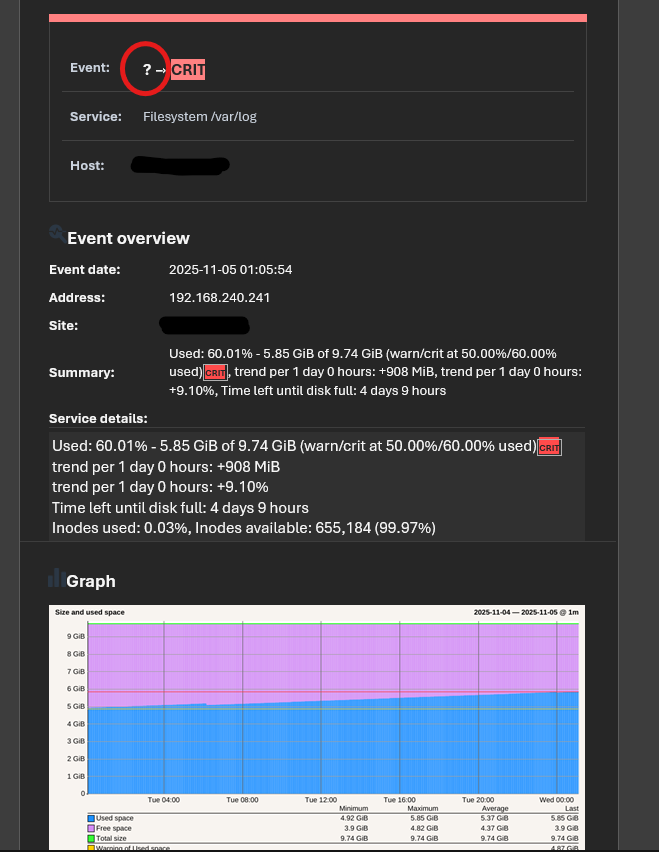
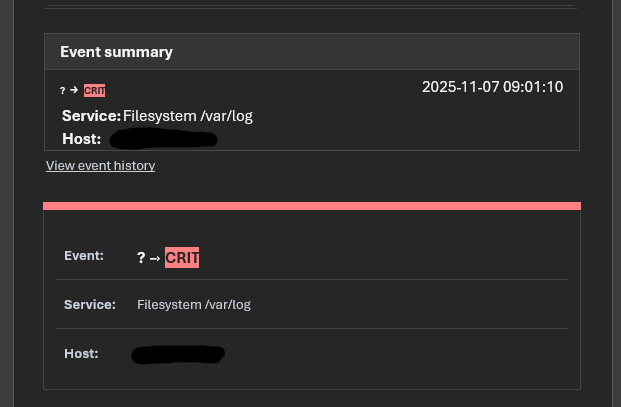
This service check isn’t new, as you can see in the graph. I’m not sure what to investigate to resolve this issue. All I can say is that I’ve been experiencing this problem since upgrading to version 2.4, and edit the option `maximum number of check attempts for service from 1 to 3.
here is the log from notify.log :
2025-11-05 01:05:56,046 [20] [cmk.base.events] Previous service hard state not known. Allowing all states.
