I just updated my monitor to version
OMD[office]:~/etc/nagios$ omd version
OMD - Open Monitoring Distribution Version 1.6.0p11.cre
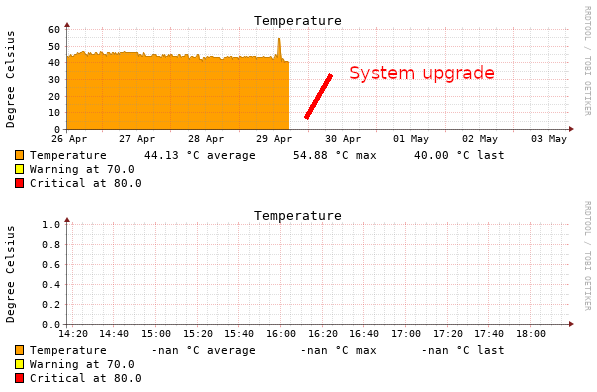
And since then I get flooded with emails about high temperature.
Output: CRIT - 83.0 °C (warn/crit at 70.0/80.0 °C)
Perfdata: temp=83;70;80;;
I checked the services and it shows, that there is a system load above 4 constantly. I stopped omd and the load went down below 1. Why is npcd causing so much load on the system and how can I stop it from frying my CPU (it goes over 80°C)?
top 5 minutes after restarting omd:
top - 18:11:18 up 4 days, 1:09, 1 user, load average: 4.96, 4.45, 3.93
Tasks: 162 total, 6 running, 155 sleeping, 0 stopped, 1 zombie
%Cpu(s): 0.0 us, 6.5 sy, 45.9 ni, 47.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 15862.7 total, 13327.2 free, 697.1 used, 1838.4 buff/cache
MiB Swap: 16201.0 total, 16201.0 free, 0.0 used. 14667.7 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
25263 office 39 19 372864 3548 1804 S 5.0 0.0 0:43.03 npcd
My system is a Debian 10 with 8 cores:
OMD[office]:~/etc/nagios$ uname -a
Linux server 4.19.0-8-amd64 #1 SMP Debian 4.19.98-1+deb10u1 (2020-04-27) x86_64 GNU/Linux
The system ran for more than a year now and never experienced issues like this.
Additionally the temperature graph shows NaN since the latest update: