CMK version:
2.2.0p14
OS version:
RHEL8
Error message:
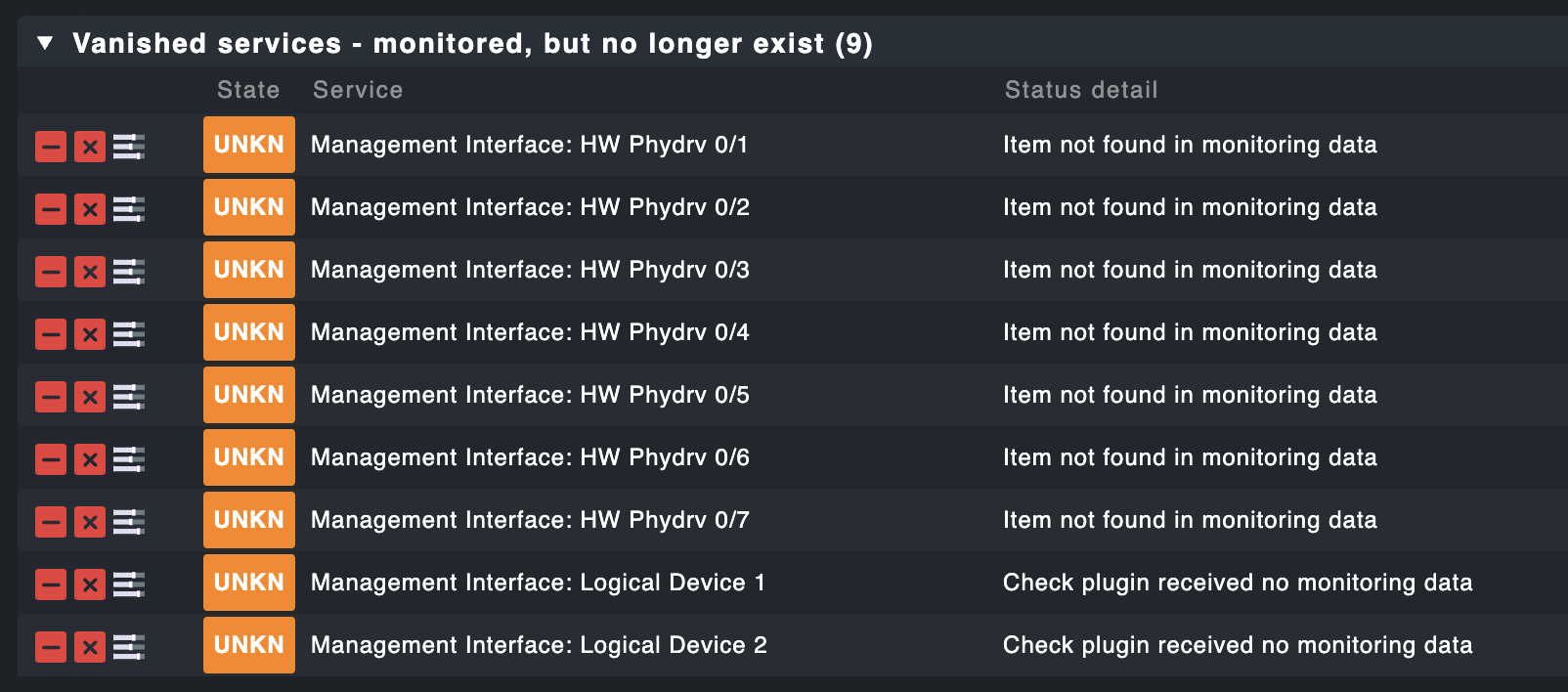
None, the services for all storage devices disappear.