i have this problem on mutiple instances of checkmk running at the same version and config, and the problem appears for the same service check : filesystem /var/log
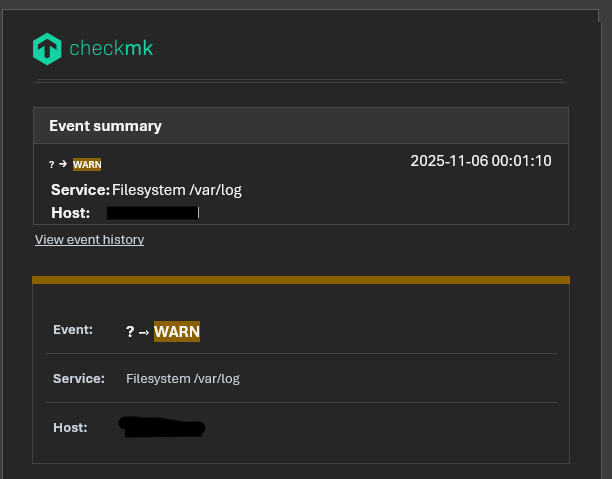
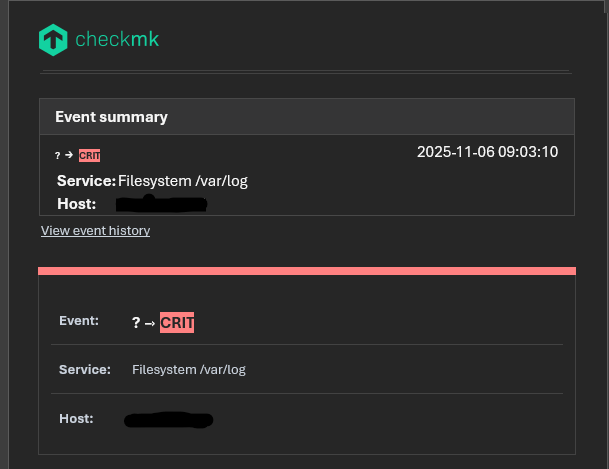
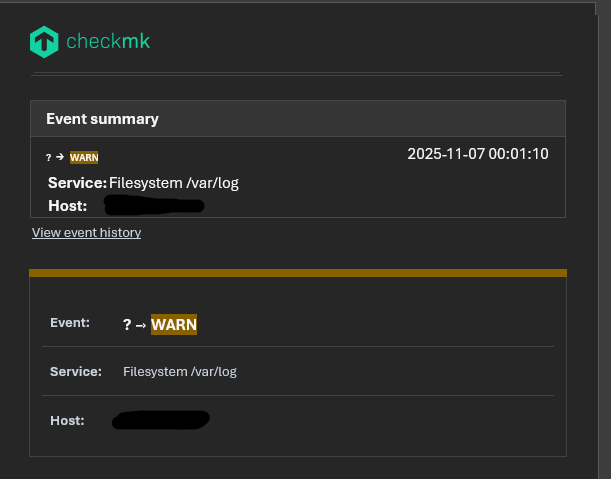
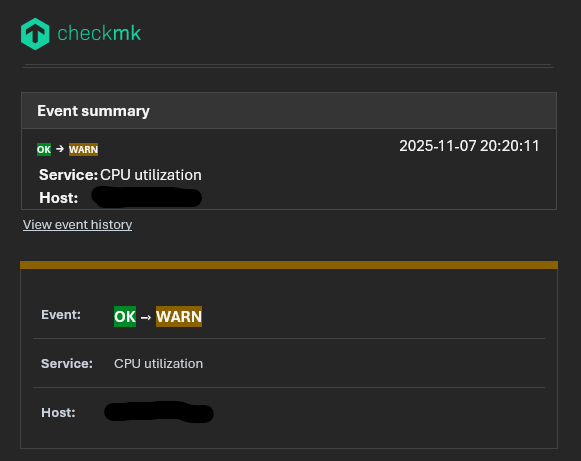
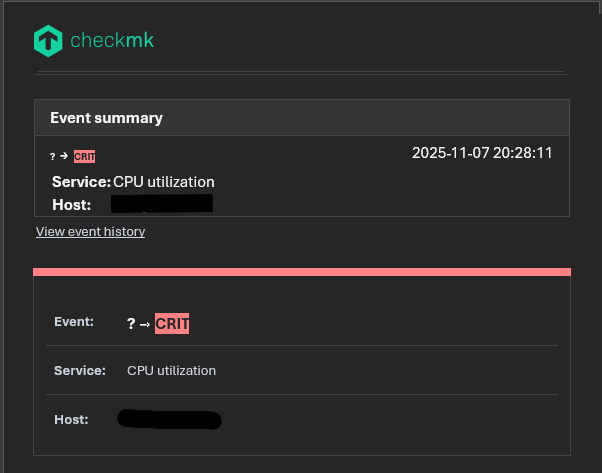
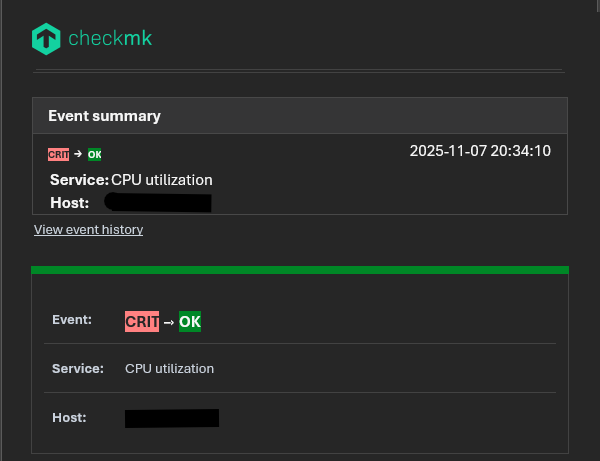
These are all the notifications from the last two days on the same host.
