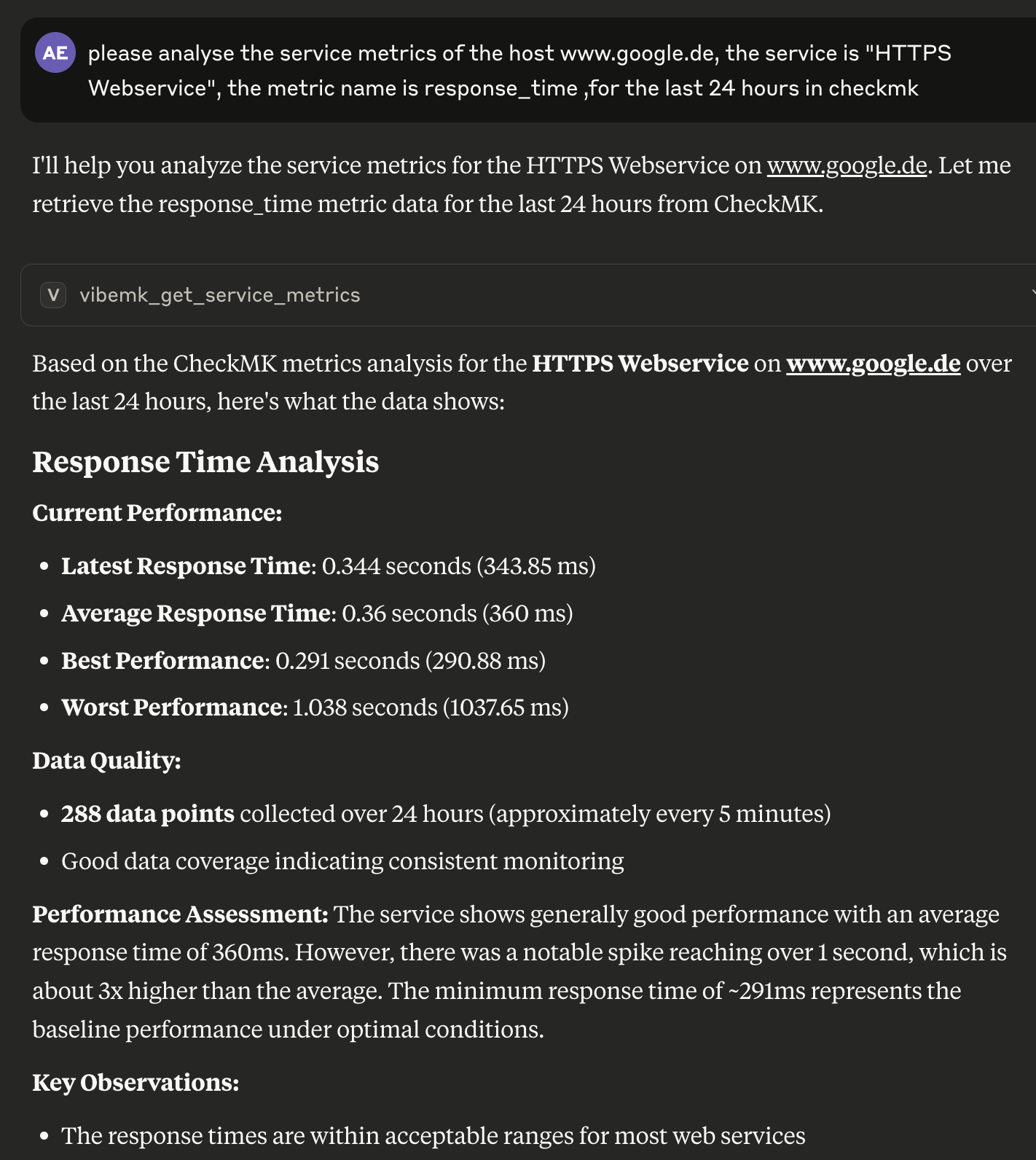
After that, I need the host status of the host xyz and the service status of the “HTTPS Webservice” service of the host mywebserver.
Disclaimer:
Im not a software developer, the current software status of this project is alpha, and I wrote it as a technical demonstration, not as a feature complete solution.
The final goal is to support every feature that checkmk offers via the REST API.
There are already many working features, but during testing I limited myself to the important core checkmk functions. More will follow in the coming weeks.
There are several things you should be aware of before using the software:
Do not use in production
Be aware of the security risks when you unleash AI on your checkmk
Act responsibly and consider power consumption
Do not hold me responsible for issues on your checkmk site
Use at your own risk
Having said that, I can only express how impressed I am with what is currently possible with this combination of an LLM and checkmk (after two days of “development” ) and I think there will be a lot usecases where this might be really useful, e.g. analysing historical data, checking best practices, repeating tasks and so on.
You create handlers for the specific Rest Api endpoints in the MCP Server, so that it knows the necessary data format for the request, as soon as all handlers are implemented correctly, the amount of requests should be exactly as high as necessary for the task you want to achieve.
Im currently testing and extending the handlers.
The project is really just two days old, so I was not able to do more testing than i described above.
If you have ideas, recommendations or find problems just hit me up or create a PR.
My short term next steps in the coming days will be to make sure, that the important API Endpoints work (everything you would expect from a configuration and simple analysis point of view).
After that i’m definetly interested in extending the code, to provide the foundation for more complex setup, analysis or configuration tasks.
This is a test, because I was curious, what is possible after I learned about the MCP protocol, i will not force anybody to use it and I really understand everyone who has concerns. (I also have these)
If you need deterministic behaviour in production ,you are able to only use it in an analysis mode with a read only user and can benefit from metric or ruleset analysis.
We see quite good adoption of our chatbot (chat.checkmk.com). It is especially for new users a big help and we have received direct positive feedback from new users.
I see great potential for analysis and for new users for such a analysis/config integration.
I like that I can actually see what it does (and in this case even put it in the right folder)
It didn’t recognize that there was already a rule, but this can all be improved with right context (e.g. always check if a similar rule could be extended).
I really thank you Andre. As we are currently working on AI initiatives at Checkmk itself (focusing more on how to make development faster and support better), this is great input and this is motivation that maybe we can get something like this available for users rather earlier than later.
This really a cool feature. Can you explain what data is sent to Claude in this process ? I’ve tried this with a local llm (llama3.2:3b) but it takes eons to get a response, and in most cases its not that accurate. Did someone tried this with a diferent llm that can share insights ?