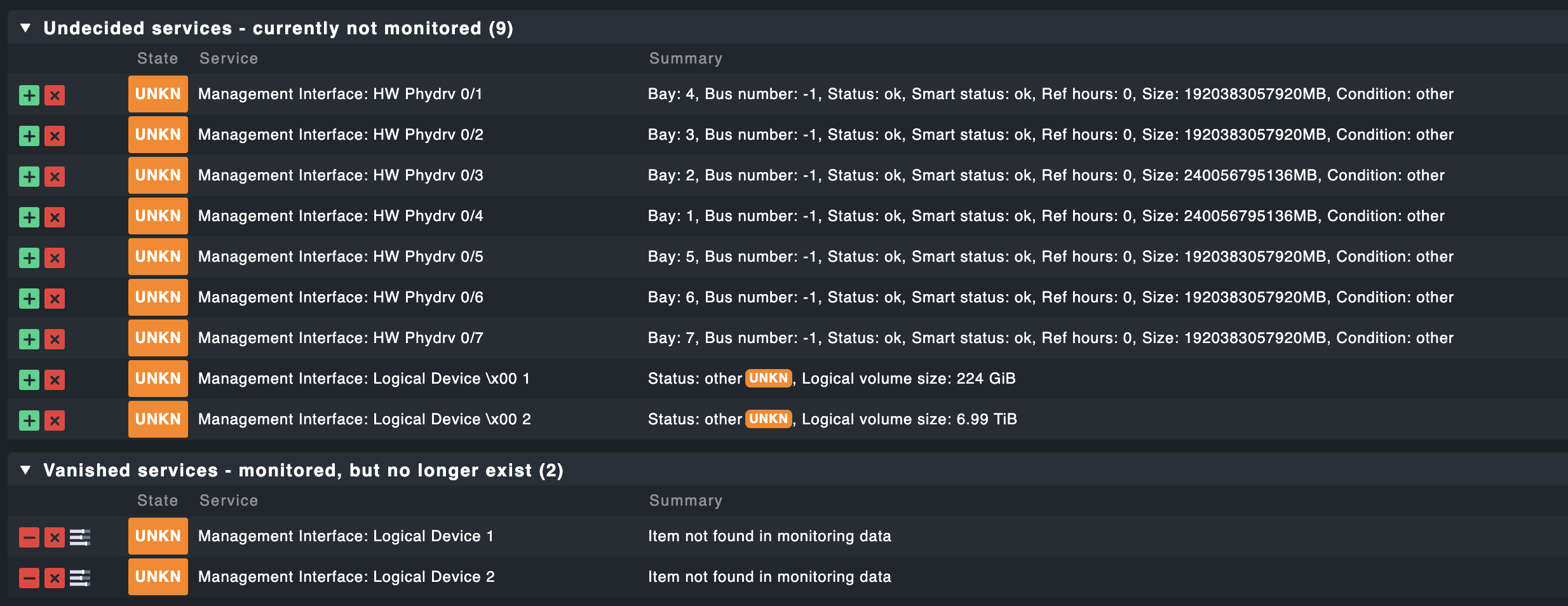
Output of “cmk --debug -vvn hostname”: (If it is a problem with checks or plugins)
I guess the important part is:
Management Interface: HW Phydrv 0/1 Bay: 4, Bus number: -1, Status: ok, Smart status: ok, Ref hours: 0, Size: 1920383057920MB, Condition: other
Management Interface: HW Phydrv 0/2 Bay: 3, Bus number: -1, Status: ok, Smart status: ok, Ref hours: 0, Size: 1920383057920MB, Condition: other
Management Interface: HW Phydrv 0/3 Bay: 2, Bus number: -1, Status: ok, Smart status: ok, Ref hours: 0, Size: 240056795136MB, Condition: other
Management Interface: HW Phydrv 0/4 Bay: 1, Bus number: -1, Status: ok, Smart status: ok, Ref hours: 0, Size: 240056795136MB, Condition: other
