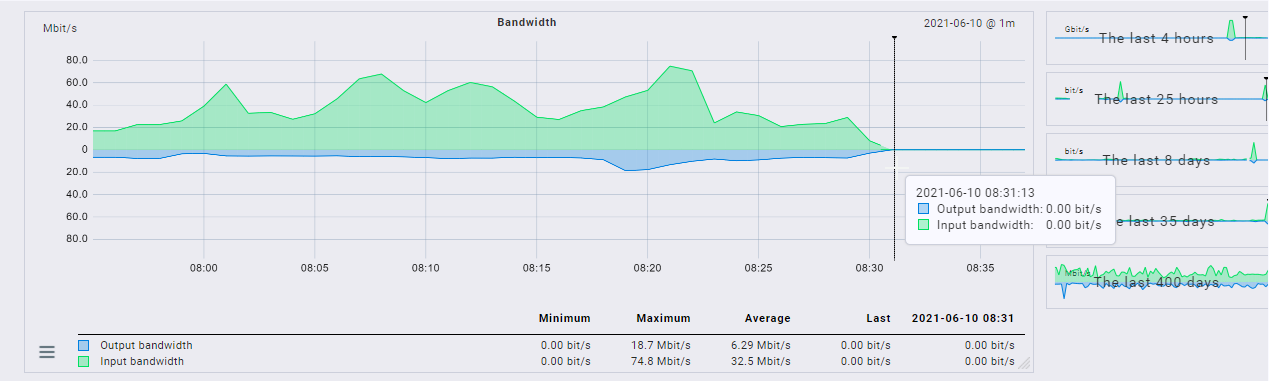
Hallo, habe heute unser Checkmk von 1.6.0p24 auf 2.0.0p5 aktualisiert und seit dem werden die Performance Daten der Interfaces von unseren Switches und Firewalls nicht mehr richtig gelesen:
Wenn ich cmk -nv host ausführe werden Daten angezeigt, mit cmk -v host sind auch die Daten in der GUI ersichtlich aber danach gleich wieder auf 0.
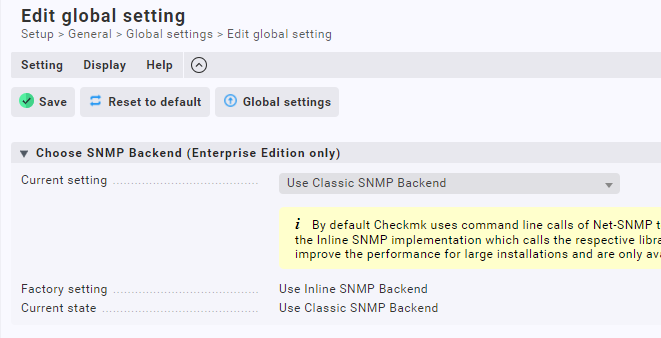
Habe nun hier
auf classic backend umgestellt und jetzt werden die interface speeds wieder richtig angezeigt?