The service goes critical at 9 a.m., then changes from critical to warning at 12 p.m. due to log rotation. I don’t understand why Checkmk is unable to retrieve the previous status.
The file is the nagios state file that it saved at clean restarts, log file rollover and from time to time.
At this times a complete state dump happens for all hosts and services. If it is a hard state then his is normally the hard state used by the system.
The configuration of this behavior is done inside the “retention.cfg” file. But if no one touched it before it should have the right configuration entries.
What also can happen is that the state changed from OK –> WARN –> CRIT but had no hard state at WARN that then at the notification for CRIT you don’t get a hard state. Also if the service was flapping before it can happen i think.
Bingo, I can confirm that this is indeed the problem.
Let me summarize the situation:
when maximum number of check attempts for service is set higher than 1, I am able to reproduce this issue on any instance (using version 2.4; I haven’t tested older versions yet).
For services with warning and critical thresholds, if the state switches from OK → WARN → CRITICAL without having a HARD state recorded for each, this problem occurs.
However, is this the intended behavior? In my opinion, the notification should show OK → CRIT, i.e., displaying the last two known HARD states.
I checked on one of my RAW systems and there i saw that the whole problem with the last hard state is a little bit more complicated as the value is calculated inside the notification system. The Nagios core directly does not report such a value.
The CMC core does send this macros directly. For Nagios they are calculated in this function here.
if (
enriched_context["WHAT"] == "SERVICE"
and "PREVIOUSSERVICEHARDSTATE" not in enriched_context
):
prev_state = enriched_context["LASTSERVICESTATE"]
if prev_state == enriched_context["SERVICESTATE"]:
prev_state = "OK"
elif "SERVICEATTEMPT" not in enriched_context or (
"SERVICEATTEMPT" in enriched_context and enriched_context["SERVICEATTEMPT"] != "1"
):
if raw_context["SERVICESTATE"] != "OK":
prev_state = "?"
logger.info("Previous service hard state not known. Allowing all states.")
enriched_context["PREVIOUSSERVICEHARDSTATE"] = prev_state
And here i see already the bug for the ? (UNKN) service state.
The code part the sets the prev_state to ? makes no sense. But the problem is that the Nagios core does not sent any information about the last state if you use multiple check attempts. Here it is better to sent directly at the first attempt and then use the “delay service notification” rule to define a time like it was done before with the check attempts.
So if I understand correctly, it is better to configure “delay service notification” instead of using check attempts with soft states?
I could test this, but in that case it makes this feature useless from my point of view. In which situations is it better to use delay service notification rather than check attempts?
Normally i would prefer the check attempts as i can also filter dashboards and views for hard and soft state with this method.
But for your use case the delay service notification is better.
In the end i would prefer here some other approach - change the code to something else than the “?”. Something like if it is now critical you select automatically warn as source state or if it is warn you select ok as previous state.