Management Interface: HW Phydrv 0/5 Bay: 5, Bus number: -1, Status: ok, Smart status: ok, Ref hours: 0, Size: 1920383057920MB, Condition: other
Management Interface: HW Phydrv 0/6 Bay: 6, Bus number: -1, Status: ok, Smart status: ok, Ref hours: 0, Size: 1920383057920MB, Condition: other
Management Interface: HW Phydrv 0/7 Bay: 7, Bus number: -1, Status: ok, Smart status: ok, Ref hours: 0, Size: 1920383057920MB, Condition: other
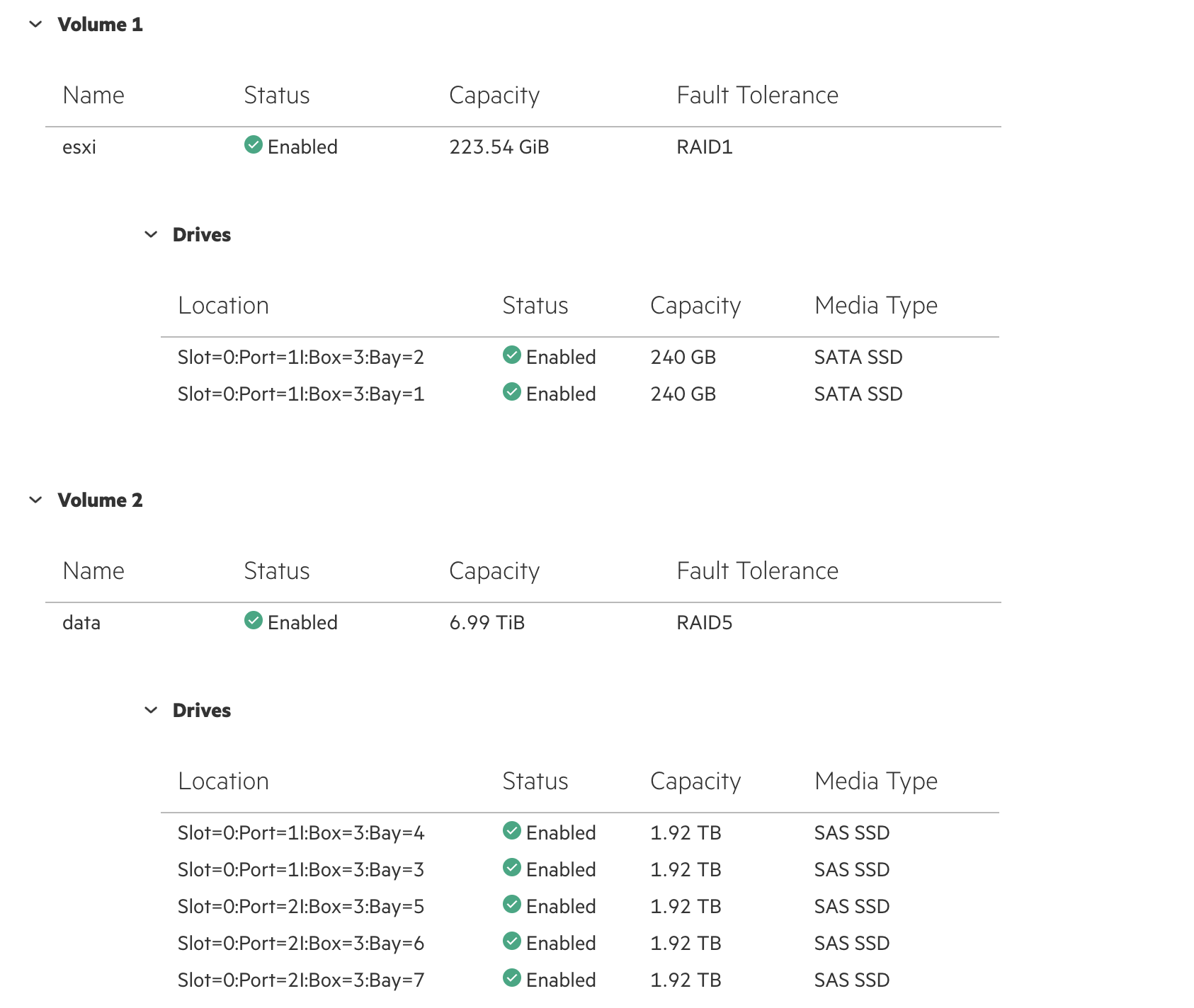
Management Interface: Logical Device 1 Status: other(?), Logical volume size: 224 GiB
Management Interface: Logical Device 2 Status: other(?), Logical volume size: 6.99 TiB
We flashed the iLO firmware to Integrated Lights-Out 5 3.00 (Dec 14 2023), from Integrated Lights-Out 5 2.97.
I’m guessing something has changed in the SNMP output in version 3.00, I’m just looking for the exact OIDs to check…