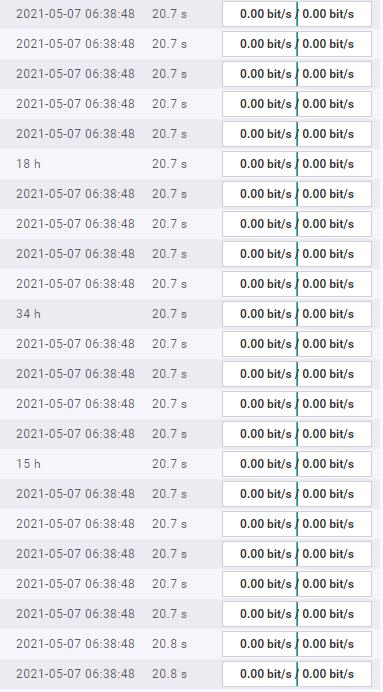
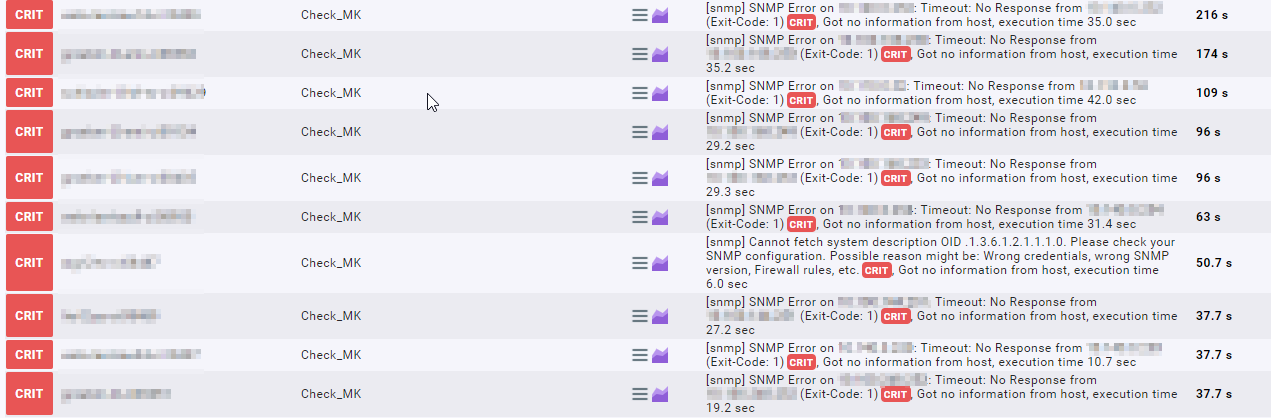
dafür gibts bei sehr vielen geräten ein Timeout
Das ist aber auch verdächtig. Warum gibt es Timeout wie schaut die Last auf dem Monitoringserver aus. Die Abfrage egal ob per Classic SNMP oder Inline SNMP selbst sollte nicht sehr unterschiedlich sein von der Zeit her. Nur Inline belastet halt den Monitoringhost weniger wie Classic SNMP.
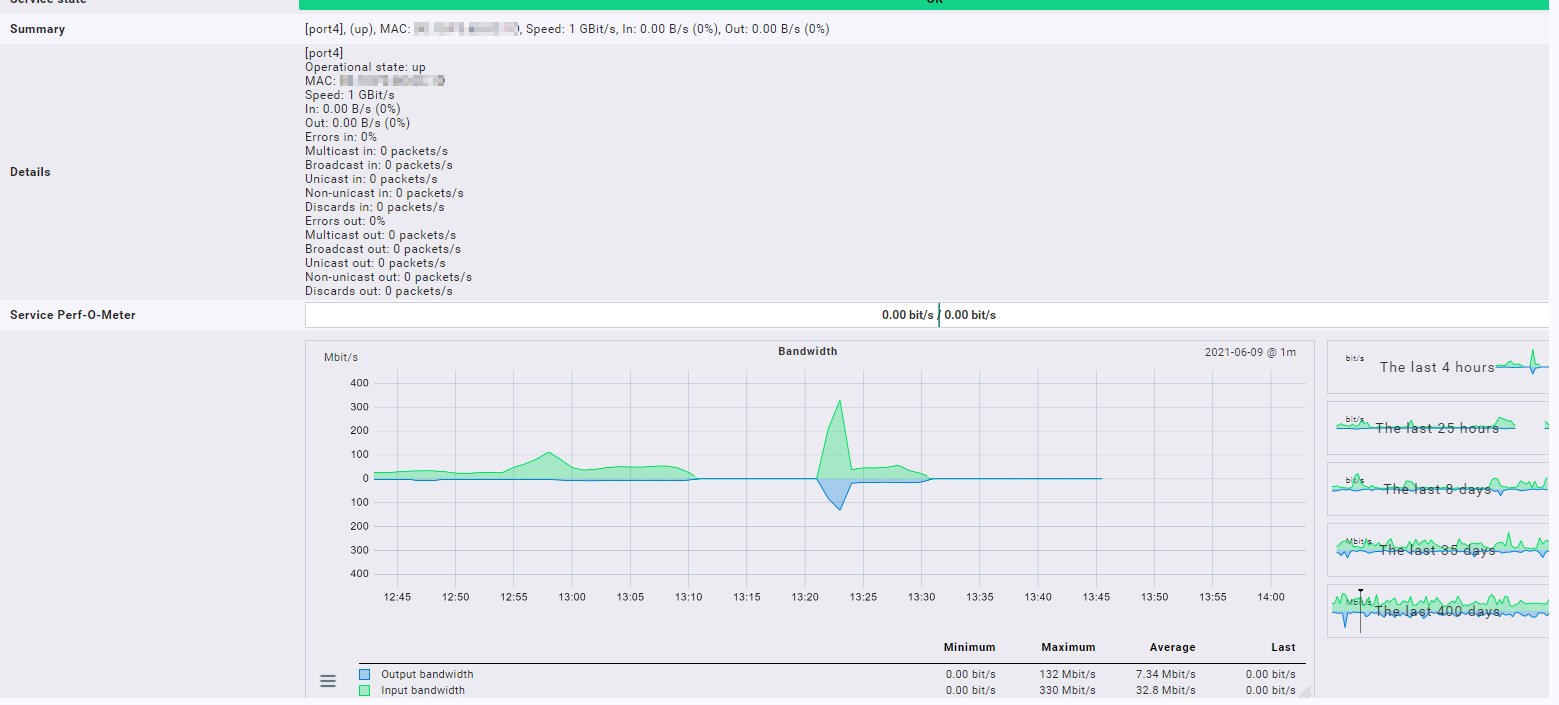
Zu der ersten Grafik das sieht mir eher so aus wie wenn die Checks gar nicht richtig ausgeführt werden oder in einem zu langen Abstand. Sicher das hier if64 benutzt wird?
Was sagt ein rediscovery eines betroffenen Switches auf der Command Line mittels “cmk --debug -vvII hostname”?
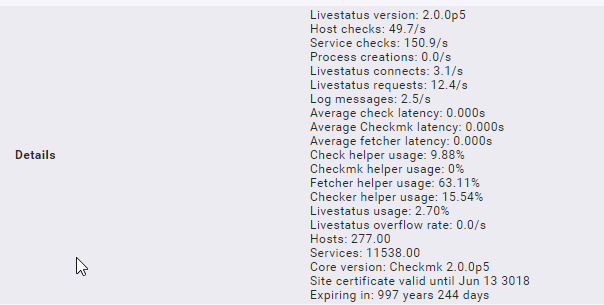
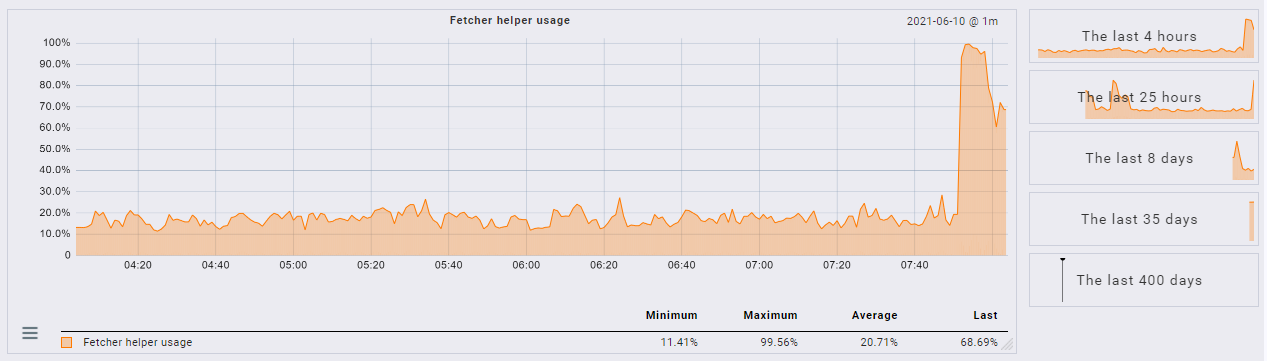
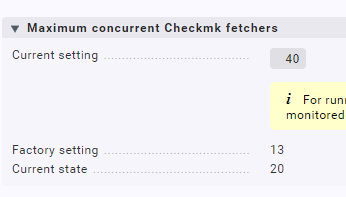
Hab um 7:51 das Backend wieder auf Classic umgestellt, dann war die fetcher usage auf 100%. Danach habe ich die Anzahl der Fetcher von 13 auf 40 erhöht, dann wars besser:
Da ist irgendwas auf dem System kaputt. Wenn die Performance Daten erstmal ordentlich erzeugt werden und dann auf einmal alles 0 ist muss was kaputt sein dort wo CMK sich merkt was bisher geschah. Also dort wo die Counter liegen im ~/tmp.
Ist da alles ok oder läuft da was voll?
Die Timeouts sehen auch sehr seltsam aus. Wie gesagt das System selbst hat irgendwo ein Problem.
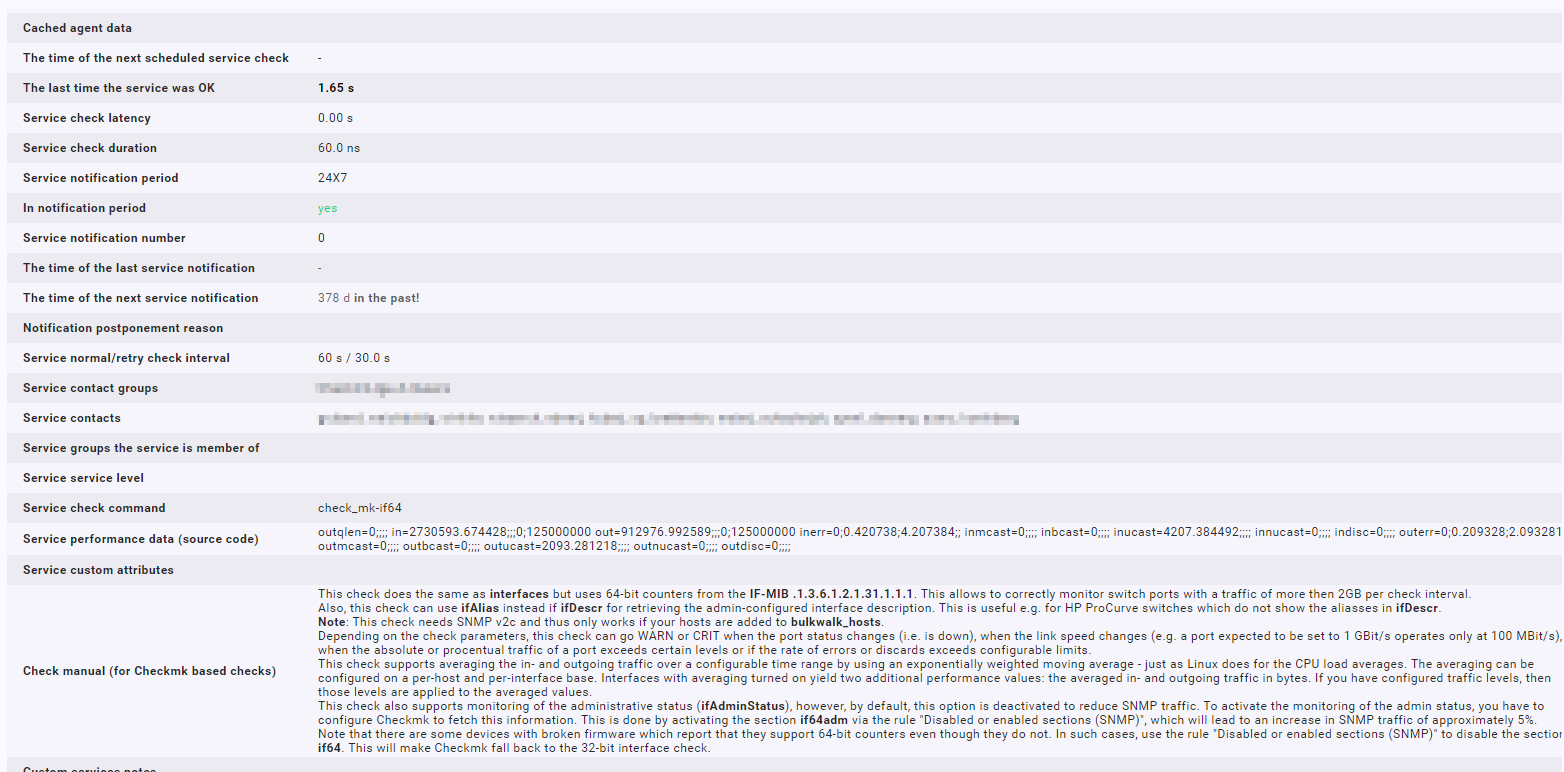
Wie sehen den die Metriken des Checkmk Service aus? Wir haben den Verdacht, dass hier irrtümlich Daten aus dem Cache gelesen werden. (Das würde bedeuten: Alle Raten sind null – weil sich nichts ändert)
Wir arbeiten da sehr intesiv daran. Manchmal hilft ein Core restart, oder das löschen der Caches. Wir wissen im Moment leider noch nicht, was das Verhalten triggert.
Ich habe auch das Problem. Keine Änderung von Einstellungen check/timeout/inline-snmp o.ä. haben Einfluss auf das Problem. Nur Änderungen an einem Host (z.B. invertarisieren) bewirkt, dass sofort alle Host wieder Daten der Interface liefern. Diese sind dann stark summiert. Ein Uplink-Port mit durchschnittlich 10 MBit zeigt dann 700 Mbit an, hat nach 10 Minuten 10 MBit und nach einigen Stunden wieder 0. So als wenn die Daten nicht kontinuierlich geschrieben werden.
Alle anderen Daten im Check wie CPU o.ä. sind korrekt.
Interface der Windows/Linux-host mit Checkmk-Agent sind auch korrekt.
Das kann ich gerade nach einem Check bestätigen. Dort trat das Problem immer genau 0 Uhr auf und sobald wie gerade eben eine Änderung irgendeiner Art vorgenommen wurde ist das Problem wieder weg.
Konnte das hier mittels der Graphen dreimal 0 Uhr immer festmachen.
Betroffen sind nicht alle Interface Checks. In dem System waren die folgenden vorhanden.
winperf_if - ok
vsphere_counters_if - ok
lnx_if - ok
wenn Interface-Daten immer im Wechsel korrekt und beim nächsten Check wieder 0 sind, kann es daran liegen, dass z.B. 1 Minute Check-Interval eingestellt ist, aber in den Settings für SNMP-Checks 2 Minuten eingestellt ist. Bei den Interface-Metriken handelt es sich um kumulierte Werte, die checkmk immer mit dem vorherigen Wert vergleichen muss, um den aktuellen Durchsatz zu berechnen. Wenn das Check-Intervall kleiner ist, als das SNMP-Intervall, dann wird der letzte Wert im Cache mit sich selbst verglichen, so dass die Änderung immer 0 ist.
Bin nicht sicher, ob das hier auf dieses Fehlerbild passt, aber hatte dieses Thema in 1.6.0p16 mal. Denkbar wäre, dass bei einem Upgrade von 1.6.x auf 2.0.x ggf. Intervalle auf Default-Werte gesetzt werden, so dass die Einstellungen nicht mehr zusammenpassen.
In meinem Fall war es damals eine manuelle Konfiguration, durch die Check-Intervall und SNMP-Intervall nicht mehr zusammengepasst hatten.
Vielleicht geht das Problem ja auch hier in diese Richtung.
Das hat mit dem Fehler hier nix zu tun. Das Verhalten ist halt recht sporadisch. Es läuft erstmal alles normal und ab Zeitpunkt X werden alle Werte nur noch 0. Dann nach aktivieren einer Änderung ist wieder alles schick bis es wieder passiert.
Ja wie gesagt. Die Einstellungen habe ich vermutlich alle getestet. Durch unterschiedliche Regeln auf unterschiedliche Host oder Interface (Services) sollte ja mal ein Interface anders reagieren.
Die Interface reagieren aber alle gleich.
Ich habe z.B. auch mal (mit den deutschen “genauen” Bezeichnungen), sowas getestet wie…
Abrufintervalle für SNMP-Abschnitte = 4 Minuten
Normales Intervall für Service-Checks = 5 Minuten
Servicecheck Timeout (Microcore) = 3 Minuten
Oder gibt es noch andere Einstellungen, außerhalb der Regeln?